






@TOC:
1.数据处理方面
1.数据源准备
2.数据预处理
2.1填补缺失值
该数据集中存在缺失值,需要检测并处理这些缺失值。使用数据的特征均值填补。计算均值并将其填入空白数据。
2.2 合并数据并绘制散点图
绘制出散点图后发现,两个特征分布的区间并不相同,因此需要在寻找异常点之前进行数据规格化处理
2.3 数据规格化
方法一:Z-score normalization

方法二:min-max normalization
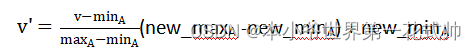
3.算法实现
3.1 基于K-Means算法的异常检查方法
- 首先构造出每一个点的类
package ch2;
/**
* @author RANDI
* @version 1.0
* This is the point package of k_means
* update 0608
*/
public class Point implements Comparable<Point>{
private float[] localArray= new float[2];
private float dist; // 标识和所属类中心的距离。
private int id;
private int clusterId; // 标识属于哪个类中心。
private boolean is_anomaly;
public Point(String info) {
String [] strArray = info.split(",");
this.id=Integer.parseInt(strArray[0]);
this.localArray[0]=Float.parseFloat(strArray[1]);
this.localArray[1]=Float.parseFloat(strArray[2]);
if(strArray[3].equals("TRUE")) {
this.is_anomaly=true;
}
else {
this.is_anomaly=false;
}
}
public Point(int id, float[] localArray) {
this.id = id;
this.localArray = localArray;
}
public Point(float[] localArray) {
this.id = -1; //表示不属于任意一个类
this.localArray = localArray;
}
public float[] getlocalArray() {
return localArray;
}
public int getId() {
return id;
}
public void setClusterId(int clusterId) {
this.clusterId = clusterId;
}
public int getClusterid() {
return clusterId;
}
public float getDist() {
return dist;
}
public boolean getStatus() {
return is_anomaly;
}
public void setDist(float dist) {
this.dist = dist;
}
@Override
public String toString() {
return "`"+this.id+" " + this.localArray[0]+","+this.localArray[1]+" dist: "+dist+ " anomaly:"+ is_anomaly;
}
@Override
public int compareTo(Point p) {
return (int)(this.dist - p.dist);
}
@Override
public boolean equals(Object obj) {
if (obj == null || getClass() != obj.getClass())
return false;
Point point = (Point) obj;
if (point.localArray.length != localArray.length)
return false;
for (int i = 0; i < localArray.length; i++) {
if (Float.compare(point.localArray[i], localArray[i]) != 0) {
return false;
}
}
return true;
}
@Override
public int hashCode() {
float x = localArray[0];
float y = localArray[localArray.length - 1];
long temp = x != +0.0d ? Double.doubleToLongBits(x) : 0L;
int result = (int) (temp ^ (temp >>> 32));
temp = y != +0.0d ? Double.doubleToLongBits(y) : 0L;
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
public String getAnOutput() {
return "['1',"+ + this.localArray[0]+","+this.localArray[1]+"],";
//return "'"+this.is_anomaly+"',";
}
}
- 再构造出每一簇的类
package ch2;
/**
* @author RANDI
* @version 1.0
* This is the cluster package of k_means
* update 0608
*/
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Cluster{
private int id;// 标识
private Point center;// 中心
private List<Point> members = new ArrayList<Point>();// 成员
public Cluster(int id, Point center) {
this.id = id;
this.center = center;
}
public Cluster(int id, Point center, List<Point> members) {
this.id = id;
this.center = center;
this.members = members;
}
public void addPoint(Point newPoint) {
if (!members.contains(newPoint)){
members.add(newPoint);
}else{
System.out.println("样本数据点 {"+newPoint.toString()+"} 已经存在!");
}
}
public int getId() {
return id;
}
public Point getCenter() {
return center;
}
public void setCenter(Point center) {
this.center = center;
}
public List<Point> getMembers() {
return members;
}
@Override
public String toString() {
String toString = "Cluster \n" + "Cluster_id=" + this.id + ", center:{" + this.center.toString()+"}";
float maxDist=0;
int theID=0;
boolean status=false;
//使用sort排序方法,将members排序,选出最大的2个
//members.sort(null);
Collections.sort(members, new Comparator<Point>() {
@Override
public int compare(Point u1, Point u2) {
