







原始问题
国产化 ngbe 网卡使用 dpdk pmd 驱动,出现不发包问题,需要在异常环境上排查是否是上层发出了一个异常的报文导致。
能不能 dump 上层软件发出的异常报文?
按照过往的认识,在出现问题的时刻,上层软件已经发完了报文,这时候报文应该已经被释放了,这样看来应该根本抓取不到异常报文了。
上面的描述的口吻明显不坚定,应该这个词表露出可能存在认识的偏差。那到底能不能做到呢?
给出做不到的结论很容易,但真的不能吗?
回答能不能不应该单凭感性的认识,应该进一步思考并实际测试来验证。把上面的问题分析一下,不难发现要确定能不能只需要确定上层是否在发出报文后就直接释放了报文。
下面我就从这个问题着手描述。
1. 上层软件发完包后会直接释放报文吗?
回答这个问题可以通过查看上层软件的发包逻辑入手,这里的上层软件有一个简单的原型——dpdk l2fwd 示例程序,这里我就分析下 l2fwd 的发包逻辑。
l2fwd 是 dpdk 二层转发示例程序,它并不会主动发包,它首先收到包,然后才能发包。
l2fwd 程序的发包逻辑如下:
static void
l2fwd_simple_forward(struct rte_mbuf *m, unsigned portid)
{
unsigned dst_port;
int sent;
struct rte_eth_dev_tx_buffer *buffer;
dst_port = l2fwd_dst_ports[portid];
if (mac_updating)
l2fwd_mac_updating(m, dst_port);
buffer = tx_buffer[dst_port];
sent = rte_eth_tx_buffer(dst_port, 0, buffer, m);
if (sent)
port_statistics[dst_port].tx += sent;
}
m 为上层传进来的一个 mbuf 报文,上述逻辑通过 rte_eth_tx_buffer 接口来发包。
此函数与这里的问题相关的逻辑如下:
- 发包数目到了一个 thresh 后才真正发包,成功发包后没有释放 mbuf 的操作
- 未成功发出的报文直接释放
上面的描述已经说明,当 rte_eth_tx_buffer 成功发出包的时候并不会释放 mbuf,那么问题来了这些 mbuf 难道不需要释放?
dpdk 程序中 mbuf 来自于 mbufpool。这个 mbufpool 在初始化的时候创建指定数目的 mbuf,使用的过程中并不会动态增加 mbuf 数目,真实的流动中 mbuf 在 alloc、free 这些动作中不断进出 mbufpool。
如果一直不释放 mbuf,而发包还需要申请 mbuf,那么 mbufpool 总有耗尽的时候,一旦耗尽首先无法收包,又因为 l2fwd 不会主动发包,不能收到包也就不会再发包。
可是初步分析代码并没有看到有释放 mbuf 的地方?那发包时到底是谁在释放 mbuf 呢?
2. 发包时到底是谁在释放 mbuf 呢?
我最初的答案是上层程序在调用 rte_eth_tx_burst 发包后主动释放 mbuf。
最开始我感觉上层程序调用了 rte_eth_tx_burst 后报文就通过网卡成功发出去了,然后上层来释放,表面上看上去好像也说得通,后期的分析却推翻了这一结论。
这时我想到在这个答案中我忽略了一个关键的问题:rte_eth_tx_burst 调用完成并不代表包真的成功发出去了!
那为什么我会给出这样一个答案呢?
主要还是我对发包的底层细节完全不清楚, 不知道 rte_eth_tx_burst 填充了报文的地址到描述符上到网卡真正成功发包这中间还有许多细节,例如网卡访问发包描述符、网卡发起 PCIE 传输请求拷贝报文到网卡内部 fifo、phy 层对报文的电信号转换等等。
显然可以实现为 rte_eth_tx_burst 返回的时候包成功发出,只需要在这个函数里面添加等待并判断包发送完成然后再返回,可实际的驱动并没有这样干,那为什么它不这样做呢?
