






Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks
Devign: 通过图神经网络学习全面的程序语义进行有效地识别漏洞 [Paper] [Code]
Yaqin Zhou1, Shangqing Liu1,∗, Jingkai Siow1, Xiaoning Du1,∗, and Yang Liu1
1Nanyang Technological University
1{yqzhou, shangqin001, jingkai001, xiaoning.du, yangliu}@ntu.edu.sg
∗Co-corresponding author
33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada.
摘要
漏洞识别对于保护软件系统免受网络安全攻击至关重要. 尤其重要的是在源代码中定位漏洞函数, 以便于修复. 然而, 这是一个充满挑战和乏味的过程, 还需要专门的安全专业知识. 受各种代码表示图中手动定义漏洞模式的工作以及最近在图神经网络方面的进展的启发, 我们提出了 Devign, 一种基于图神经网络的通用模型, 用于通过学习丰富的代码语义表示集进行图级别分类. 它包括一个新的 Conv (卷积) 模块, 用于有效地提取学习到的丰富结点表示中的有用特征, 以进行图级别分类. 该模型是在人工标记的数据集上训练的, 这些数据集建立在 4 个多样化的大型开源 C 语言项目上, 这些项目包含了高复杂性和多种真实源代码, 而不是以前工作中使用的合成代码. 对数据集的广泛评估结果表明, Devign 显著优于现有技术, 平均准确率提高 10.51%, F1得分提高 8.68%, Conv 模块平均准确率增加 4.66%, F1 得分增加 6.37%.
1 介绍
软件漏洞的数量最近迅速增加, 要么通过 CVE (Common Vulnerabilities and Exposures) 公开报告, 要么由专用代码发现. 特别是, 开源库的流行不仅解释了增量, 而且传播了影响. 这些漏洞大多是由不安全的代码引起的, 可被利用来攻击软件系统, 并对经济和社会造成重大损害.
漏洞识别是安全领域一个关键但具有挑战性的问题. 除了静态分析[1, 2]、动态分析[3-8]和符号执行等经典方法外, 将机器学习作为一种补充方法应用取得了许多进展. 在这些早期方法[9-11]中, 人类专家手工构造的特征或模式被用作机器学习算法的输入来检测漏洞. 然而, 造成漏洞的根本原因因漏洞的类型[12]和库而异, 因此用手工构建的特性来描述众多库中的所有漏洞是不切实际的.
为了提高现有方法的可用性并避免人类专家在特征提取方面的繁重劳动, 最近的工作研究了深度神经网络在更加自动化的漏洞识别方式上的潜力[13-15]. 然而, 所有这些工作在学习全面的程序语义以描述真实源代码中高度多样性和复杂性的漏洞方面都有很大的局限性. 首先, 在学习方法方面, 它们要么将源代码视为一个类似于自然语言的扁平序列, 要么仅用部分信息进行表示. 然而, 源代码实际上比自然语言更具结构性和逻辑性, 具有抽象语法树 (AST) 、数据流、控制流等不同的表示形式. 此外, 漏洞有时是细微的缺陷, 需要从语义的多个维度进行全面调查. 因此, 先前工作设计中的缺陷限制了其覆盖各种漏洞的潜力. 其次, 就训练数据而言, [14] 中的部分数据是由静态分析器进行标记的, 这引入了高百分比的假阳性, 而这些假阳性不是真正的漏洞. 另外, 像 [13], 是简单的人造代码 (即在代码中使用“好”或“坏”来区漏洞代码和非漏洞代码) , 远远不及真实代码的复杂性[16].
为此, 我们提出了一种新的基于图神经网络的模型, 其对实际漏洞数据具有复合的编程表示. 这允许我们对一整套经典编程代码语义进行编码, 以捕获各种漏洞特征. 一个关键的创新是一个新的 Conv (卷积) 模块, 它将来自门控循环单元的图的异构结点特征作为输入. Conv 模块通过利用传统的卷积和稠密层来分层地选择更粗糙的特征以进行图级别分类. 此外, 为了证明源代码的复合编程嵌入和所提出的图神经网络模型在漏洞识别这一具有挑战性的任务中的潜力, 我们用 C 编程语言编译了来自 4 个流行且多样化的库中手动标记的数据集. 我们将此模型命名为 Devign (Deep Vulnerability Identification via Graph Neural Networks, 通过图神经网络深度漏洞识别) .
- 在以 AST 为主干的复合代码表示中, 我们将不同级别的程序控制和数据依赖显式编码为混合边的联合图, 每种类型表示的边与相应表示的边连接. 这种全面的表示在以前的工作中并没有被考虑到, 它有助于捕获尽可能广泛的漏洞类型和模式, 并能够通过图神经网络学习更好的结点表示.
- 我们提出了带 Conv 模块的门控图神经网络模型, 用于图级别分类. Conv 模块从结点特征中分层地学习, 从而为图级别分类任务捕获更高级别的表示.