if(u1.getDist() > u2.getDist()) {
//return -1:即为正序排序
return 1;
}else if (u1.getDist() == u2.getDist()) {
return 0;
}else {
//return 1: 即为倒序排序
return -1;
}
}
});
int index=members.size();
//如果簇里数量多于两个,选2个
if(index>=2) {
theID=members.get(index-1).getId();
maxDist=members.get(index-1).getDist();
status=members.get(index-1).getStatus();
toString+="\n异常点:[id]"+theID+" dist: "+maxDist+" status:"+ status+"\n";
theID=members.get(index-2).getId();
maxDist=members.get(index-2).getDist();
status=members.get(index-2).getStatus();
toString+="\n异常点:[id]"+theID+" dist: "+maxDist+" status:"+ status+"\n";
}
else {//选一个
theID=members.get(index-1).getId();
maxDist=members.get(index-1).getDist();
status=members.get(index-1).getStatus();
toString+="\n异常点:[id]"+theID+" dist: "+maxDist+" status:"+ status+"\n";
}
//从每一簇中选出最远dist作为异常点
// for (Point point : members) {
//if(point.getDist()>maxDist) {
//maxDist=point.getDist();
//theID=point.getId();
//status=point.getStatus();
//}
// toString+="\n"+point.toString();
//}
///toString+="\n异常点:[id]"+theID+" dist: "+maxDist+" status:"+ status;
return toString+"\n";
}
}
- 构造出计算距离的类
package ch2;
/**
* @author RANDI
* @version 1.0
* This is the compute the distance
* update 0608
*/
public class DistanceCompute {
/**
* 求欧式距离
*/
public double getEuclideanDis(Point p1, Point p2) {
double count_dis = 0;
float[] p1_local_array = p1.getlocalArray();
float[] p2_local_array = p2.getlocalArray();
if (p1_local_array.length != p2_local_array.length) {
throw new IllegalArgumentException("length of array must be equal!");
}
for (int i = 0; i < p1_local_array.length; i++) {
count_dis += Math.pow(p1_local_array[i] - p2_local_array[i], 2);
}
return Math.sqrt(count_dis);
}
}
- 实现kMeans算法
package ch2;
/**
* @author RANDI
* @version 1.0
* This is the actual implementation of k_means
* update 0608
*/
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Random;
import java.util.Set;
public class KMeansRun {
private int kNum; //簇的个数
private int iterNum = 10; //迭代次数
private int iterMaxTimes = 100000; //单次迭代最大运行次数
private int iterRunTimes = 0; //单次迭代实际运行次数
private float disDiff = (float) 0.01; //单次迭代终止条件,两次运行中类中心的距离差
private static List<Point> pointList = null; //用于存放,原始数据集所构建的点集
private DistanceCompute disC = new DistanceCompute();
private int len = 2; //用于记录每个数据点的维度
public KMeansRun(int k, List<Point> original_data) {
this.kNum = k;
this.pointList=original_data;
//检查规范
check();
}
/**
* 检查规范
*/
private void check() {
if (kNum == 0){
throw new IllegalArgumentException("k must be the number > 0");
}
}
/**
* 随机选取中心点,构建成中心类。
*/
private Set<Cluster> chooseCenterCluster() {
Set<Cluster> clusterSet = new HashSet<Cluster>();
Random random = new Random();
for (int id = 0; id < kNum; ) {
Point point = pointList.get(random.nextInt(pointList.size()));
// 用于标记是否已经选择过该数据。
boolean flag =true;
for (Cluster cluster : clusterSet) {
if (cluster.getCenter().equals(point)) {
flag = false;
}
}
// 如果随机选取的点没有被选中过,则生成一个cluster
if (flag) {
Cluster cluster =new Cluster(id, point);
clusterSet.add(cluster);
id++;
}
}
return clusterSet;
}
/**
* 为每个点分配一个类!
*/
public void cluster(Set<Cluster> clusterSet){
// 计算每个点到K个中心的距离,并且为每个点标记类别号
for (Point point : pointList) {
float min_dis = Integer.MAX_VALUE;
for (Cluster cluster : clusterSet) {
float tmp_dis = (float) Math.min(disC.getEuclideanDis(point, cluster.getCenter()), min_dis);
if (tmp_dis != min_dis) {
min_dis = tmp_dis;
point.setClusterId(cluster.getId());
point.setDist(min_dis);
}
}
}
// 新清除原来所有的类中成员。把所有的点,分别加入每个类别
for (Cluster cluster : clusterSet) {
cluster.getMembers().clear();
for (Point point : pointList) {
if (point.getClusterid()==cluster.getId()) {
cluster.addPoint(point);
}
}
}
}
/**
* 计算每个类的中心位置!
