




 本文介绍了5款强大的Jupyter Notebook插件,包括Scratchpad(临时代码测试)、Code folding(代码折叠)、Zenmode(专注模式)、Table of contents(目录生成)和Variable Inspector(变量检查器)。这些插件能大幅提升数据分析和代码编写效率,让Notebook更加整洁易用。
本文介绍了5款强大的Jupyter Notebook插件,包括Scratchpad(临时代码测试)、Code folding(代码折叠)、Zenmode(专注模式)、Table of contents(目录生成)和Variable Inspector(变量检查器)。这些插件能大幅提升数据分析和代码编写效率,让Notebook更加整洁易用。
文章目录
1、Scratchpad
这个插件非常有用,我们做数据分析EDA或者特征工程时经常要各种尝试,而不是要真正的运行cell代码。
这个时候在同一个notebook里来回运行就非常容易乱,找不到自己想要的那个对的代码了。当然,可以注释,不过也比较不好管理。
使用这个插件可以在当前内核上运行代码,而不必在实际代码之间不断添加新单元以进行实验或计算。使用 Shift + Enter 打开便签本,然后通过 Ctrl + B 将其关闭。

测试时真心方便
2、Code folding
code folding 插件提供了三种代码折叠选项,在敲代码过程中是非常有必要的。
1、缩进折叠
该算法可以检测缩进,允许将缩进一一折叠。这样我们就可以折叠更多的代码了,看下下面的代码。

如上所示,有两个缩进。因此,此代码单元先折叠为:
进一步的折叠:
2、第一行注释折叠
这种折叠用在第一行中有注释的单元格。
结果是仅显示第一行中的注释,而不显示整个单元格。这样,当我们删除代码时,可以保留第一行的注释,对单元格进行简短而准确的描述。
所以,以下单元格…
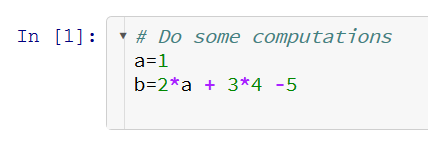
可以折叠成这样:
3、魔术折叠
上面的概念也适用于第一行是魔术命令的情况。
这个特殊的折叠对于import导入包的单元格可能特别有用。
另一个应用场景是删除所有非Python代码,以避免可能的干扰。
折叠会将上面的单元格变成:
3、zenmode
最后一个插件可能是三个中最常用的了。
zenmode插件可以将菜单删除,使你可以专注于代码。
这样可使 Jupyter notebook 的界面在视觉和使用上更舒服。
小屏利器
4、Table of contents
这个插件将为notebook增加一个目录。
通过点击下方图片中红框内的按钮,即可激活或停用它。
当使用含有较多内容的notebook时,该功能的实用性便体现出来了。
点击目录中的任何标题,即可直接定位到notebook的相应位置。
5、Variable Inspector
可以通过菜单上标红的按钮来执行该扩展。
点击按钮后,将显示当下命名空间中的所有变量信息,包括变量的名称、类型、大小、形式和值。
代码量比较大时会有很大用处
6、安装方式
Jupyter NbExtensions Configurator
Jupyter NbExtensions Configurator 是Jupyter Notebook的一个扩展工具,它提供了一系列标签,只需勾选相应插件就能自动载入。里面的插件能帮助减少工作量,书写更优雅的代码和更好的展示结构。
安装Jupyter NbExtensions Configurator
用conda安装:
conda install -c conda-forge jupyter_contrib_nbextensions
conda install -c conda-forge jupyter_nbextensions_configurator
或者用pip:
pip install jupyter_nbextensions_configurator jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
安装完毕,进入Jupyter Notebook,在主界面会多出一个NbExtensions的标签,里面有很多插件可供选择,示意图如下:
上边是重点介绍的几个插件的用法,其余的不详细介绍,有兴趣的可以到官网(https://jupyter-contrib-nbextensions.readthedocs.io/en/latest/index.html)自行了解。

















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









