










目录
3、递归实现DFS遍历树(更容易理解,还是就记这个吧,天啊噜)
1、定义
维基百科:深度优先搜索算法(英语:Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法。
这个算法会尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。
这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。[1](p603)这种算法不会根据图的结构等信息调整执行策略[来源请求]。
深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的拓扑排序表[1](p612),利用拓扑排序表可以方便的解决很多相关的图论问题,如无权最长路径问题等等。
2、DFS思想
- DFS的思想:从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解,那就返回到上一个节点,然后从另一条路开始走到底。
- DFS适合此类题目:给定初始状态跟目标状态,要求判断从初始状态到目标状态是否有解。
感觉和回溯法具有相同的思想:
- 回溯法适合的问题:有多个状态,并且每个状态具有多个选项;选择了一个选项后,进入下一步,然后又面临新的选项;重复选择,直到到达最终的状态。
- 形象地用树状结构表示思想:
节点表示状态;节点间的连线表示选项;树的叶节点表示最终状态;
如果叶节点满足约束条件,则找到一个可行方案;
反之,不满足约束条件则需要回溯到它的父节点,然后尝试其他选项。如果父节点的所有选项都尝试过了,能找到最好可行方案最好,不能找到的话,就再次回溯到父节点的父节点。如果所有节点、连线都尝试了还没满足约束条件的话,该问题无解。(像极了人生,只不过人生不能回溯)
参考剑指offer第11题:
3、java实现深度优先搜索
3、1 DFS访问无向图
参考算法第四版p340,递归遍历所有顶点,在访问一个顶点时:
- 将其标记为visited;
- 递归地访问它的所有没有被访问过的邻居节点。
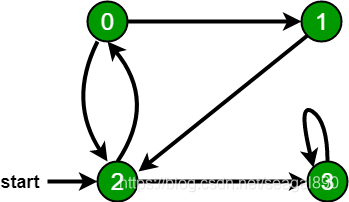
例如,在下图中,我们从顶点2开始遍历。当我们到达顶点0时,我们寻找它的所有相邻顶点。2也是0的相邻顶点。如果我们不标记访问过的顶点,那么2将再次被处理,它将成为一个非终止过程。下图的深度优先遍历是2、0、1、3。
分析:
- 上图有4个结点(顶点):0,1,2,3
- 边的数量:6
- 边的表示:(0,1)(0,2)(1,2)(2,0)(2,3)(3,3)
(1)顶点 v选择一个与v相邻的未被访问的顶点w
(2)并从w出发以深度优先搜索
(3)若一个顶点v的所有相邻顶点都被访问过了,则退回到最近被访问过、且有未被访问的w顶点!!!
(4)然后从w出发继续进行深度优先搜索
(5)当从任何已经访问的顶点出发,不再有未访问的顶点时,搜索终止
邻接表:如果我们想构造出这个图,可以采用邻接表表示。以下代码基于LinkList实现邻接表。
package Sword;
import java.util.Iterator;
import java.util.LinkedList;
public class DFS {
public static void main(String[] args) {
DFS g = new DFS(4);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 2);
g.addEdge(2, 0);
g.addEdge(2, 3);
g.addEdge(3, 3);
System.out.println("下面是DFS搜索结果 " + "(从2号结点开始)");
g.DFSTravel(2);
}
// ---- DFS访问无向图------------------------------------------------------
// 结点
private int v;
// 邻接表
LinkedList<Integer> neighbor[];
// 图的构造方法
DFS(int cv) {
this.v = cv;
neighbor = new LinkedList[cv];
for (int i = 0; i < cv; ++i)
neighbor[i] = new LinkedList();
}
// 向图中cv点添加边(cv,m)
public void addEdge(int cv, int w) {
neighbor[cv].add(w);
}
// 回溯函数
public void DFSUtil(int cv, boolean[] visited) {
// 标记当前结点为已访问(visited)并输出
visited[cv] = true;
System.out.print(cv + " ");
// 访问当前的结点的所有邻接结点
Iterator<Integer> i = neighbor[cv].listIterator();
while (i.hasNext()) {
int n = i.next();
if (!visited[n])
DFSUtil(n, visited);
}
}
// DFS traversal. 用来回溯调用 DFSUtil()函数
public void DFSTravel(int cv) {
// 标记所有节点为未访问状态( not visited),设置初始值为false。
boolean[] visited = new boolean[this.v];
// 回溯 DFS traversal
DFSUtil(cv, visited);
}
}
仿真结果:
下面是DFS搜索结果 (从2号结点开始)
2 0 1 3 3、2 DFS访问树(不一定是二叉树)
1、思想
- DFS遍历树,可以使用递归(分为三种,前中后序遍历)或者非递归(使用栈),思想就是尽可能深地遍历完树的子节点。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。属于盲目搜索。
- 相比较而言,而广度搜索BFS是尽可能按层遍历完子节点。
2、树的实现
树是一种特殊的有向图。列举一种表示方式:
public class TreeNode<V> {
private V value;
private List<TreeNode<V>> childList;//子节点列表
public TreeNode(V value) {
this.value = value;
}