*/
public boolean calculateCenter(Set<Cluster> clusterSet) {
boolean ifNeedIter = false;
for (Cluster cluster : clusterSet) {
List<Point> point_list = cluster.getMembers();
float[] sumAll =new float[len];
// 所有点,对应各个维度进行求和
for (int i = 0; i < len; i++) {
for (int j = 0; j < point_list.size(); j++) {
sumAll[i] += point_list.get(j).getlocalArray()[i];
}
}
// 计算平均值
for (int i = 0; i < sumAll.length; i++) {
sumAll[i] = (float) sumAll[i]/point_list.size();
}
// 计算两个新、旧中心的距离,如果任意一个类中心移动的距离大于dis_diff则继续迭代。
if(disC.getEuclideanDis(cluster.getCenter(), new Point(sumAll)) > disDiff){
ifNeedIter = true;
}
// 设置新的类中心位置
cluster.setCenter(new Point(sumAll));
}
return ifNeedIter;
}
/**
* 运行 k-means
*/
public Set<Cluster> run() {
Set<Cluster> clusterSet= chooseCenterCluster();
boolean ifNeedIter = true;
while (ifNeedIter) {
cluster(clusterSet);
ifNeedIter = calculateCenter(clusterSet);
iterRunTimes ++ ;
}
return clusterSet;
}
/**
* 返回实际运行次数
*/
public int getIterTimes() {
return iterRunTimes;
}
}
- 主函数为
package ch2;
/**
* @author RANDI
* @version 1.0
* This is the test file of k_means
* 参考:https://blog.csdn.net/fox_wayen/article/details/80467233?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0-80467233-blog-124992548.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3
* 另一种比较可行的办法:https://blog.csdn.net/jshayzf/article/details/22067855
* update 0608
*/
import java.util.ArrayList;
import java.util.Set;
import java.io.*;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
ArrayList<Point> dataSet = new ArrayList<Point>();
File file = new File("C:\\Users\\lenovo\\Desktop\\第二章大作业\\测试数据4.csv");
Scanner sc;
try {
sc = new Scanner(file);
String str;
int line=0;
while (sc.hasNext()) {
str=sc.nextLine();//按行读取文件
if(line!=0) {
dataSet.add(new Point(str));
}
line++;
}
sc.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//k-means
KMeansRun kRun =new KMeansRun(3, dataSet);
Set<Cluster> clusterSet = kRun.run();
System.out.println("单次迭代运行次数:"+kRun.getIterTimes());
for (Cluster cluster : clusterSet) {
System.out.println(cluster);
}
}
}
代码参考:
https://blog.csdn.net/fox_wayen/article/details/80467233?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-0-80467233-blog-124992548.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3
另一种比较可行的办法:https://blog.csdn.net/jshayzf/article/details/22067855
3.2 基于DTI算法的异常检查方法
- 构造决策树
import numpy as np
from math import log
import operator
from collections import Counter
def get_data():
# 特征矩阵
feat_matrix=np.array([
['1',0.30839318,0.043522555],
['1',0.095487,0.03808116],
['1',0.11200761,0.04439067],
['1',0.118840985,0.06460949]
])
values_size = feat_matrix.shape[0]
for discretefeat_idx in range(1):
dict_value_encode = {}
encode = 0
for value in feat_matrix[:,discretefeat_idx]:
if value not in dict_value_encode.keys():
encode += 1
dict_value_encode[value] = encode
for value_idx in range(values_size):
feat_matrix[value_idx][discretefeat_idx] = dict_value_encode[feat_matrix[value_idx][discretefeat_idx]]
feat_matrix = feat_matrix.astype(np.float64)
# 类别标签
labels=np.array(['true','false','false','false'])
# 特征名
feat_names = np.array(['序号', 'cpc', 'cpm'])
return feat_matrix,labels,feat_names
# 计算经验熵
def cal_entropy(x):
x_set = set(x)
x_size = x.shape[0]
entropy = 0.0
