






简单来说,这一部分主要是对数据表的查询
目录
比较运算符 between and、 in、like、is null
分组函数(MAX、MIN、AVG、SUM、COUNT+GROUP BY和HAVING子)
条件查询(where和比较运算符)
where
SELECT empno, ename, deptno
FROM emp
WHERE deptno=20;比较运算符 between and、 in、like、is null
between and (闭区间查询)
SELECT empno,ename,sal
FROM emp
WHERE sal BETWEEN 1000 AND 1500;
//查询工资在1000到1500之间的员工编号,姓名,工资。in
SELECT empno, ename, deptno
FROM emp
WHERE deptno IN (10 , 20)
//使用IN运算符,查询出部门为10号或者20号的员工编号,姓名,部门编号like
SELECT ename
FROM emp
WHERE ename LIKE 'S%';
//查询员工姓名中以S开头的员工。
SELECT ename
FROM emp
WHERE ename LIKE '_L%';
//查询员工姓名中第二个字母是L的员工is null
SELECT ename, mgr
FROM emp
WHERE mgr IS NULL;
//查询上级为空的员工姓名、上级编号。多条件查询(逻辑运算符)
逻辑运算符 and、or、not
AND
SELECT empno, ename, job, sal
FROM emp
WHERE sal>=1100
AND job='CLERK';
//查询工资大于1100且职位为‘CLERK’的员工编号、姓名、职位、工资。OR
SELECT empno, ename, job, sal
FROM emp
WHERE sal>=1100
OR job='CLERK';
//查询工资大于1100或职位为‘CLERK’的员工编号、姓名、职位、工资。NOT
SELECT empno, ename, job, sal
FROM emp
WHERE NOT (job='CLERK');
//查询职位不为CLERK的员工编号、姓名、职位、工资
SELECT empno, ename, job, sal
FROM emp
WHERE job <> 'CLERK';逻辑运算符与比较运算符的应用
NOT BETWEEN .. AND .. :不在某个区间
NOT IN (集合):不在某个集合内
NOT LIKE :不像.....
IS NOT NULL: 不是空运算符的优先级
AND 优先级高于 OR ,OR最后执行,可以加()来改变优先级
优先级
运算分类
运算符举例
1
算术运算符
*, \, +, -
2
比较运算符
=, <>, <, >, <=, >=
3
特殊比较运算符
BETWEEN..AND.. ,IN,LIKE,IS NULL
4
逻辑非
NOT
5
逻辑与
AND
6
逻辑或
OR
排序 order by(ORDER BY)
ASC表示按升序排序(默认值), DESC表示按降序排序。
//查询所有员工姓名,职位,部门编号,入职日期,并把结果集按入职日期升序排序。
SELECT ename, job, deptno, hiredate
FROM emp
ORDER BY hiredate;
//查询所有员工姓名,职位,部门编号,入职日期,并把结果集按入职日期降序排序。
SELECT ename, job, deptno, hiredate
FROM emp
ORDER BY hiredate DESC;//ORDER BY子句后的列名也可以写数字,该数字是SELECT语句后列的顺序号。
SELECT ename, deptno, sal
FROM emp
ORDER BY 2 ;
//等价于 ORDER BY deptno//ORDER BY子句后的排序列名也可以同时写多个。
SELECT ename, deptno, sal
FROM emp
ORDER BY deptno ASC, sal DESC;
//先按升序排deptno,如果deptno相同 ,那么按sal降序排列多表查询(内外链接等)
两个表连接
// 在 WHERE子句中书写连接条件。
// 如果在多个表中出现相同的列名,则需要使用表名作为来自该表的列名的前缀。
// N个表相连时,至少需要N-1个连接条件
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2;笛卡尔积
在实际应用中,笛卡尔积本身大多没有什么实际用处,而且还有一个附加问题:产生一个巨表。
- 笛卡尔积在下列情况产生:
-
- 连接条件被省略
- 连接条件是无效的
- 为了避免笛卡尔积的产生,通常需要在WHERE子句中包含一个有效的连接条件
SELECT emp.empno, emp.ename, emp.deptno, dept.deptno, dept.loc