- 我们实现了 Devign, 并通过从 4 个流行的 C 语言库中收集的手动标记的数据集 (消耗约 600 工时) 来评估其有效性. 我们将两个数据集公开并提供了更多详细信息 (https://sites.google.com/view/devign). 结果表明, 与基准线方法相比, Devign 的平均准确率高 10.51%, F1 得分高 8.68%. 同时, Conv 模块带来了平均 4.66% 的准确度和 6.37% 的 F1 得分的提升. 我们将 Devign 与知名的静态分析器进行了比较, 其中 Devign 的表现明显优于所有分析器和所有数据集的平均 F1 得分, 高出 27.99%. 我们将 Devign 应用于从 4 个项目中收集的 40 个最新 CVE 上, 获得了 74.11% 的准确率, 这表明了它在发现新漏洞方面的可用性.
2 Devign 模型
用代码属性图手工构建的漏洞模式, 集成了所有语法和依赖语义, 已被证明是检测软件漏洞的最有效方法之一[17]. 受此启发, 我们设计了 Devign, 使代码属性图上的上述过程自动化, 以使用图神经网络学习漏洞模式[18]. 设计架构如图 1 所示, 它包括三个串行组件: 1) 复合代码语义的图嵌入层, 它将函数的原始源代码编码为具有全面程序语义的联合图结构; 2) 门控图递归层, 通过聚合和传递图中相邻结点的信息来学习结点的特征; 以及 3) Conv(卷积)模块, 其提取有意义的结点表示用于图级别预测.
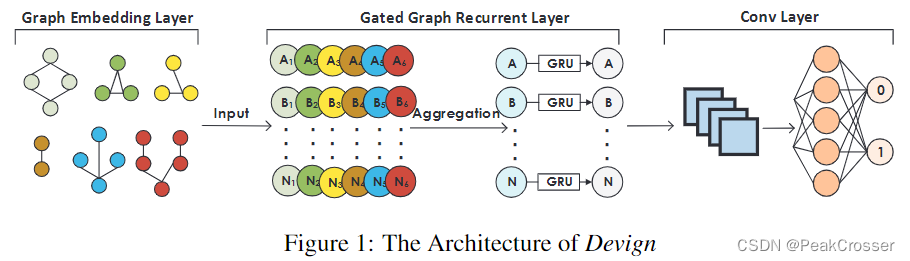
2.1 问题形式化
大多数机器学习或基于模式的方法是在源文件或应用程序的粗粒度级别预测漏洞, 即源文件或程序是否可能存在漏洞[10, 17, 13, 15]. 在这里, 我们在函数级别分析漏洞代码, 这在漏洞分析的整个流程中是一个细粒度级别. 我们将漏洞函数的识别形式化为二分类问题, 即学习判定原始源代码中的给定函数是否是漏洞. 将数据样本定义为
(
(
c
i
,
y
i
)
∣
c
i
∈
C
,
y
i
∈
Y
)
,
i
∈
{
1
,
2
,
.
.
.
,
n
}
((c_i,y_i)|c_i\in\mathcal{C},y_i\in\mathcal{Y}),i\in\{1,2,...,n\}
((ci,yi)∣ci∈C,yi∈Y),i∈{1,2,...,n}, 其中
C
\mathcal{C}
C 表示代码中的函数集,
Y
=
{
0
,
1
}
n
\mathcal{Y}=\{0,1\}^n
Y={0,1}n 表示标签集, 1 表示漏洞, 否则为 0,
n
n
n 表示实例的数量. 由于
c
i
c_i
ci 是一个函数, 我们假设它被编码为一个多边图
g
i
(
V
,
X
,
A
)
∈
G
g_i(V, X, A)\in\mathcal{G}
gi(V,X,A)∈G (有关嵌入细节, 请参见第 2.2 节). 设
m
m
m 为
V
V
V 中的结点总数,
X
∈
R
m
×
d
X\in\mathbb{R}^{m\times d}
X∈Rm×d 是初始结点的特征矩阵, 其中
V
V
V 中的每个顶点
v
j
v_j
vj 由
d
d
d 维实值向量
x
j
∈
R
d
x_j\in\mathbb{R}^d
xj∈Rd 表示.
A
∈
{
0
,
1
}
k
×
m
×
m
A\in\{0,1\}^{k\times m\times m}
A∈{0,1}k×m×m 是邻接矩阵, 其中
k
k
k 是边类型的总数. 元素
e
s
,
t
p
∈
A
e_{s, t}^p\in A
es,tp∈A 等于 1 表示结点
v
s
v_s
vs、
v
t
v_t
vt 通过
p
p
p 类型的边连接, 否则为 0. Devign 的目标是学习从
G
\mathcal{G}
G 到
Y
\mathcal{Y}
Y 的映射
f
:
G
↦
Y
f:\mathcal{G}\mapsto\mathcal{Y}
f:G↦Y 来预测函数是否是漏洞. 可以通过最小化以下损失函数来学习预测函数
f
f
f:
m
i
n
∑
i
=
1
n
L
(
f
(
g
i
(
V
,
X
,
A
)
,
y
i
∣
c
i
)
)
+
λ
ω
(
f
)
\begin{equation} min\sum_{i=1}^n\mathcal{L}(f(g_i(V,X,A),y_i|c_i))+\lambda\omega(f)\tag{1} \end{equation}
mini=1∑nL(f(gi(V,X,A),yi∣ci))+λω(f)(1)
其中
L
(
⋅
)
\mathcal{L}(\cdot)
L(⋅) 是交叉熵损失函数,
ω
(
⋅
)
\omega(\cdot)
ω(⋅) 为正则化,
λ
\lambda
λ 为可调权重.