我认为主要是基于并行系统的性能优化做的选择。
上层调用 rte_eth_tx_burst 这个接口发包主要涉及对 cpu 与内存的使用,与此同时 PCIE、网卡也在【并行】工作。
从网卡读取描述符获知上层填充的报文的地址到网卡成功发包的过程相对漫长,而 cpu 的处理速度却非常快。
如果 cpu 在 rte_eth_tx_burst 中判断包发送完成,就需要一直轮询等待,会浪费很多 cpu 算力,类似于 cpu 停下来等网卡部分工作完成。
这样 cpu 与网卡、PCIE 之间并行性就非常差了,当有大量的包发送时,cpu 等待的时间就会大量增加,性能表现就会非常差。
同时需要说明的是对于上层程序而言,释放 mbuf 的时机是 mbuf 上关联的报文已经被网卡 copy 到自己内部 fifo 后。
实际的驱动代码中,发包时 mbuf 的释放在网卡发包函数回收发包描述符的时候进行。
3. intel 网卡的发包模型
在 网卡手册阅读:ixgbe 发包流程研究 这篇文章中我描述过 intel 82599 网卡的发包流程,其中一个关键的结构是环形描述符队列,如下图所示:
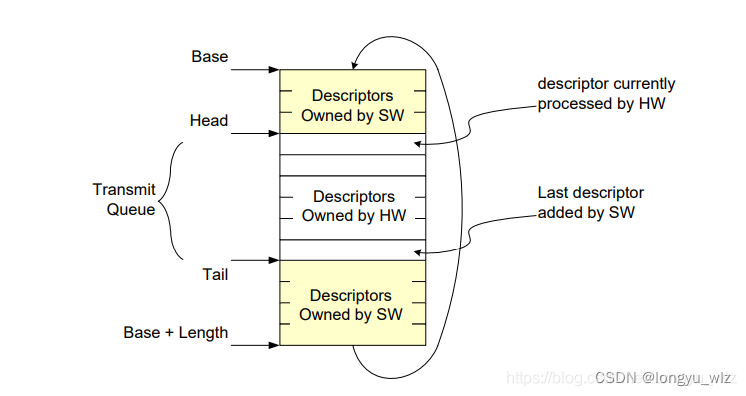 dpdk 驱动发包时,首先会申请【空闲】的发包描述符,然后使用 mbuf 中的字段填充描述符,填充完成后再更新 TDT 寄存器(设置了一个门限降低频繁访问寄存器 I/O 的性能影响)。
dpdk 驱动发包时,首先会申请【空闲】的发包描述符,然后使用 mbuf 中的字段填充描述符,填充完成后再更新 TDT 寄存器(设置了一个门限降低频繁访问寄存器 I/O 的性能影响)。
网卡硬件读取 TDH 与 TDT之间的发包描述符发起 PCIE 传输 copy 报文到内部的 fifo 中然后更新 TDH 并回写描述符(也存在一个门限)。
上图实际运作过程中,TDH 在不断的追 TDT,到达环的底部后再回到起始位置。
cpu 填充发包描述符的速度很快,这个环形队列的长度在某种程度上代表了cpu 缓冲给 PCIE 传输与网卡更新描述符的时间,理想的情况是 cpu 一直能够获取到空闲的描述符,这样 cpu 等待的时间就非常少了,cpu 与 PCIE、网卡的并行性更好,性能表现也就更好了。
如果将描述符的数量设置为 1,在这种极端的情况下,cpu 就要不断地等待,接近于上文描述的在 rte_eth_tx_burst 中等待发包完成的情况。
在 dpdk 问题分析:dpdk-19.11 性能优于 dpdk-16.04 问题分析 这篇文章中,我就曾经描述过通过调大 dpdk-16.04 的默认描述符个数来达到性能优化的目标,背后的原理就是增加留给 PCIE 传输报文与网卡处理的缓冲时间。
4. dpdk 真实驱动中释放发包描述符上报文的过程
ixgbe 的发包函数中有如下代码:
if (txq->nb_tx_free < txq->tx_free_thresh)
ixgbe_tx_free_bufs(txq);
nb_tx_free 表示发包队列上空闲的描述符个数,tx_free_thresh 表示回收发包描述符的门限(默认 32),当 nb_tx_free 【小于】tx_free_thresh 时,ixgbe 网卡发包函数调用 ixgbe_tx_free_bufs 回收描述符并释放被回收的描述符上关联的报文。
ixgbe_tx_free_bufs 函数的主要代码如下:
/* check DD bit on threshold descriptor */
status = txq->tx_ring[txq->tx_next_dd].wb.status;
if (!(status & rte_cpu_to_le_32(IXGBE_ADVTXD_STAT_DD)))
return 0;
/*
* first buffer to free from S/W ring is at index
* tx_next_dd - (tx_rs_thresh-1)
*/
txep = &(txq->sw_ring[txq->tx_next_dd - (txq->tx_rs_thresh - 1)]);
for (i = 0; i < txq->tx_rs_thresh; ++i, ++txep) {
/* free buffers one at a time */
m = rte_pktmbuf_prefree_seg(txep->mbuf);
txep->mbuf = NULL;
if (unlikely(m == NULL))
continue;
if (nb_free >= RTE_IXGBE_TX_MAX_FREE_BUF_SZ ||