FROM emp, dept;
//查询结果可以看出,笛卡尔积查询出的 记录总数=A表记录数 * B表的记录数等值连接
连接的本质就是过滤掉或者避免产生无意义的两个表的组合数据。等值连接就是对连接条件进行有效的等值判断。
简而言之,拿来消除笛卡尔积的
SELECT emp.empno, emp.ename, emp.deptno, dept.deptno, dept.loc
FROM emp, dept
WHERE emp.deptno=dept.deptno;非等值连接
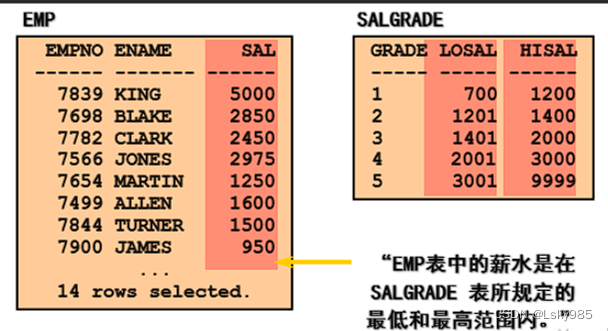
//查询每个员工的姓名,工资,工资等级
SELECT e.ename, e.sal, s.grade
FROM emp e, salgrade s
WHERE e.sal
BETWEEN s.losal AND s.hisal;自连接

//查询每个员工的姓名和直接上级姓名?
SELECT worker.ename ‘WNAME’,manager.ename ‘LNAME’
FROM emp worker, emp manager
WHERE worker.mgr = manager.empno;ANSI SQL:标准的连接语法(外连接)
SELECT table1.column, table2.column
FROM table1
[JOIN table2
ON(table1.column_name = table2.column_name)] |
[LEFT | RIGHT OUTER JOIN table2
ON (table1.column_name = table2.column_name)];左外连接写法
注:左连接和左外连接没啥区别,右外连接也一样。
//查询所有雇员姓名,部门编号,部门名称,包括没有部门的员工也要显示出来
SELECT e.ename,e.deptno,d.loc
FROM emp e
LEFT OUTER JOIN dept d
ON (e.deptno = d.deptno);右外连接写法
//查询所有雇员姓名,部门编号,部门名称,包括没有员工的部门也要显示出来
SELECT e.ename,e.deptno,d.loc
FROM emp e
RIGHT OUTER JOIN dept d
ON (e.deptno = d.deptno);联合查询(UNION/UNION ALL)
//查询所有部门(包括没有员工的部门)及所有员工(包括没有部门的员工)的
SELECT e.empno,e.ename,d.deptno,d.dname
FROM emp e LEFT OUTER JOIN dept d ON(e.deptno = d.deptno)
UNION
SELECT e.empno,e.ename,d.deptno,d.dname
FROM emp e RIGHT OUTER JOIN dept d ON(e.deptno = d.deptno);表别名的使用
SELECT e.empno, e.ename, e.deptno, d.deptno, d.loc
FROM emp e, dept d
WHERE e.deptno= d.deptno;分组函数(MAX、MIN、AVG、SUM、COUNT+GROUP BY和HAVING子)
也叫聚合函数
分组函数
含义
MAX
求最大值
MIN
求最小值
SUM
求和
AVG
求平均值
COUNT
求个数
除了count(*)外,其他聚合函数计算时都会忽略值为NULL的数据
解决方法:IFNULL(null,0) 不会影响原表数据
例子:AVG(IFNULL(目标列,0)) 将null值得列替换成0计算
DISTINCT(distinct)统计去重
//查询有员工的部门数量。
SELECT COUNT(DISTINCT deptno)
FROM emp;MIN和MAX
//查询员工入职的最早日期和最晚日期
SELECT MIN(hiredate), MAX(hiredate)
FROM emp;
//查询最低工资和最高工资
SELECT MIN(sal), MAX(sal)
FROM emp;SUM和AVG
//查询职位以SALES开头的所有员工 工资和、平均工资。
SELECT SUM(sal), AVG(sal)
FROM emp
WHERE job LIKE 'SALES%';
COUNT
//查询部门30有多少个员工
SELECT COUNT(*)
FROM emp
WHERE deptno = 30;
SELECT COUNT(empno) --不建议写COUNT(*)
FROM emp
WHERE deptno = 30; 分组查询语法
//查询每个部门的编号,以及该部门所有员工的平均工资
SELECT deptno, AVG(sal)
FROM emp