2.2 复合代码语义的图嵌入层
如图 1 所示, 图嵌入层
E
M
B
EMB
EMB 是将从函数代码
c
i
c_i
ci 到图数据结构的映射作为模型的输入, 即,
g
i
(
V
,
X
,
A
)
=
E
M
B
(
c
i
)
,
∀
i
=
{
1
,
.
.
.
,
n
}
\begin{equation} g_i(V,X,A)=EMB(c_i),\forall i=\{1,...,n\}\tag{2} \end{equation}
gi(V,X,A)=EMB(ci),∀i={1,...,n}(2)
在本节中, 我们描述了为什么以及如何利用经典代码表示将代码嵌入到用于特征学习复合图中的动机和方法.
2.2.1 经典代码图表示与漏洞识别
在程序分析中, 程序的各种表示被用于显示文本代码背后更深层次的语义, 其中经典的概念包括 AST、控制流和数据流图, 它们捕获了源代码不同标记之间的语法和语义关系. 像内存泄漏等大多数漏洞, 都非常微妙, 如果不联合考虑复合代码语义[17], 就无法被发现. 例如, 据报道, 单独使用 AST 只能找到不安全的参数[17]. 通过将 AST 与控制流程图相结合, 它能够覆盖另外两种类型的漏洞, 即资源泄漏和一些释放后使用 (use-after-free) 的漏洞. 通过进一步集成这三种代码图, 除了两种需要额外外部信息的类型(即, 依赖于运行时属性的竞态条件, 以及在没有程序预期设计细节的情况下很难建模的设计错误)之外, 描述大多数类型是可能的.
尽管 [17] 中的漏洞模板是以图遍历的形式手工构建的, 但它传达了关键的见解, 并证明了通过将 AST、控制流图和数据流图的属性集成到联合数据结构中来学习更广泛的漏洞模式的可行性. 除了这三种经典代码结构之外, 我们还考虑了源代码的自然序列, 因为基于深度学习的漏洞检测最近的进展已经证明了其有效性[13, 14]. 它可以补充经典表示, 因为它独特的平面结构以"人类可读"的方式捕捉代码标记间的关系.
2.2.2 代码的图嵌入
接下来, 我们简要介绍每种类型的代码表示, 以及我们如何将各种子图表示为一个联合图, 下面是整数溢出的一个代码示例, 如图 2(a) 所示; 及其图表示, 如图 2(b) 所示.
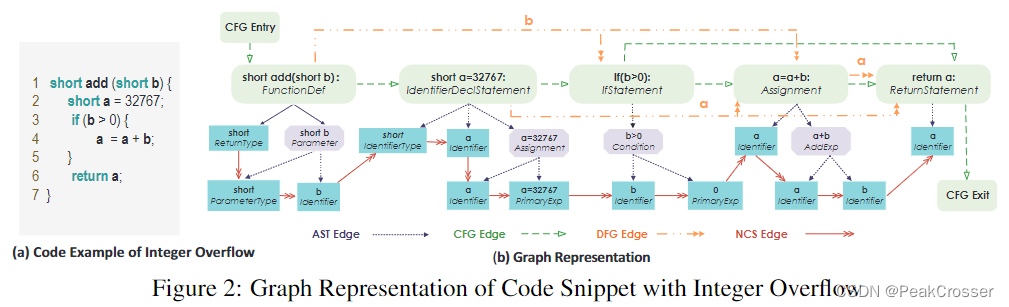
抽象语法树 (Abstract Syntax Tree, AST) AST 是源代码的有序树表示结构. 通常, 它是代码解析器用来理解程序的基本结构和检查语法错误的第一步表示. 因此, 它构成了生成许多其他代码表示的基础, AST 的结点集 V a s t V^{ast} Vast 包括本文中使用的其余三种代码表示的所有结点. 从根结点开始, 代码被分解为代码块、语句、声明、表达式等, 最后被分解为构成叶子结点的主标记. 主要的 AST 结点如图 2 所示. 所有的框都是 AST 结点, 在第一行中有特定的代码, 并标注了结点类型. 蓝色框是 AST 的叶子结点, 紫色箭头表示 父-子 A S T AST AST 关系.
控制流程图 (Control Flow Graph, CFG) CFG 描述了程序执行期间可能遍历的所有路径. 路径可选择的方案由条件语句确定, 例如 if、for 和 switch 语句. 在 CFG 中, 结点表示语句和条件, 它们通过有向边连接以指示控制流的转移. C F G CFG CFG 边在图 2 中用绿色虚线箭头突出显示. 特别地, 流从入口开始在出口结束, 两条不同的路径在 if 语句处派生.
