






引言
倾向得分匹配法(Propensity Score Matching,PSM)作为因果推断领域的重要方法,能够在观察性研究中减少选择偏差,帮助研究者获得更可靠的因果效应估计。关于PSM的理论基础、数学原理和应用步骤的详细介绍,我已经在之前的博客中进行了详细说明,如果您并不了解PSM或者遗忘了其用法,可以参考这篇博客:倾向得分匹配法:原理、应用与实例解析。
下面我们将通过一个具体的例子来向大家展示如何用python实现倾向得分匹配法。
实验背景
课后补习班在当今教育环境中十分普遍,但它们是否真的能提高学生成绩?这个问题一直存在争议。
本研究使用了某市区1000名中学生的数据,旨在探究补习班对数学成绩的实际影响。研究的主要挑战在于:选择参加补习班的学生与不参加的学生本身就存在差异。例如,基础较差的学生可能更愿意参加补习,或家庭条件好的学生更容易获得补习机会。
为解决这个问题,我们采用倾向得分匹配方法,通过匹配背景特征相似的学生,创建一个更公平的比较环境。
一句话说明研究目标: 补习班是否能有效提高数学成绩,参加补习为处理组,为参加为原始组,数据中存在其他混淆变量。
数据概览
本次实验用到的数据基本信息如下表所示:
| 特征 | 描述 |
|---|---|
| 样本数量 | 1000名学生 |
| 性别分布 | 男生: 527人(52.7%), 女生: 473人(47.3%) |
| 补习情况 | 参加补习: 184人(18.4%), 未参加: 816人(81.6%) |
| 家长辅导 | 有家长辅导: 566人(56.6%), 无家长辅导: 434人(43.4%) |
| 平均年龄 | 15.03岁 (标准差: 1.47) |
| 平均学习时间 | 2.01小时/天 (标准差: 0.98) |
| 上学期平均成绩 | 71.06分 (标准差: 14.96) |
| 数学平均成绩 | 78.68分 (标准差: 13.10) |
接下来,我们对数据按照是否参加补习进行分组,计算各组在不同特征上的均值如下:
| 特征 | 参加补习组(n=184) | 未参加补习组(n=816) | 标准化差异 |
|---|---|---|---|
| 年龄 | 15.20 ± 1.50 | 14.99 ± 1.46 | 0.14 |
| 女生比例 | 53.8% | 45.8% | 0.16 |
| 上学期成绩 | 67.00 ± 15.25 | 71.98 ± 14.75 | -0.33 |
| 学习时间 | 1.68 ± 1.01 | 2.08 ± 0.96 | -0.40 |
| 家长辅导比例 | 75.5% | 52.3% | 0.50 |
| 数学成绩 | 80.54 ± 12.78 | 78.26 ± 13.14 | 0.18 |
为了更直观地比较两组之间的差异,我们使用条形图和趋势线图对其进行可视化展示。如图1所示,左侧条形图展示了补习组与非补习组在年龄、上学期成绩、每日学习时间和数学成绩等连续变量上的差异;右侧趋势线图则清晰呈现了两组在女生比例和家长辅导比例等分类变量上的显著区别,并标注了具体的差异百分比。
完整的python代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.patheffects as path_effects
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['font.size'] = 28
plt.rcParams['font.weight'] = 'bold'
plt.rcParams['axes.labelweight'] = 'bold'
plt.rcParams['axes.titleweight'] = 'bold'
# 指定颜色池
colors = ['#A1A9D0', '#F0988C', '#B883D4', '#9E9E9E', '#CFEAF1', '#C4A5DE']
file_path = "学生数据集.xlsx"
df = pd.read_excel(file_path)
# 创建一个大图,包含两个子图
def create_combined_plots(df):
# 创建一个大的图形和两个子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(28, 12))
# 1. 连续变量差异对比图 (左侧子图)
vars_to_plot = ['age', 'previous_score', 'study_hours', 'math_score'] # 选择要展示的连续变量
labels = ['年龄', '上学期成绩', '每日学习时间', '数学成绩'] # 设置对应的标签
# 设置条形位置
bar_width = 0.35