(nb_free > 0 && m->pool != free[0]->pool)) {
rte_mempool_put_bulk(free[0]->pool,
(void **)free, nb_free);
nb_free = 0;
}
free[nb_free++] = m;
}
if (nb_free > 0)
rte_mempool_put_bulk(free[0]->pool, (void **)free, nb_free);
/* buffers were freed, update counters */
txq->nb_tx_free = (uint16_t)(txq->nb_tx_free + txq->tx_rs_thresh);
txq->tx_next_dd = (uint16_t)(txq->tx_next_dd + txq->tx_rs_thresh);
tx_next_dd 代表一组回收中最后一个描述符的位置,它以 tx_rs_thresh(默认 32)为单位递增。
上述代码回收 tx_next_dd 及其之前的 tx_rs_thresh - 1 个描述符,同时释放这些空闲的描述符上关联的 mbuf,这就是发包阶段真正释放 mbuf 的位置。
如何 dump 上层软件发出的异常报文?
再次回到文首的不发包问题。ngbe dpdk 驱动发包释放 mbuf 的过程与 ixgbe 类似,不发包在驱动侧的表现是分配不到空闲的发包描述符,而描述符又依赖网卡硬件来回写。
如果是因为发送了异常报文导致不发包,则此时网卡不能正常回写描述符,驱动分配不到空闲的描述符就一直发包失败,同时驱动发包时 mbuf 的释放在回收空闲描述符的时候进行,则此时直接 dump 当前出问题口发包描述符上关联的所有 mbuf 就能够 dump 异常报文。
实现方法
ngbe dpdk 驱动发包队列上的 sw_ring 结构中保存了上层最后填充到发包描述符上的 mbuf 地址。
只需要在驱动中增加一个接口在所有的发包队列上遍历并 dump sw_ring 上的所有的 mbuf 并保存为 pcap 文件即可。
注意要使用与出问题 dpdk 程序一致的 dpdk 版本,修改 proc_info secondary 进程代码,调用这个新的接口就能够完成这一目标。
基于 dpdk-16.04 的部分修改 patch 如下:
Index: app/proc_info/main.c
===================================================================
--- app/proc_info/main.c
+++ app/proc_info/main.c
@@ -325,6 +325,8 @@
link.link_status == ETH_LINK_UP ? "yes":"no");
}
+void ngbe_dump_tx_queue_mbuf(uint32_t port_id);
+
int
main(int argc, char **argv)
{
@@ -381,7 +383,7 @@
for (i = 0; i < nb_ports; i++) {
if (enabled_port_mask & (1 << i)) {
-
+ ngbe_dump_tx_queue_mbuf(i);
display_port_speed(i);
if (enable_stats)
nic_stats_display(i);
--- drivers/net/ngbe/Makefile
+++ drivers/net/ngbe/Makefile
@@ -10,7 +10,7 @@
CFLAGS += -DALLOW_EXPERIMENTAL_API
CFLAGS += -O3
-CFLAGS += $(WERROR_FLAGS)
+CFLAGS += $(WERROR_FLAGS) -lpcap
EXPORT_MAP := rte_pmd_ngbe_version.map
Index: drivers/net/ngbe/ngbe_rxtx.c
===================================================================
--- drivers/net/ngbe/ngbe_rxtx.c
+++ drivers/net/ngbe/ngbe_rxtx.c
@@ -2270,6 +2270,74 @@
return 0;
}
+#include <pcap.h>
+void dumpFile(const u_char *pkt, int len, time_t tv_sec, suseconds_t tv_usec);