数据流程图 (Data Flow Graph, DFG) DFG 跟踪整个 CFG 中变量的使用情况. 数据流是面向变量的, 任何数据流都涉及对某些变量的访问或修改. DFG 边表示对相同变量的后续访问或修改. 在图 2 中用橙色双箭头表示, 所涉及的变量标注在边上. 例如, 参数 b 在 if 条件和赋值语句中都被使用.
自然代码序列 (Natural Code Sequence, NCS) 为了对源代码的自然顺序进行编码, 我们使用 N C S NCS NCS 边来连接 AST 中的相邻的代码标记. 这种编码的主要好处是保留了源代码序列所反映的编程逻辑. N C S NCS NCS 边在图 2 中用红色箭头表示, 连接 AST 的所有叶子结点.
因此, 函数 c i c_i ci 可以由四种类型的子图 (或 4 种类型的边) 共享同一组结点 V = V a s t V=V^{ast} V=Vast 的联合图 g g g 表示. 如图 (2) 所示, 每个结点 v ∈ V v\in V v∈V 有两个属性, “代码"和"类型”. 代码包含由 v v v 表示的源代码, v v v 的类型表示为类型属性. 初始结点表示 x v x_v xv 应反映两个属性. 因此, 我们通过使用一个预训练 word2vec 模型对代码进行编码, 该模型的代码语料库基于项目中的全部源代码文件构建, 并进行逐标签编码确定类型. 我们将这两种编码结合在一起作为初始结点表示 x v x_v xv.
2.3 门控图递归层
图神经网络的关键思想是通过邻域聚合来嵌入来自局部邻域的结点表示. 基于聚合邻域信息的不同技术, 有图卷积网络[19]、GraphSAGE[20]、门控图递归网络[18]及其变体. 我们选择了门控图递归网络来学习结点嵌入, 因为它允许比其他两个模型训练得更深, 并且更适合我们具有语义和图结构的数据[21].
给定一个嵌入图
g
i
(
V
,
X
,
A
)
g_i (V, X, A)
gi(V,X,A), 对于每个结点
v
j
∈
V
v_j\in V
vj∈V, 我们初始化结点状态向量
h
j
(
1
)
∈
R
z
,
z
≥
d
h_j^{(1)}\in\mathbb{R}^z, z\geq d
hj(1)∈Rz,z≥d 通过将
x
j
x_j
xj 复制到第一维度并填充额外的 0 来使用初始注释, 以允许大于注释大小的隐藏状态, 即
h
j
1
=
[
x
j
⊤
,
0
]
⊤
h^1_j=[x_j^\top, 0]^\top
hj1=[xj⊤,0]⊤. 设
T
T
T 为邻域聚合的总时间步长. 为了在图中传播信息, 在每个时间步
t
≤
T
t\leq T
t≤T, 所有结点经由边的传递信息来彼此通信, 传递信息取决于边的类型和方向 (由
A
A
A 的第
p
t
h
p^{th}
pth 个邻接矩阵
A
p
A_p
Ap 描述, 从定义中我们可以发现邻接矩阵的数量等于边类型), 即,
a
j
,
p
t
−
1
=
A
p
⊤
(
W
p
[
h
1
(
t
−
1
)
⊤
,
.
.
.
,
h
m
(
t
−
1
)
⊤
]
+
b
)
\begin{equation} a_{j,p}^{t-1}=A_p^\top(W_p[h_1^{(t-1)\top},...,h_m^{(t-1)\top}]+b)\tag{3} \end{equation}
aj,pt−1=Ap⊤(Wp[h1(t−1)⊤,...,hm(t−1)⊤]+b)(3)
其中
W
p
∈
R
z
×
z
W_p\in \mathbb{R}^{z\times z}
Wp∈Rz×z 是学习的权重,
b
b
b 是偏差. 特别地, 通过聚合定义在邻接矩阵
A
p
A_p
Ap 上边类型
p
p
p 的所有相邻结点的信息来计算结点
v
j
v_j
vj 的新状态
a
j
,
p
a_{j, p}
aj,p. 剩余的步骤是门控循环单元 (gated recurrent unit, GRU) , 其将来自结点
v
v
v 的所有类型的信息与上一时间步的信息合并, 以获得当前结点的隐藏状态
h
i
,
v
(
t
)
h^{(t)}_{i, v}
hi,v(t), 即,
h
j
(
t
)
=
G
R
U
(
h
j
(
t
−
1
)
,
A
G
G
(
{
a
j
,
p
(
t
−
1
)
}
p
=
1
k
)
)
\begin{equation} h_j^{(t)}=GRU(h_j^{(t-1)},AGG(\{a_{j,p}^{(t-1)}\}_{p=1}^k)) \tag{4} \end{equation}
hj(t)=GRU(hj(t−1),AGG({aj,p(t−1)}p=1k))(4)
其中
A
G
G
(
⋅
)
AGG (\cdot)
AGG(⋅) 表示聚合函数, 其可以是函数
{
M
E
A
N
,
M
A
X
,
S
U
M
,
C
O
N
C
A
T
}
\{MEAN, MAX, SUM, CONCAT\}
{MEAN,MAX,SUM,CONCAT} 之一, 用于聚合来自不同边类型的信息以计算下一时间步结点嵌入
h
(
t
)
h^{(t)}
h(t) . 我们在实现中使用
S
U
M
SUM
SUM 函数. 上述传播过程在
T
T
T 个时间步上迭代, 最后一个时间步的状态向量
H
i
(
T
)
=
{
h
j
(
T
)
}
j
=
1
m
H^{(T)}_i=\{h^{(T)}_j\}^m_{j=1}
Hi(T)={hj(T)}j=1m 是结点集
V
V
V 的最终结点表示矩阵.