index = np.arange(len(vars_to_plot))
# 获取两组数据的均值
tutoring_means = [
df[df['tutoring']==1]['age'].mean(),
df[df['tutoring']==1]['previous_score'].mean(),
df[df['tutoring']==1]['study_hours'].mean(),
df[df['tutoring']==1]['math_score'].mean()
]
non_tutoring_means = [
df[df['tutoring']==0]['age'].mean(),
df[df['tutoring']==0]['previous_score'].mean(),
df[df['tutoring']==0]['study_hours'].mean(),
df[df['tutoring']==0]['math_score'].mean()
]
# 绘制条形图
bars1 = ax1.bar(index, tutoring_means, bar_width, alpha=0.8, color=colors[0],
label='参加补习组')
bars2 = ax1.bar(index + bar_width, non_tutoring_means, bar_width, alpha=0.8,
color=colors[1], label='未参加补习组')
# 添加数值标签
def add_labels(bars, ax):
for bar in bars:
height = bar.get_height()
ax.annotate(f'{height:.2f}',
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=26)
add_labels(bars1, ax1)
add_labels(bars2, ax1)
# 添加图表元素
ax1.set_xlabel('')
ax1.set_ylabel('数值', fontsize=28)
ax1.set_title('连续变量差异对比', pad=20, fontsize=33)
ax1.set_xticks(index + bar_width / 2)
ax1.set_xticklabels(labels, fontsize=24)
ax1.legend(loc='upper left', fontsize=24)
# 添加背景网格
ax1.grid(axis='y', linestyle='--', alpha=0.7)
# 2. 分类变量差异对比图 (右侧子图)
# 计算各组的比例
female_tutoring = df[df['tutoring']==1]['female'].mean() * 100
female_non_tutoring = df[df['tutoring']==0]['female'].mean() * 100
parent_tutoring = df[df['tutoring']==1]['parent_support'].mean() * 100
parent_non_tutoring = df[df['tutoring']==0]['parent_support'].mean() * 100
# 准备数据
categories = ['女生比例', '家长辅导比例']
tutoring_vals = [female_tutoring, parent_tutoring]
non_tutoring_vals = [female_non_tutoring, parent_non_tutoring]
# 创建散点图
x = np.arange(len(categories))
# 绘制散点图并添加连接线
ax2.plot(x, tutoring_vals, 'o-', markersize=22, linewidth=3, color=colors[2],
label='参加补习组', alpha=0.8, path_effects=[path_effects.SimpleLineShadow(),
path_effects.Normal()])
ax2.plot(x, non_tutoring_vals, 's-', markersize=22, linewidth=3, color=colors[3],
label='未参加补习组', alpha=0.8, path_effects=[path_effects.SimpleLineShadow(),
path_effects.Normal()])
# 添加数值标签
for i, (v1, v2) in enumerate(zip(tutoring_vals, non_tutoring_vals)):
