







STL 算法的重要性
一、简介
STL 算法是一套强大的工具,可以提高代码的可读性和正确性。了解 STL 算法至关重要,因为它们可以极大地简化日常的编程任务。
这篇文章将介绍如何使用 STL 算法,并解释它们能带来的一些关键优势。通过学习 STL 算法,开发者可以编写更加表达性和健壮的代码。
二、算法 vs. for 循环
示例:
for (std::vector<company::salesForce::Employee>::const_iterator it = employees.begin(); it != employees.end(); ++it)
{
employeeRegister.push_back(*it);
}
大多数开发者扫描这段代码,得到这段代码的功能:这段代码将一个集合中的元素复制到一个名为 employeeRegister 的容器中。
继续,看这段代码:
std::copy(employees.begin(), employees.end(), std::back_inserter(employeeRegister));
即使不知道 std::back_inserter 的含义,也能立即明白这段代码是将 employees 复制到一个容器中,因为代码本身已经说明了:copy即复制的意思。在这个简单的例子中,代码功能差异并不大,但当将它乘以代码库中的行数,并考虑更复杂的用例时,这将严重影响代码的可读性。
std::copy 是 STL 中的一个算法,可以通过包含 <algorithm> 头文件来使用。这种 STL 的使用为明确地说明执行的操作奠定了基础。
基本上,STL 算法说明了它们做什么,而不是它们如何做。
2.1、std::copy 和 std::back_inserter
如果理解上面的代码是进行复制,但还不知道 std::copy 和 std::back_inserter 的细节,现在深入研究一下。这很重要,因为它非常常见。
std::copy 接收三个迭代器作为输入:
- 输入范围的开始和结束,包含要复制的元素;
- 输出范围的开始,复制后的元素将被放置在此处。
函数原型:
template <typename InputIterator, typename OutputIterator>
OutputIterator copy(InputIterator first, InputIterator last, OutputIterator out);
在 STL 中,一个范围的开始是一个指向其第一个元素的迭代器,一个范围的结束是一个指向其最后一个元素之后的迭代器:
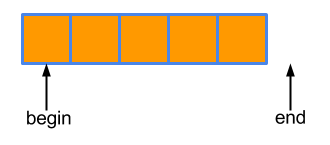
std::copy 的输出迭代器是元素将被复制到的范围的开始。
std::copy 遍历输入范围,并将所有元素依次复制到以 out 迭代器开头的范围:
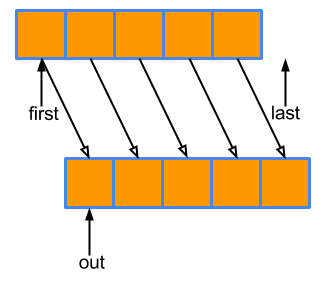
如上图所示,std::copy 需要在输出集合中有一些空间来存放从输入中复制的所有元素。然而,大多数情况下,提前计算输出集合中应该分配多少空间并调整其大小是不切实际的。
这就是 std::back_inserter 发挥作用的地方。std::back_inserter 创建一个与它传递的容器相连接的迭代器。当写入这个迭代器时,它实际上会调用该容器的 push_back 方法,并将试图写入的值作为参数传递。这有效地减轻了程序员的负担,如果使用的是一个vector,就不需要调整输出集合的大小,因为输出迭代器会直接在每次 std::copy 写入它时分配空间。
因此,使用 std::copy 的代码可以这样写:
std::copy(employees.begin(), employees.end(), std::back_inserter(employeeRegister));
这是标准的 C++ 代码。这是该语言在本文撰写时(小于 C++17)提供的原生功能;当然了,范围(Ranges)的概念可以更进一步提高可读性。
三、使用算法的优势
算法带来的主要优势之一是表达能力,它提高了代码的抽象层次。也就是说,它们显示了它们做什么,而不是它们如何实现。
但是,它们还带来了其他几个优势:
- 它们避免了一些常见的错误,例如越界错误或处理空集合。当编写一个 for 循环时,始终需要确保它在正确的步骤停止,并且在没有元素可迭代时能够正常运行。所有算法都会自动处理这些问题。
- 当使用 STL 算法时,可以获得一定质量级别的实现。这些算法是由了解其工作原理的人员实现的,并且经过了广泛的测试。
- STL 算法提供了最佳的算法复杂度。
std::copy非常容易实现,但还有一些更复杂的算法,如果用朴素的方法实现,其复杂度可能是O(n²),但可以优化到O(n),例如集合上的算法。STL 在这方面提供了最佳的实现。 - STL 的设计将算法与其操作的数据解耦,因此数据和操作可以独立发展,至少在一定程度上是这样。
四、采用算法时需要注意的两个陷阱
在使用 STL 算法之前,需要知道两个常见的陷阱。
4.1、不要对每个问题都使用 for_each
如果习惯于编写 for 循环,可能会被 std::for_each 所吸引,因为这个算法看起来有点像 for 循环。事实上,for_each 会将一个函数(或函数对象或 lambda 表达式)依次应用于集合中的所有元素:
template <typename InputIterator, typename Function>
Function for_each(InputIterator first, InputIterator last, Function f);
std::for_each 确实是一个 STL 算法,因此合理的使用它是一件好事。但 for_each 实际上只适合一种特定情况:执行副作用。for_each 应该用于修改它所应用的集合中的元素,或者更一般地执行副作用,例如向日志记录器或外部服务发送信息。