for label in x_set:
p = np.count_nonzero(x == label) / x_size
entropy -= p * log(p,2)
return entropy
# 根据选定特征计算条件信息熵
def cal_conditionalentropy(feat_values,labels):
values_set = set(feat_values)
values_size = feat_values.shape[0]
c_entropy = 0.0
for value in values_set:
p = np.count_nonzero(feat_values == value)/values_size
c_entropy += p * cal_entropy(labels[feat_values == value])
return c_entropy
# 计算连续特征的最小条件熵,以得到最大的信息增益
'''
设某连续特征有n个取值,先将它们从小到大排序
使用二分法,尝试n-1种中间值(函数中的阈值就是中间值,通过前后两个元素的平均数计算得)
比较各自的条件熵,取最小的那个,最终得到最大的信息增益
返回值有二,一是最小的条件熵,二是中间值
'''
def cal_min_conditionalentropy(feat_values,labels):
values_size = feat_values.shape[0]
zip_feat_values_labels = dict(zip(feat_values,labels)) # 将连续特征取值和对应的分类标签zip起来
# 按照特征值升序排序,分类标签跟着一起排
zip_feat_values_labels_sorted = dict(sorted(zip_feat_values_labels.items(),key=operator.itemgetter(0)))
feat_values_sorted = np.array(list(zip_feat_values_labels_sorted.keys())) # 排序过后的特征取值
labels_sorted = np.array(list(zip_feat_values_labels_sorted.values())) # 排序过后的分类标签
thresholds = [(feat_values_sorted[idx]+feat_values_sorted[idx+1])/2 # n个特征取值有n-1个缝隙,得n-1个阈值
for idx in range(feat_values_sorted.shape[0]-1)]
min_c_entropy = float('inf')
min_c_entropy_threshold = (feat_values_sorted[0] + feat_values_sorted[1])/2 # 初始化阈值是第一个缝隙中的
for threshold in thresholds:
filter_left = feat_values_sorted <= threshold # 阈值左边的部分
feat_values_left = feat_values_sorted[filter_left]
labels_left = labels_sorted[filter_left]
filter_right = feat_values_sorted > threshold # 阈值右边的部分
feat_values_right = feat_values_sorted[filter_right]
labels_right = labels_sorted[filter_right]
c_entropy = feat_values_left.shape[0]/values_size*cal_entropy(labels_left) +\
feat_values_right.shape[0]/values_size*cal_entropy(labels_right)
if c_entropy <= min_c_entropy:
min_c_entropy = c_entropy
min_c_entropy_threshold = threshold
return min_c_entropy,min_c_entropy_threshold # 返回有二,最小的条件信息熵和对应的阈值
# 根据选定特征计算信息增益
def cal_info_gain(feat_values,labels):
# 如果是离散值
if feat_values[0].item()>=1:
return cal_entropy(labels) - cal_conditionalentropy(feat_values,labels),'discrete'
# 如果是连续的
else:
min_c_entropy, min_c_entropy_threshold = cal_min_conditionalentropy(feat_values,labels)
return cal_entropy(labels) - min_c_entropy,min_c_entropy_threshold
# 根据选定特征计算信息增益比
def cal_info_gain_ratio(feat_values,labels):
return (cal_info_gain(feat_values,labels) + 0.01)/(cal_entropy(feat_values)+0.01)
# 生成决策树中的第二个终止条件满足时,返回实例数最大的类
def get_max_label(labels):
return Counter(labels)[0][0]
# 选择信息增益、信息增益比最大的特征
def get_best_feat(feat_matrix,labels):
feat_num = feat_matrix.shape[1]
best_feat_idx = -1
max_info_gain = 0.0
ret_sign = 'discrete' # 默认是离散的
for feat_idx in range(feat_num):
feat_values = feat_matrix[:,feat_idx]
info_gain,sign = cal_info_gain(feat_values,labels)
if info_gain >= max_info_gain:
max_info_gain = info_gain
best_feat_idx = feat_idx
ret_sign = sign
return best_feat_idx,ret_sign
# 根据选定特征,划分得到子集
def get_subset(feat_matrix,labels,best_feat,sign):
feat_values = feat_matrix[:,best_feat]
if sign == 'discrete':
values_set = set(feat_values)
feat_matrix = np.delete(feat_matrix,best_feat,1)
feat_matrixset = {}
labelsset = {}
for value in values_set:
feat_matrixset[value] = feat_matrix[feat_values==value]