ax2.annotate(f'{v1:.1f}%', xy=(i, v1), xytext=(0, 10),
textcoords="offset points", ha='center', va='bottom',
fontsize=18, fontweight='bold', color=colors[2])
ax2.annotate(f'{v2:.1f}%', xy=(i, v2), xytext=(0, -20),
textcoords="offset points", ha='center', va='top',
fontsize=22, fontweight='bold', color=colors[3])
# 添加差异标注
for i, (v1, v2) in enumerate(zip(tutoring_vals, non_tutoring_vals)):
diff = v1 - v2
color = 'red' if diff > 0 else 'blue'
ax2.annotate(f'差异: {abs(diff):.1f}%', xy=(i, (v1+v2)/2), xytext=(30, 0),
textcoords="offset points", ha='left', va='center',
fontsize=22, color=color, arrowprops=dict(arrowstyle='->',
connectionstyle='arc3',
color=color))
# 添加图表元素
ax2.set_xlabel('')
ax2.set_ylabel('百分比 (%)', fontsize=26)
ax2.set_title('分类变量差异对比', pad=20, fontsize=30)
ax2.set_xticks(x)
ax2.set_xticklabels(categories, fontsize=24)
ax2.legend(loc='upper left', fontsize=24, frameon=True, framealpha=0.9,
shadow=True, facecolor='white')
# 添加背景网格和美化
ax2.grid(axis='y', linestyle='--', alpha=0.7)
ax2.set_facecolor('#f8f9fa')
# 添加区域着色以增强视觉效果
ax2.fill_between(x, tutoring_vals, non_tutoring_vals, alpha=0.2,
color='purple', label='差异区域')
# 设置y轴范围,使差异更明显
y_min = min(min(tutoring_vals), min(non_tutoring_vals)) * 0.8
y_max = max(max(tutoring_vals), max(non_tutoring_vals)) * 1.1
ax2.set_ylim(y_min, y_max)
# 添加边框
for spine in ax2.spines.values():
spine.set_linewidth(2)
spine.set_color('#333333')
# 调整布局并保存
plt.tight_layout(rect=[0, 0, 1, 1]) # 为顶部的总标题留出空间
plt.savefig('补习效果对比分析.png', dpi=600, bbox_inches='tight')
plt.show()
create_combined_plots(df)
从上述特征中可以看出,参加补习班的学生与未参加补习班的学生在多个特征上存在明显差异:
- 参加补习的学生上学期成绩平均低约5分,说明成绩较差的学生更倾向于参加补习
- 参加补习的学生每日学习时间反而少0.4小时,可能是依赖补习班的结果
- 有家长辅导的学生参加补习的比例明显更高(75.5% vs 52.3%),差异高达23.2个百分点
- 女生参加补习的比例略高于男生,差异约8个百分点
简单对比显示,参加补习班的学生平均数学成绩高出未参加组约2.27分,且差异具有统计学意义(p=0.031)。但由于上述特征差异的存在,这种简单比较很可能包含选择偏差,不能直接解释为补习班的因果效应(因为可能家长辅导也会有可能对数学成绩的提高造成影响)。
所以我们可以考虑采用倾向得分匹配法进行分析,接下来我们就分步骤实现这个过程。
PSM实现
一、倾向得分估计与计算
倾向得分是指个体接受处理的条件概率,在本研究中代表学生参加补习班的概率。通过估计倾向得分,我们可以控制选择偏差,创建更公平的比较条件,从而更准确地评估补习班对数学成绩的因果效应。