例如:
-
如果需要计算某个值在一个集合中出现的次数,不要使用
for_each,应该使用std::count。 -
如果需要知道集合中是否存在至少一个满足某个谓词的元素,不要使用
for_each,应该使用std::any_of。 -
如果需要知道集合中的所有元素是否都满足某个给定的谓词,应该使用
std::all_of。 -
如果需要知道一个集合是否另一个集合的排列,以最有效的方式,使用
std::is_permutation。 -
等等。
STL 提供了各种各样的方法来表达意图,使代码尽可能地具有表达能力。可以通过选择最适合每种特定情况的算法来从中获益(或者编写自己的算法)。
4.2、如此多的算法
存在的算法种类繁多,可能会让人感到不知所措。当使用像这样的参考来查找算法时,会发现其中一些算法,例如 copy、count 或 find,并且很容易看出它们有多有用。
但列表中还有一些算法,它们的名字可能很神秘,例如 std::lexicographical_compare、std::set_symmetric_difference 或 std::is_heap_until。
一种自然的反应是忽略这些看起来很奇怪的算法,因为你可能会认为它们非常复杂,或者是为了永远不会遇到的特定情况而设计的。当刚开始使用 STL 算法时,肯定有过这样的反应。
但这是错误的。几乎所有算法在日常代码中都有用。
以 std::set_difference 为例。了解这个算法吗?它对集合进行差集运算(这里的集合指的是排序的集合,不仅仅是 std::set)。也就是说,对于排序的集合 A 和排序的集合 B,set_difference 输出 A 中不在 B 中的元素。
这有什么用呢?以一个进行缓存的计算模型为例。每次计算这个模型时,它都会生成一些可以添加到缓存中的结果。将缓存表示为一个关联容器,它包含键和值,允许存在多个相同的键,这就是 std::multimap 的用途。
因此,该模型以这种方式生成结果:
std::multimap<Key, Value> computeModel();
缓存可以以这种方式接受新数据:
void addToCache(std::multimap<Key, Value> const& results);
在 addToCache 函数的实现中,需要小心,不要添加缓存中已存在的結果,以避免重复项累加。
以下是实现方式,不使用算法:
for (std::multimap<Key, Value>::const_iterator it = newResults.begin(); it != newResults.end(); ++it)
{
std::pair<std::multimap<Key, Value>::const_iterator, std::multimap<Key, Value>::const_iterator> range = cachedResults.equal_range(it->first);
if (range.first == range.second)
{
std::multimap<Key, Value>::const_iterator it2 = it;
while (!(it2->first < it->first) && !(it->first < it2->first))
{
++it2;
}
cachedResults.insert(it, it2);
}
}
其实没必要这样实现,可以用不同的方式重新表述问题:需要将结果中的元素添加到缓存中,但这些元素不在缓存中。这就是 std::set_difference 的用途:
std::multimap<Key, Value> resultsToAdd;
std::set_difference(newResults.begin(),
newResults.end(),
cachedResults.begin(),
cachedResults.end(),
std::inserter(resultsToAdd, resultsToAdd.end()),
compareFirst);
std::copy(resultsToAdd.begin(), resultsToAdd.end(), std::inserter(cachedResults, cachedResults.end()));
std::inserter 与 std::back_inserter 类似,只是它调用与之关联的容器的 insert 方法,而不是 push_back,compareFirst 是自己定义的一个函数,用于告诉 std::set_difference 对元素的键进行比较,而不是对键值对进行比较。
比较这两段代码。第二段代码说明了它做了什么(集合差集),而第一段代码只是让你去解读它。在这个特定的例子中,传递给 set_difference 的参数仍然有点多,这可能会让在不习惯的情况下难以理解。这个问题可以通过范围(Ranges)的概念来解决。
五、总结
学习所有 STL 算法需要时间和精力,但这是一项非常有益的投资。这些算法提供了强大的功能,可以显著提高代码的质量和表达能力。
虽然 STL 算法库很庞大,包含了各种各样的算法,但这并不意味着需要全部掌握。相反,可以从最常用和最基础的算法开始学习,如 copy、count、find 等。然后逐步扩展到更复杂的算法,如 set_difference、is_permutation 等。
通过不断学习和实践,开发者可以掌握更多 STL 算法的用法,并在日常工作中灵活应用。这不仅可以提高代码的可读性和维护性,还能避免常见的错误,并获得最佳的算法复杂度。

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