+void openFile(const char *fname);
+static pcap_dumper_t *dumper = NULL;
+
+void openFile(const char *fname)
+{
+ dumper = pcap_dump_open(pcap_open_dead(DLT_EN10MB, 1600), fname);
+ if (NULL == dumper)
+ {
+ printf("dumper is NULL\n");
+ return;
+ }
+}
+
+void closeFile(pcap_dumper_t *dumper)
+{
+ if (dumper)
+ pcap_dump_close(dumper);
+}
+
+pcap_dump_close
+
+void dumpFile(const u_char *pkt, int len, time_t tv_sec, suseconds_t tv_usec)
+{
+ struct pcap_pkthdr hdr;
+ hdr.ts.tv_sec = tv_sec;
+ hdr.ts.tv_usec = tv_usec;
+ hdr.caplen = len;
+ hdr.len = len;
+
+ pcap_dump((u_char*)dumper, &hdr, pkt);
+}
+
+
+void ngbe_dump_tx_queue_mbuf(uint32_t port_id)
+{
+ int i = 0;
+ int j = 0;
+ int nb_tx_queue = rte_eth_devices[port_id].data->nb_tx_queues;
+ char buff[1024];
+
+ memset(buff, 0x00, sizeof(buff));
+
+ sprintf(buff, "/tmp/dump_port%d.pcap", port_id);
+ openFile(buff);
+
+ for (; j < nb_tx_queue; j++) {
+ struct timeval tv;
+ struct ngbe_tx_queue *txq = rte_eth_devices[port_id].data->tx_queues[j];
+ int length = txq->nb_tx_desc;
+ for (i = 0; i < length; i++) {
+ gettimeofday(&tv, NULL);
+ struct rte_mbuf *m = txq->sw_ring[i].mbuf;
+
+ if (m) {
+ char *pktbuf = rte_pktmbuf_mtod(m, char *);
+ dumpFile((const u_char*)pktbuf, m->pkt_len, tv.tv_sec, tv.tv_usec);
+ } else {
+ printf("%d sw_ring mbuf is NULL\n", i);
+ }
+ }
+ }
+
+ closeFile(dumper);
+}
+
在这个问题里,排查 dump 出的报文,发现都是正常报文,排除异常报文导致不发包的问题。
上层软件发了 data_len 为 0 的报文导致 x710 网卡无法发包问题
在掌握了 dump 网卡发包描述符上报文的能力不久,内部又发现了一个 vpp 使用 x710 网卡不发包的问题。
将本文中的示例代码稍加修改,马上 dump 出了异常口上的报文。使用 wireshark 打开发现部分报文存在长度为 0 的情况。
根据这个情况修改 l2fwd 程序在发包前更改 mbuf 的 pkt_len 字段模拟,成功复现出了不发包的情况。
总结
许多时候我们判定某个事情不能做到带有很强的主观性,面对这种情况需要追问为什么不能做到?当你在尝试描述清楚不能做到的真正原因时,可能你会有一些新的启发。
为什么会这样呢?
其实是在这样一个过程中扩大了自己的知识,这部分扩大的知识让你能够更客观的看待面临的问题并进行深入的思考,有了这个过程才不致陷入到不能的陷阱中,进而实现突破,最终做到那些你感觉根本不能做到的事情。
写到这里我觉得网卡的收发包模型在 dpdk 驱动中处于比较核心的位置,其中的原理涉及到了许多我们关注不到的 case,识别这些问题并自己找到合理的解释,这一过程就是在不断的向更核心的方向前进。














 5381
5381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