2.4 卷积层
从门控图递归层生成的结点特征可用作任何预测层的输入, 例如用于结点或链路或图级别预测, 然后可以以端到端的方式对整个模型进行训练. 在我们的问题中, 我们需要执行图级别分类任务, 以确定函数
c
i
c_i
ci 是否是漏洞. 图分类的标准方法是全局收集所有这些生成的结点嵌入, 例如, 使用线性加权求和来将所有嵌入直接相加[18, 22], 如等式 (5) 所示,
y
~
i
=
S
i
g
m
o
i
d
(
∑
M
L
P
(
[
H
i
(
T
)
,
x
i
]
)
)
\begin{equation} \tilde{y}_i=Sigmoid(\sum MLP([H_i^{(T)},x_i])) \tag{5} \end{equation}
y~i=Sigmoid(∑MLP([Hi(T),xi]))(5)
其中,
s
i
g
m
o
i
d
sigmoid
sigmoid 函数用于分类,
M
L
P
MLP
MLP 表示将
H
i
(
T
)
H^{(T)}_i
Hi(T) 和
x
i
x_i
xi 的组合映射到一个
R
m
\mathbb{R}^m
Rm 向量的多层感知机 (Multilayer Perceptron, MLP) . 这种方法阻碍了对整个图的有效分类[23, 24].
因此, 我们设计了 Conv 模块来选择与当前图级别任务相关的结点和特征集. [24] 中的先前工作提出, 在图卷积层之后使用排序池 (SortPooling) 层, 来对没有固定顺序的图中的结点特征以一致的结点顺序进行排序, 以便可以在其之后添加传统神经网络, 并对其进行训练, 以提取表征图中丰富编码信息的有用特征. 在我们的问题中, 每个代码表示图都有其自己的预定义顺序和邻接矩阵中编码的结点连接, 并且结点特征是通过门控递归图层而非需对来自不同通道的结点特征进行排序的图卷积网络来学习的. 因此, 我们直接应用一维卷积和稠密神经网络来学习与图级别任务相关的特征, 以实现更有效的预测1. 我们将
σ
(
⋅
)
\sigma(\cdot)
σ(⋅) 定义为具有最大池化(maxpooling)的一维卷积层, 然后
σ
(
⋅
)
=
M
A
X
P
O
O
L
(
R
e
l
u
(
C
O
N
V
(
⋅
)
)
)
\begin{equation} \sigma(\cdot)=MAXPOOL(Relu(CONV(\cdot))) \tag{6} \end{equation}
σ(⋅)=MAXPOOL(Relu(CONV(⋅)))(6)
设
l
l
l 为应用的卷积层的数量, 则 Conv 模块可以表示为
Z
i
(
1
)
=
σ
(
[
H
i
(
T
)
,
x
i
]
)
,
.
.
.
,
Z
i
(
l
)
=
σ
(
Z
i
(
l
−
1
)
)
Y
i
(
1
)
=
σ
(
H
i
(
T
)
)
,
.
.
.
,
Y
i
(
l
)
=
σ
(
Y
i
(
l
−
1
)
)
y
~
i
=
S
i
g
m
o
i
d
(
A
V
G
(
M
L
P
(
Z
i
(
l
)
)
⊙
M
L
P
(
Y
i
(
l
)
)
)
)
\begin{align} Z_i^{(1)}=\sigma([H_i^{(T)},x_i]),...,Z_i^{(l)}=\sigma(Z_i^{(l-1)}) \tag{7}\\ Y_i^{(1)}=\sigma(H_i^{(T)}),...,Y_i^{(l)}=\sigma(Y_i^{(l-1)}) \tag{8}\\ \tilde{y}_i=Sigmoid(AVG(MLP(Z_i^{(l)})\odot MLP(Y_i^{(l)}))) \tag{9} \end{align}
Zi(1)=σ([Hi(T),xi]),...,Zi(l)=σ(Zi(l−1))Yi(1)=σ(Hi(T)),...,Yi(l)=σ(Yi(l−1))y~i=Sigmoid(AVG(MLP(Zi(l))⊙MLP(Yi(l))))(7)(8)(9)
其中, 我们首先在组合
[
H
i
(
T
)
,
x
i
]
[H_i^{(T)},x_i]
[Hi(T),xi] 和 最终节点特征
H
i
(
T
)
H_i^{(T)}
Hi(T) 上分别应用传统的一维卷积层和稠密层, 接着在两个输出上进行两两乘法, 然后在结果向量上进行平均聚合, 最后进行预测.