labelsset[value] = labels[feat_values==value]
# 连续值
else:
threshold = sign
feat_matrixset = {}
labelsset = {}
# 左
filter_left = feat_values <= threshold
feat_matrixset['<={}'.format(threshold)] = feat_matrix[filter_left]
labelsset['<={}'.format(threshold)] = labels[filter_left]
# 右
filter_right = feat_values > threshold
feat_matrixset['>{}'.format(threshold)] = feat_matrix[filter_right]
labelsset['>{}'.format(threshold)] = labels[filter_right]
return feat_matrixset,labelsset
"""
introduction:
生成一棵决策树
parameter:
feat_matrix:特征矩阵
labels:类别标签
feat_names:特征名称
method:选择方法(信息增益、信息增益比)
"""
def create_decision_tree(feat_matrix,labels,feat_names,method):
# 首先考虑两种终止条件:1、类别标签只有一种类型 2、特征没有其他取值
if len(set(labels)) == 1:
return labels[0] # 类型为numpy.int32
if feat_matrix.shape[0] == 0:
return get_max_label(labels)
# 选择信息增益最大的特征,sign标志着是离散特征还是连续特征,若连续,sign为阈值
best_feat,sign = get_best_feat(feat_matrix,labels)
best_feat_name = feat_names[best_feat]
# 初始化树
decision_tree = {best_feat_name:{}}
# 如果是离散的,则要删除该特征,否则不删。思考:连续特征何时删?当
if sign == 'discrete':
feat_names = np.delete(feat_names,best_feat)
# 得到子集(得到字典类型的子集,键为选定特征的不同取值)
feat_matrixset, labelsset = get_subset(feat_matrix,labels,best_feat,sign)
# 递归构造子树
for value in feat_matrixset.keys():
decision_tree[best_feat_name][value] = create_decision_tree(feat_matrixset[value],labelsset[value],feat_names,method)
return decision_tree
if __name__ == "__main__":
feat_matrix,labels,feat_names = get_data()
decision_tree = create_decision_tree(feat_matrix,labels,feat_names,method='ID3')
print(decision_tree)
#createPlot(decision_tree)
- 使用决策树进行异常点判断
3.3 基于Distance-Based算法的异常检查方法
同样使用3.1的Point.java, DistanceCompute.java
除此之外
package ch2;
/**
* @author Shihan Fu
* @version 1.0
* This is the distance-based method
* update 0611
*/
import java.io.File;
import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.Scanner;
public class DistanceBased {
public static void main(String[] args) {
//存放所有点
ArrayList<Point> dataSet = new ArrayList<Point>();
//存放异常点
ArrayList<Point> outlier = new ArrayList<Point>();
// 创建目录
File file = new File("C:\\Users\\lenovo\\Desktop\\第二章大作业\\测试数据.csv");
Scanner sc;
int line=0;
try {
sc = new Scanner(file);
String str;
while (sc.hasNext()) {
str=sc.nextLine();//按行读取文件
if(line!=0) {
dataSet.add(new Point(str));
}
line++;//实际数据行数line-1
}
sc.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
DistanceCompute dc = new DistanceCompute();
double dist=0;
double r=0.1;//一个一个试出来的0.1的表现最好
double pai=0.1;
int count=0;
boolean isOutlier=true;
for(int i=0;i<line-1;i++) {
count=0;
isOutlier=true;
for(int j=0;j<line-1;j++) {
dist=dc.getEuclideanDis(dataSet.get(i), dataSet.get(j));
if((i!=j)&&(dist<=r)) {
count++;
if(count>=(line-1)*pai) {
isOutlier=false;
break;
}
}
}
if(isOutlier==true) {
outlier.add(dataSet.get(i));
}
}
double correct=0.0;
//一共检测出多少个异常点
System.out.println("异常点数量:"+outlier.size());
for (Point point : outlier) {
if(point.getStatus()==true) {
correct++;
}
}
int hasAnomaly=0;
for(Point point : dataSet) {
if(point.getStatus()==true) {
hasAnomaly++;
}
}
System.out.println("检出率:"+correct/hasAnomaly);
System.out.println("准确率:"+correct/outlier.size());
}
}
需要不断调参。















 7931
7931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









