







文章目录
一、图像检索概述
从20世纪70年代开始,有关图像检索的研究就已开始,当时主要是基于文本的图像检索技术(Text-based Image Retrieval,简称TBIR),利用文本描述的方式描述图像的特征,如绘画作品的作者、年代、流派、尺寸等。到90年代以后,出现了对图像的内容语义,如图像的颜色、纹理、布局等进行分析和检索的图像检索技术,即基于内容的图像检索(Content-based Image Retrieval,简称CBIR)技术。CBIR属于基于内容检索(Content-based Retrieval,简称CBR)的一种,CBR中还包括对动态视频、音频等其它形式多媒体信息的检索技术。
而BOW(Bag of Feature)是一种图像特征提取方法,它借鉴了文本分类的思路(Bag of Words),从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量。
由于随着图像数据快速增长,针对基于文本的图像检索方法日益凸现的问题,在1992年美国国家科学基金会就图像数据库管理系统新发展方向达成一致共识,即表示索引图像信息的最有效方式应该是基于图像内容自身的。因此,接下来我们将分别对CBIR、BOW进行阐述。
(一)基于内容的图像检索(CBIR)
利用文本标注的方式对图像中的内容进行描述,从而为每幅图像形成描述这幅图像内容的关键词,比如图像中的物体,或者景深更大的场景,在进行检索时,使用者可以根据自己的兴趣提供查询关键字,检索系统用使用者提供的查询关键字找出那些标注有该查询关键字对应的图片,最后将查询的结果返回给使用者。
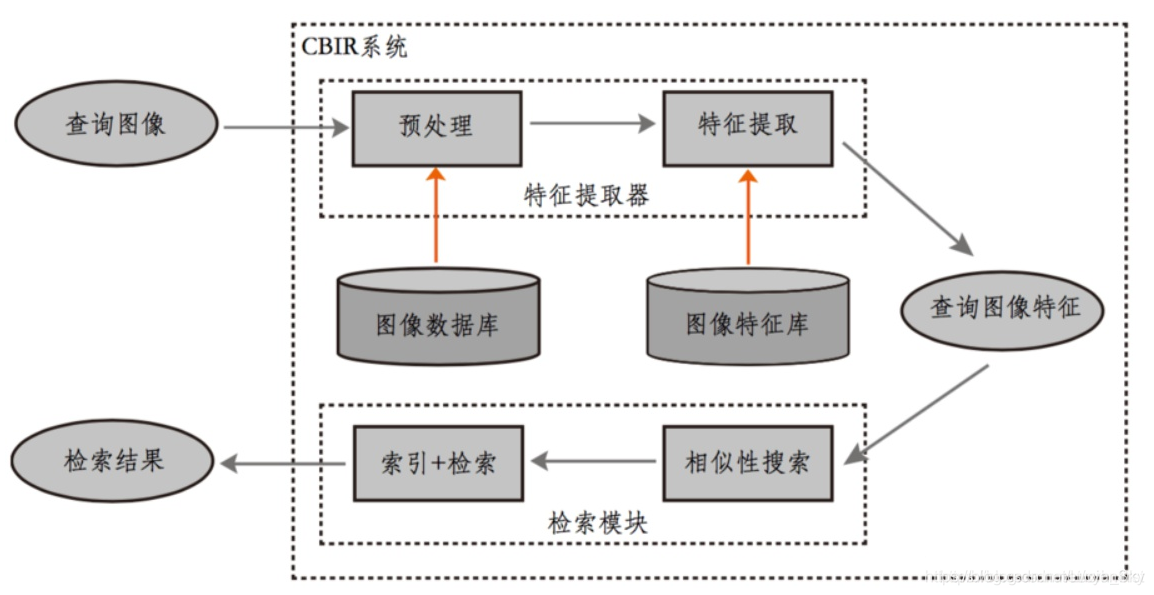
主要流程:
1.图像预处理.
2.特征提取(SIFT)
3.对图像数据库建立图像特征索引
4.抽取检索(Query)图像特征,构建特征向量.
5.设计检索模块(相似度设置准则)
6.返回相似性较高的结果
1.矢量空间模型(BOW表示模型、Bag of Words)
矢量空间模型是一个用于表示和搜索文本文档的模型。它基本上可以应用于任何对象类型,包括图像。该名字来源于用矢量来表示文本文档,这些矢量是由文本词频直方图构成的。矢量包括了每个单词出现的次数,而且在其他别的地方包含很多0元素。由于其忽略了单词出现的顺序及位置,该模型也被称为BOW表示模型(Bag of Words)。
总结来看,这种方式将文本表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。
我们需要找到图像的特征,类似于词汇作为文本的特征,而这种特征必须得对光照,图片的是否旋转,图片畸变等不敏感,而sift特征提取能够较好的满足上述要求,因此,我们使用sift特征提取的方法形成一个词汇。
通过单词计数来构建文档直方图向量v,从而建立文档索引。通常,在单词计数时会忽略掉一些常用词,如 “这” “和” “是” 等,这些常用词称为停用词。由于每篇文档长度不同,因此除以直方图总和将向量归一化成单位长度。对于直方图向量中的每个元素,一般根据每个单词的重要性来赋予相应的权重。通常,数据集(或语料库)中一个单词的重要性与它在文档中出现的次数成正比,而与它在语料库中出现的次数成反比。
最常用的是权重是tf-idf(tern frequency-inverse document frequency,词频-逆向文档频率)

其中, n w n_w nw 是单词 w w w在文档 d d d中的出现的次数。为了归一化,将 n w n_w nw除以整个文档中单词的总数。
则,逆向文档频率为:

其中, ∣ D ∣ ∣D∣ ∣D∣是在语料库 D D D中文档的数目,分母是语料库中包含单词 w w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