3 评估
我们针对许多最先进的漏洞发现方法评估 Devign 的效果, 目的是理解以下问题:
Q1 我们的 Devign 与其他基于学习的漏洞识别方法相比怎么样?
Q2 对于图级别分类任务, 我们的 Conv 模块驱动的 Devign 与等式 (5) 中的平面求和的 Ggrn 相比怎么样?
Q3 Devign 能否从每种类型的代码表示中学习 (例如, 具有一种信息类型的单边图(single-edged graph))? 使用复合图 (例如, 所有类型的代码表示) 的 Devign 模型如何与每个单边图进行比较?
Q4 在数据集不平衡且漏洞函数百分比极低的真实场景中, 与一些静态分析器相比, Devign 能否有更好的性能?
Q5 Devign 如何处理通过 CVE 公开报告的最新漏洞?
3.1 数据准备
由于需要合格的专业知识, 获得漏洞函数的高质量数据集绝非易事. 我们注意到, 尽管 [15] 发布了漏洞函数的数据集, 但标签是由不准确的统计分析器生成的. [25] 中使用的其他潜在数据集也不可用. 在这项工作中, 在我们的工业合作伙伴的支持下, 我们投入了一支安全团队, 从头开始收集和标记数据. 除了原始函数集合, 我们还需要为每个函数生成图表示, 并为图中的每个结点生成初始表示. 我们将在下面描述详细的过程.
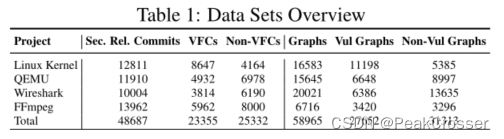
原始数据收集 为了测试 Devign 在学习漏洞模式方面的能力, 我们评估了从 4 个大型 C 语言开源项目中收集的手动标记函数, 这些项目在开发人员中很受欢迎, 并且功能多样化, 即 Linux 内核、QEMU、Wireshark 和 FFmpeg.
为了促进和确保数据标记的质量, 我们首先收集安全相关的提交, 我们将其标记为漏洞修复提交或非漏洞修复提交, 然后直接从标记的提交中提取漏洞或非漏洞函数. 漏洞修复提交 (vulnerability-fix commit, VFC) 是修复潜在漏洞的提交, 我们可以从提交中所做修订之前的版本的源代码中提取漏洞函数. 非漏洞修复提交 (non-vulnerability-fix commit, non-VFC) 是不修复任何漏洞的提交, 类似地, 我们可以从修改前的源代码中提取非漏洞函数. 我们采用了 [26] 中提出的方法来收集提交. 它包括以下两个步骤. 1) 提交过滤. 由于只有一小部分提交与漏洞相关, 我们排除了与安全无关的提交, 这些提交的消息与一组安全相关的关键字 (如 DoS 和注入) 不匹配. 剩下的, 更可能与安全相关, 留给人工标记. 2) 手动打标签. 一个由四名专业安全研究人员组成的团队总共花费了 600 个工时来执行两轮数据标记和交叉验证.
给定 VFC 或 non-VFC, 基于修改的函数, 我们在应用提交之前提取这些函数的源代码, 并相应地分配标签.
图生成 我们利用基于代码属性图的 C/C++ 开源代码分析平台, Joern[17], 为数据集中的所有函数提取 AST 和 CFG. 由于 Joern 中的一些内部编译错误和异常, 我们只能获取部分函数的 AST 和 CFG. 我们会过滤掉没有 AST 和 CFG 或者在 AST 和 CFG 中存在明显错误的这些函数. 由于原始 DFG 边被标记为所涉及的变量, 这大大增加了边类型的数量, 同时使嵌入的图复杂化, 因此我们将 DFG 替换为其他三种关系, 即
L
a
s
t
R
e
a
d
LastRead
LastRead (
D
F
G
_
R
DFG\_R
DFG_R) 、
L
a
s
t
W
r
i
t
e
LastWrite
LastWrite (
D
F
G
_
W
DFG\_W
DFG_W) 和
C
o
m
p
u
t
e
d
F
r
o
m
ComputedFrom
ComputedFrom (
D
F
G
_
C
DFG\_C
DFG_C)[27], 以使其更适合于图嵌入.
D
F
G
_
R
DFG\_R
DFG_R 表示变量每次出现的最近一次读取. 每次出现都可以从 AST 的叶子节点直接识别.
D
F
G
_
W
DFG\_W
DFG_W 表示变量每次出现的最近一次写入. 类似地, 我们对叶子节点变量进行了这些注释.
D
F
G
_
C
DFG\_C
DFG_C 确定变量的来源. 在赋值语句中, 右侧 (right-hand-sid, rhs) 表达式为左侧 (left-hand-side, lhs) 变量赋值一个新值.
D
F
G
_
C
DFG\_C
DFG_C 捕获 lhs 变量和每个 rhs 变量之间的这种关系. 此外, 为了计算效率, 我们删除了结点大小大于 500 的函数, 这占 15%. 我们在表 1 中总结了数据集的统计数据.