GROUP BY deptno;当有GROUP BY子句时,SELECT子句后面只能写:被分组的列、分组函数,这两类元素才有实际意义。
按多列分组查询
//查询每个部门每个岗位的工资总和。
SELECT deptno, job, sum(sal)
FROM emp
GROUP BY deptno, job; 多表查询分组查询
//查询每个部门的部门编号,部门名称,部门人数,最高工资。
SELECT dept.deptno, dname, count(empno), max(sal)
FROM emp ,dept
WHERE emp.deptno = dept.deptno
GROUP BY dept.deptno,dname;
多表查询一定会有where连接条件
过滤分组结果---HAVING的使用
//查询部门人数大于3人的部门编号、部门人数。
SELECT deptno,count(empno)
FROM emp
GROUP BY deptno
HAVING count(empno) >3;对于分组条件的的筛选,需要用having,效果等同于where
SELECT语句6个子句的执行顺序
1、通过FROM子句中找到需要查询的表;
2、通过WHERE子句进行非分组函数筛选判断;
3、通过GROUP BY子句完成分组操作;
4、通过HAVING子句完成组函数筛选判断;
5、通过SELECT子句选择显示的列或表达式及组函数;
6、通过ORDER BY子句进行排序操作。
分页查询limit(mysql的方言)
语法
SELECT 字段列表
FROM 数据源
LIMIT [start,]length;应用
//查询员工表第二页的数据(每页显示4条记录)
SELECT ename, deptno, sal
FROM emp
LIMIT 4,4;
//从第5行数据开始,一页显示4行
举例
第三页数据,一页显示4行
根据 起始索引从0开始,起始索引=(查询页码-1)* 每页显示的记录数
起始索引=(3-1)*4=8
limit 8,4子查询
语法
SELECT select_list
FROM table
WHERE expr operator
( SELECT select_list
FROM table);
//● expr operator包括比较运算符
○ 单行运算符:>、=、>=、<、<>、<=
○ 多行运算符: IN、ANY、ALL
//● 子查询可以嵌于以下SQL子句中:
○ WHERE子句
○ HAVING子句
○ FROM子句//查询出比JONES为雇员工资高的其他雇员
SELECT ename
FROM emp
WHERE sal >
( SELECT sal
FROM emp
WHERE ename='JONES');
运算符
含义
=
等于
>
大于
>=
大于等于
<
小于
<=
小于等于
<>
不等于
//显示和雇员7369从事相同工作并且工资大于雇员7876的雇员的姓名和工作
SELECT ename, job
FROM emp
WHERE job =
(SELECT job FROM emp WHERE empno = 7369)
AND sal >
(SELECT sal FROM emp WHERE empno = 7876);子查询中使用组函数(例子是结合where使用的场景)
//查询工资最低的员工姓名,岗位及工资
SELECT ename, job, sal
FROM emp
WHERE sal = (SELECT MIN(sal) FROM emp);
//也可以排序一下,limitHAVING子句中使用子查询
//查询部门最低工资比20部门最低工资高的部门编号及最低工资
select deptno,min(sal)
from emp
group by deptno
having min(sal)>(select min(sal) from emp where deptno=20);多行子查询(配合 in,any,all使用)
IN
//判断是否与子查询的任意一个返回值相同。
SELECT ename, sal
FROM emp
WHERE empno IN (SELECT mgr
FROM emp);ANY
- ANY:表示和子查询的任意一行结果进行比较,有一个满足条件即可。
-
- < ANY:表示小于子查询结果集中的任意一个,即小于最大值就可以。
- > ANY:表示大于子查询结果集中的任意一个,即大于最小值就可以。
- = ANY:表示等于子查询结果中的任意一个,即等于谁都可以,相当于IN。
//查询是经理的员工姓名,工资。
SELECT ename, sal
FROM emp
WHERE empno = ANY (SELECT mgr
FROM emp);
//查询部门编号不为10,且工资比10部门任意一名员工工资高的员工编号,姓名,职位,工资。
SELECT empno, ename, job, sal
FROM emp
WHERE sal > ANY (SELECT sal
FROM emp
WHERE deptno = 10)