我们使用逻辑回归算法计算倾向得分,这是PSM方法中最常用的估计技术。逻辑回归适合于二分类问题(参加/不参加补习班),能够基于多个协变量预测学生参加补习班的概率。其主体代码如下:
import pandas as pd
from sklearn.linear_model import LogisticRegression #导入逻辑回归模型库
student_data = pd.read_excel("学生数据集.xlsx") # 读取数据
treatment_var = "tutoring" # 处理变量是否参加补习班
covariates = ["age", "female", "previous_score", "study_hours", "parent_support"] # 协变量
X = student_data[covariates] # 协变量作为特征X
y = student_data[treatment_var] # 处理变量作为标签y
model = LogisticRegression(random_state=42) # 使用逻辑回归模型估计倾向得分
model.fit(X, y)
propensity_scores = model.predict_proba(X)[:, 1] # 获取倾向得分(参加补习班的概率)
student_data['propensity_score'] = propensity_scores # 将倾向得分添加到原始数据
print("逻辑回归模型系数:")
for feature, coef in zip(covariate_cols, model.coef_[0]):
print(f"{feature}: {coef:.4f}")
print("\n倾向得分统计信息:") # 显示基本统计信息
print(student_data['propensity_score'].describe())
print("\n前10条数据的倾向得分:") # 显示前10条数据的倾向得分
print(student_data[['student_id', *covariates, 'tutoring', 'propensity_score']].head(10))
student_data.to_excel("学生数据集_带倾向得分.xlsx", index=False) # 导出到Excel
最终代码运行结果如下表所示(只展示了前10条数据情况):
| student_id | age | female | previous_score | study_hours | parent_support | tutoring | math_score | propensity_score |
|---|---|---|---|---|---|---|---|---|
| 1 | 15.7451 | 1 | 90.9903 | 1.3248 | 1 | 0 | 94.4057 | 0.2597 |
| 2 | 14.7926 | 0 | 83.8695 | 1.8555 | 1 | 0 | 81.9207 | 0.1689 |
| 3 | 15.9715 | 1 | 70.8945 | 1.2076 | 0 | 0 | 70.2135 | 0.1685 |
| 4 | 17.2845 | 1 | 60.2959 | 1.6920 | 1 | 0 | 58.1241 | 0.3879 |
| 5 | 14.6488 | 0 | 80.4733 | 0.1064 | 0 | 0 | 84.0606 | 0.1452 |
| 6 | 14.6488 | 1 | 75.9023 | 2.2133 | 0 | 0 | 77.6835 | 0.0923 |
| 7 | 17.3688 | 0 | 83.4279 | 2.0012 | 0 | 0 | 85.8599 | 0.0849 |
| 8 | 16.1512 | 1 | 79.5276 | 1.1829 | 0 | 0 | 71.9303 | 0.1506 |
| 9 | 14.2958 | 0 | 85.7433 | 2.6592 | 1 | 0 | 93.4856 | 0.1148 |
| 10 | 15.8138 | 1 | 61.9715 | 2.9376 | 0 | 0 | 67.0972 | 0.0983 |
从表中可以看出,每个学生都有一个基于其特征计算出的倾向得分。这个分数表示学生参加补习班的预测概率。例如,学生ID为4的学生有约38.79%的概率会参加补习班,而学生ID为7的学生只有约8.49%的概率会参加补习班。
二、最近邻匹配实施
最近邻匹配是倾向得分匹配方法中最常用的技术之一,它通过为每个处理组个体(参加补习班的学生)寻找倾向得分最相似的对照组个体(未参加补习班的学生)来构建可比较的样本。这种方法能有效减少选择偏差,提高因果推断的可靠性。