3.2 基准线方法
在性能比较中, 我们将 Devign 与最先进的基于机器学习的漏洞预测方法以及使用线性加权求和进行分类的门控图递归网络 (Ggrn) 进行了比较.
Metrics + Xgboost [25]: 我们使用 Joern 为每个函数收集了总共 4 个复杂性指标和 11 个漏洞指标, 并利用 Xgboot 进行分类. 在这里, 我们没有使用所提出的装箱和排序方法, 因为它不是基于学习的, 而是一种启发式方法, 旨在对项目中所有函数的漏洞可能性进行排序. 我们通过贝叶斯优化搜索最佳参数[28].
3-layer BiLSTM [13]: 它将源代码视为自然语言, 并将标记化的代码输入到双向 LSTM 中, 通过 Word2vec 训练初始嵌入. 在这里, 我们实现了 3 层双向以获得最佳性能.
3-layer BiLSTM + Att: 它是 [13] 的改进版本, 具有注意力机制[29].
CNN [14]: 与 [13] 类似, 它将源代码视为自然语言, 并利用单词包获得代码标记的初始嵌入, 然后将其提供给 CNN 学习.
3.3 性能评估
Devign 配置 在嵌入层中, 初始结点表示的 word2vec 的维数为 100. 在门控图递归层中, 我们将隐藏状态的维数设置为 200, 时间步长设置为 6. 对于设计的 Conv 参数, 我们将具有 ReLU 激活函数的 (1, 3) 滤波器应用于第一卷积层, 随后是具有 (1, 2) 滤波器和 (1, 1) 步幅的最大池化层, 并将具有 (2, 2) 滤波和 (1, 2) 步幅最大池化的 (1, 1) 滤波器应用到第二卷积层. 我们使用学习率为 0.0001、批次大小为 128 的Adam 优化器, 并使用 L 2 L2 L2 正则化来避免过度拟合. 我们随机地对每个数据集进行洗牌, 并将 75% 用于训练, 其余 25% 用于验证. 我们在Nvidia Graphics Tesla M40 和 P40 上训练我们的模型, 对提前停止有 100 个轮次(epoch)的耐性.
结果分析 我们使用准确度(accuracy)和 F1 得分来衡量性能. 表 2 总结了所有实验结果. 首先, 我们分析了关于 Q1 的结果, 以及 Devign 与其他基于学习的方法的性能. 从基准线方法、Ggrn 和具有复合代码表示的 Devign 的结果中, 我们可以看到, 在所有数据集中, Ggrn 与 Devign 都显著优于基准线方法. 特别是, 与所有基准线方法相比, Devign 的相对准确度增益平均为 10.51%, 在 QEMU 数据集上至少为 8.54%. Devign (混合的) 在 F1 得分方面也优于 4 种基准线方法, 即 F1 得分的平均相对增益为 8.68%, 每个数据集 (Linux 内核、QEMU、Wirshark、FFmpeg 和组合的) 的最小相对增益分别为 2.31%、11.80%、6.65%、4.04% 和 4.61%. 由于 Linux 遵循编码风格的最佳实践, Devign 的 F1 得分为 84.97, 是所有数据集中最高的. 因此, 以图编码的全面语义的 Devign 比最先进的漏洞识别方法表现得更好.
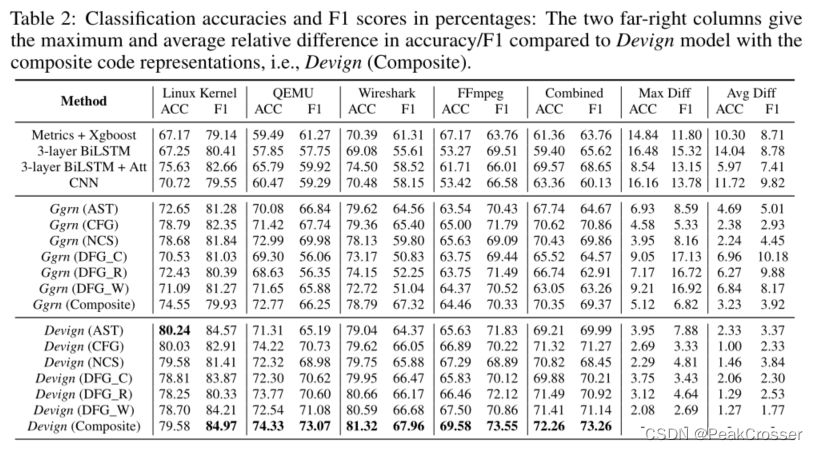
接下来, 我们调查了关于 Devign 对 Ggrn 的性能增益的 Q2 的答案. 我们首先查看使用复合代码表示的分数. 它表明, 在所有数据集中, Devign 比 Ggrn 达到更高的精度 (平均 3.23%) , 其中 FFmpeg 数据集的最高精度增益为 5.12%. 此外, Devign 获得了更好的 F1, 平均比 Ggrn 高 3.92%, 在 QEMU 数据集上, 最高的 F1 增益为 6.82%. 同时, 我们查看了每个单个代码表示的得分, 从中我们得出了类似的结论, 通常 Devign 显著优于 Ggrn, 其中 DFG_W 边的最大精度增益为 9.21%, DFG_C 的最大 F1 增益为 17.13%. 总体而言, 与 Ggrn 相比, Devign 的平均准确率和 F1 增益分别为 4.66% 和 6.37%, 这表明 Conv 模块提取了更多的相关结点和特征用于图级别预测.