AND deptno <> 10;ALL
- ALL:表示和子查询的所有行结果进行比较,每一行必须都满足条件。
-
- < ALL:表示小于子查询结果集中的所有行,即小于最小值。
- >ALL:表示大于子查询结果集中的所有行,即大于最大值。
- = ALL :表示等于子查询结果集中的所有行,即等于所有值,通常无意义。
//查询部门编号不为20,且工资比20部门所有员工工资高的员工编号,姓名,职位,工资。
SELECT empno, ename,job, sal
FROM emp
WHERE sal > ALL (SELECT sal
FROM emp
WHERE deptno= 20)
AND deptno <> 20;//查询部门编号不为10,且工资比10部门所有员工工资低的员工编号,姓名,职位,工资。
SELECT empno, ename,job, sal
FROM emp
WHERE sal < ALL (SELECT sal
FROM emp
WHERE deptno= 10)
AND deptno <> 10;多列子查询
//查询每个部门入职时间最早的部门编号,员工姓名,入职时间
SELECT deptno,ename,hiredate
FROM emp
WHERE (deptno,hiredate) IN (SELECT deptno ,MIN(hiredate)
FROM emp
GROUP BY deptno);
那么下面这个跟上面这个有什么区别呢?
SELECT deptno,ename,hiredate
FROM emp
WHERE (deptno,hiredate,ename) IN (SELECT deptno,ename ,MIN(hiredate)
FROM emp
GROUP BY deptno,ename);
第一个查询只考虑 deptno 和 hiredate 这两个列的组合,
而第二个查询考虑了 deptno、hiredate 和 ename 这三个列的组合。
这导致查询结果的区别,
第一个查询返回每个部门最早雇佣的员工信息,
而第二个查询返回每个部门每个员工最早雇佣的日期信息。子查询中的空值处理
//查询不是经理的员工姓名。
//错误示范
SELECT ename
FROM emp
WHERE empno NOT IN
(SELECT mgr
FROM emp);
//修改后
SELECT ename
FROM emp
WHERE NOT EXISTS (
SELECT 1
FROM emp e
WHERE e.mgr = emp.empno
);NOT EXISTS (not exists)是一个逻辑运算符,用于检查子查询的结果是否为空。
子查询返回的结果集为空,返回结果为 TRUE
子查询返回的结果集非空,返回结果为 FALSE
此题中的运用原理是
当 NOT EXISTS 子查询返回为空时,外部查询会返回结果;而当 NOT EXISTS 子查询返回非空时,外部查询不会返回结果。
在 FROM 子句中使用子查询
//查询比自己部门平均工资高的员工姓名,工资,部门编号,部门平均工资
SELECT a.ename, a.sal, a.deptno, b.salavg
FROM emp a, (SELECT deptno, AVG(sal) salavg
FROM emp
GROUP BY deptno) b
WHERE a.deptno = b.deptno AND a.sal > b.salavg;就是将查出来的数据当表用。
小技巧
select d.deptno, d.dname,d.loc,count(*)
from emp e,dept d
where e.deptno=d.deptno
group by e.deptno
等价于
select d.*,count(*)
from emp e,dept d
where e.deptno=d.deptno
group by e.deptno碰到题目要求列不在group by里的情况怎么办?
重新起一句select
用 where(group里的列)+in(查询语句)
7.列出各种工作职位的最低工资的员工名字,职位和工资
SELECT ename,job,sal
FROM emp
WHERE (job,sal)
IN(SELECT job,MIN(sal) FROM emp GROUP BY job)
上面语句不完善
下面暂时没看懂
SELECT e.ename, e.job, e.sal
FROM emp e
JOIN (
SELECT job, MIN(sal) AS min_sal
FROM emp
GROUP BY job
) min_salaries
ON e.job = min_salaries.job AND e.sal = min_salaries.min_sal;















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