public TreeNode(V value, List<TreeNode<V>> childList) {
this.value = value;
this.childList = childList;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
public List<TreeNode<V>> getChildList() {
return childList;
}
public void setChildList(List<TreeNode<V>> childList) {
this.childList = childList;
}
}3、递归实现DFS遍历树(更容易理解,还是就记这个吧,天啊噜)
public static <V> void dfs(TreeNode<V> tree, int depth) {
if (tree != null) {
//打印节点值以及深度
System.out.println(tree.getValue().toString() + ", " + depth);
if (tree.getChildList() != null && !tree.getChildList().isEmpty()) {
for (TreeNode<V> item : tree.getChildList()) {
dfs(item, depth + 1);
}
}
}
}
一般来说,递归实现DFS 算法又分为如下三种:
1). 前序遍历(Pre-Order Traversal,根 - 左 - 右) :指先访问根,然后访问子树的遍历方式
private static <V> void dfs(TreeNode<V> tree, int depth) {
if (d != null) {
//打印节点值以及深度
System.out.println(tree.getValue().toString() + ", " + depth);
if (tree.getChildList() != null && !tree.getChildList().isEmpty()) {
for (TreeNode<V> item : tree.getChildList()) {
dfs(item, depth + 1);
}
}
}
}
2). 后序遍历(Post-Order Traversal, 左 - 右 - 根):指先访问子树,然后访问根的遍历方式
private static <V> void dfs(TreeNode<V> tree, int depth) {
if (d != null) {
if (tree.getChildList() != null && !tree.getChildList().isEmpty()) {
for (TreeNode<V> item : tree.getChildList()) {
dfs(item, depth + 1);
}
}
//打印节点值以及深度
System.out.println(tree.getValue().toString() + ", " + depth);
}
}
3). 中序遍历(In-Order Traversal, 左 - 根 - 右):指先访问左(右)子树,然后访问根,最后访问右(左)子树的遍历方式。
中序遍历一般是用二叉树实现:
private static <V> void dfs(TreeNode<V> root, int depth) {
if (root.getLeft() != null){
dfs(root.getLeft(), depth + 1);
}
//打印节点值以及深度
System.out.println(d.getValue().toString() + ", " + depth);
if (root.getRight() != null){
dfs(root.getRight(), depth + 1);
}
}4、非递归实现DFS遍历树(栈)
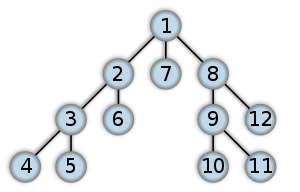
深度优先遍历各个节点,可以使用堆(Stack)这种数据结构。stack的特点是是先进后出。对于右图例子,整个遍历过程如下:
- 首先将A节点压入堆中,stack(A);

- 将A节点弹出,同时将A的子节点C,B压入堆中,此时B在堆的顶部,stack(B,C);
- 将B节点弹出,同时将B的子节点E,D压入堆中,此时D在堆的顶部,stack(D,E,C);
- 将D节点弹出,没有子节点压入,此时E在堆的顶部,stack(E,C);
- 将E节点弹出,同时将E的子节点I压入,stack(I,C);
- ...依次往下,最终遍历完成
对于右图来说深度优先遍历的结果就是:A,B,D,E,I,C,F,G,H.(假设先走子节点的的左侧)。
public static <V> void dfsNotRecursive(TreeNode<V> tree) {
if (tree != null) {
//次数之所以用 Map 只是为了保存节点的深度,
//如果没有这个需求可以改为 Stack<TreeNode<V>>
Stack<Map<TreeNode<V>, Integer>> stack = new Stack<>();
Map<TreeNode<V>, Integer> root = new HashMap<>();
root.put(tree, 0);
stack.push(root);
while (!stack.isEmpty()) {
Map<TreeNode<V>, Integer> item = stack.pop();
TreeNode<V> node = item.keySet().iterator().next();
int depth = item.get(node);
//打印节点值以及深度
System.out.println(tree.getValue().toString() + ", " + depth);
if (node.getChildList() != null && !node.getChildList().isEmpty()) {
for (TreeNode<V> treeNode : node.getChildList()) {
Map<TreeNode<V>, Integer> map = new HashMap<>();
map.put(treeNode, depth + 1);
stack.push(map);
}
}
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