然后, 我们检查 Q3 的结果, 以回答 Devign 是否可以学习不同类型的代码表示以及在复合图上的性能. 令人惊讶的是, 我们发现在 Ggrn 和 Devign 中从单边图中获得的结果都非常令人鼓舞. 对于 Ggrn, 我们发现某些特定类型的边的精度甚至略高于复合图, 例如, CFG 和 NCS 图在 FFmpeg 和组合数据集上都有更好的结果. 对于 Devign, 就准确度而言, 除 Linux 数据集外, 复合图表示总体上优于任何单边图, 增益范围为 0.11% 至 3.75%. 就 F1 得分而言, 在所有测试中, 复合图与单边图相比带来的提示平均为 2.69%, 在 Devign 中为 0.4% 至 7.88%. 总之, 复合图有助于 Devign 学习比单边图更好的预测模型.
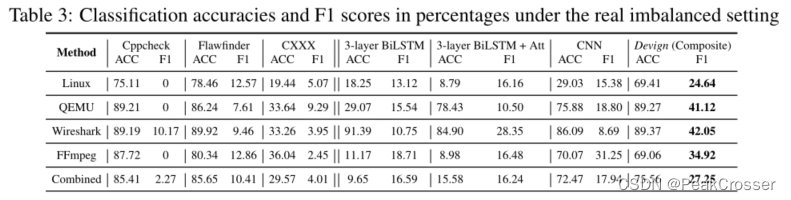
为了回答 Q4 关于在真实不平衡数据集上与静态分析器进行比较的问题, 我们根据一项大型工业分析, 随机抽样测试数据以创建具有 10% 漏洞函数的不平衡数据组[26]. 我们与著名的开源静态分析器 Cppcheck、Flawfinder 和商业工具 CXXX 进行了比较, 出于法律原因, 我们将其名称隐藏起来. 结果如表 3 所示, 与所有分析器和所有数据集 (单独和组合) 的性能相比, 我们的方法表现出色, 平均 F1 得分高 27.99%. 同时, 静态分析器往往会漏掉大部分漏洞函数, 并具有较高的误报率, 例如, Cppcheck 在 4 个单个项目数据集中的 3 个中发现了 0 个漏洞.
最后, 为了回答关于最新公布漏洞的 Q5, 我们分别收集每个项目的最新 10 个CVE, 以检查 Devign 是否可以潜在地应用于识别零日漏洞. 基于 40 个 CVE 的提交修复, 我们总共得到 112 个漏洞函数. 我们将这些函数输入到经过训练的 Devign 模型中, 平均准确度达到 74.11%, 这表明 Devign 在实际应用中发现新漏洞的潜力.
4 相关工作
深度学习的成功启发研究人员将其应用于源代码漏洞发现的更自动化解决方案中[15, 13, 14]. 最近的工作[13, 15, 14]将源代码视为平坦的自然语言序列, 并探索了自然语言处理技术在漏洞检测中的潜力. 例如, [15, 13] 基于 LSTM/BiLSTM 神经网络建立模型, 而 [14] 提出使用 CNN.
为了克服上述模型在代码中表达逻辑和结构的局限性, 许多工作试图探索更多的结构神经网络, 如树结构[30]或图结构[18, 31, 27], 用于各种任务. 例如, [18] 建议通过门控图递归网络生成用于程序验证的逻辑公式, [27] 旨在预测变量名称和变量未使用. [31] 提出了用于二进制代码相似性检测的 Gemini, 其中二进制代码中的函数由属性控制流图和用于学习图嵌入的输入 Structure2vec[22] 表示. 与所有这些工作不同, 我们的工作以漏洞识别为目标, 并结合了全面的代码表示来表达尽可能多的漏洞类型. 此外, 我们的工作采用了在 [18] 中的门控图递归层, 以考虑结点的语义 (例如, 结点注释) 以及结构特征, 这两者在漏洞识别中都很重要. Structure2vec 主要关注学习结构特征. 与 [27] 将门控图递归网络应用于变量预测相比, 我们明确地将控制流图合并到复合图中, 并提出了用于有效图级别分类的 Conv 模块.
5 总结和未来工作
我们提出了一种新的漏洞识别模型 Devign, 能够将源代码函数从多个语法和语义表示编码到联合图结构中, 然后利用复合图表示来有效地学习发现漏洞代码. 它在真正的开源项目上实现了基于机器学习的漏洞函数发现的最新技术. 有趣的未来工作包括通过集成程序切片从大函数中高效学习, 应用学习的模型来跨项目检测漏洞, 以及生成人类可读或可解释的漏洞评估.















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