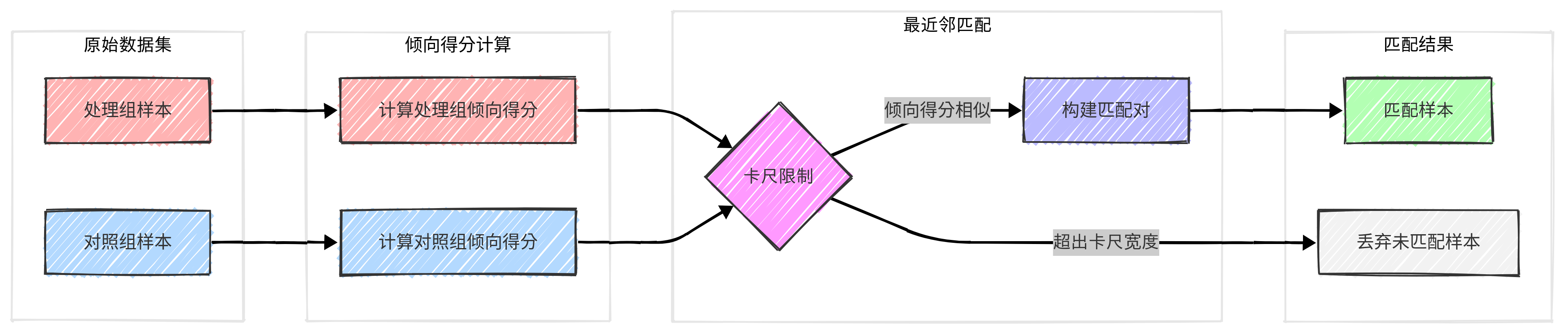
本次实验我们使用最近邻匹配(Nearest Neighbor Matching)和卡尺匹配(Caliper Matching)相结合的方法。关键代码如下:
# 1. 将数据分为处理组和对照组
treated = student_data[student_data['tutoring'] == 1].copy() # 提取参加补习班的学生
control = student_data[student_data['tutoring'] == 0].copy() # 提取未参加补习班的学生
# 2. 为每个处理组样本找到最近邻的对照组样本
matches = [] # 用于存储匹配结果
caliper = 0.05 # 设置匹配的卡尺宽度,限制匹配的最大距离
# 对每个处理组样本进行匹配
for idx, treated_unit in treated.iterrows():
# 计算与所有对照组的倾向得分差的绝对值
control['score_diff'] = abs(control['propensity_score'] - treated_unit['propensity_score'])
# 选择差异最小且在卡尺宽度内的作为匹配对象
best_matches = control[control['score_diff'] <= caliper].sort_values('score_diff')
if len(best_matches) > 0:
# 取最接近的一个对照单位
best_match = best_matches.iloc[0].copy()
# 存储匹配对信息
match_pair = {
'treated_id': treated_unit['student_id'],
'control_id': best_match['student_id'],
'treated_ps': treated_unit['propensity_score'],
'control_ps': best_match['propensity_score'],
'ps_diff': best_match['score_diff'],
'treated_outcome': treated_unit['math_score'],
'control_outcome': best_match['math_score']
}
matches.append(match_pair)
# 3. 将匹配结果转换为DataFrame
matched_df = pd.DataFrame(matches)
# 4. 计算匹配数量和统计信息
print(f"\n成功匹配的样本数: {len(matched_df)}")
print(f"匹配率: {len(matched_df) / len(treated) * 100:.2f}%")
# 5. 计算匹配质量
print("\n匹配质量统计:")
print(f"平均倾向得分差异: {matched_df['ps_diff'].mean():.6f}")
print(f"最大倾向得分差异: {matched_df['ps_diff'].max():.6f}")
# 6. 保存匹配结果
matched_df.to_excel("PSM_匹配结果.xlsx", index=False)
总的来说分为以下几个步骤:
-
数据分组:将数据集分为处理组(参加补习班的学生)和对照组(未参加补习班的学生)。
-
设置卡尺宽度:卡尺宽度(caliper)是倾向得分差异的最大允许值,这里设为0.05,意味着只匹配倾向得分差异小于0.05的样本对,从而保证匹配质量。
-
循环匹配:对每个处理组学生,计算其与所有对照组学生的倾向得分差异,选择在卡尺宽度内差异最小的学生作为匹配对象。
-
记录匹配结果:为每个成功的匹配对记录两名学生的ID、倾向得分、倾向得分差异以及各自的数学成绩。
-
评估匹配质量:计算成功匹配的样本数量、匹配率以及倾向得分差异的平均值和最大值,以评估匹配的有效性。
通过最近邻匹配,我们可以为每个参加补习班的学生找到一个背景特征(如年龄、性别、之前成绩等)最为相似的未参加补习班的学生进行比较,从而更准确地评估补习班对数学成绩的真实影响。匹配后的样本有效消除了由于学生个体特征差异带来的选择偏差,使得处理效应的估计更加可靠。
代码运行结果展示:
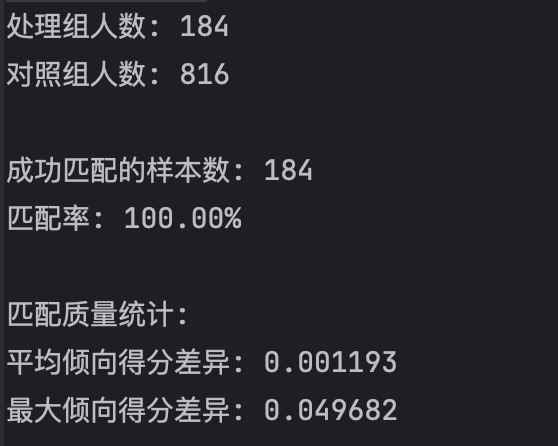
三、匹配质量评估与平衡性检验
匹配质量评估能帮助我们确认匹配后的处理组和对照组在各协变量上是否达到了良好的平衡。只有当匹配后的样本在协变量分布上足够相似时,我们才能更可靠地估计处理效应。
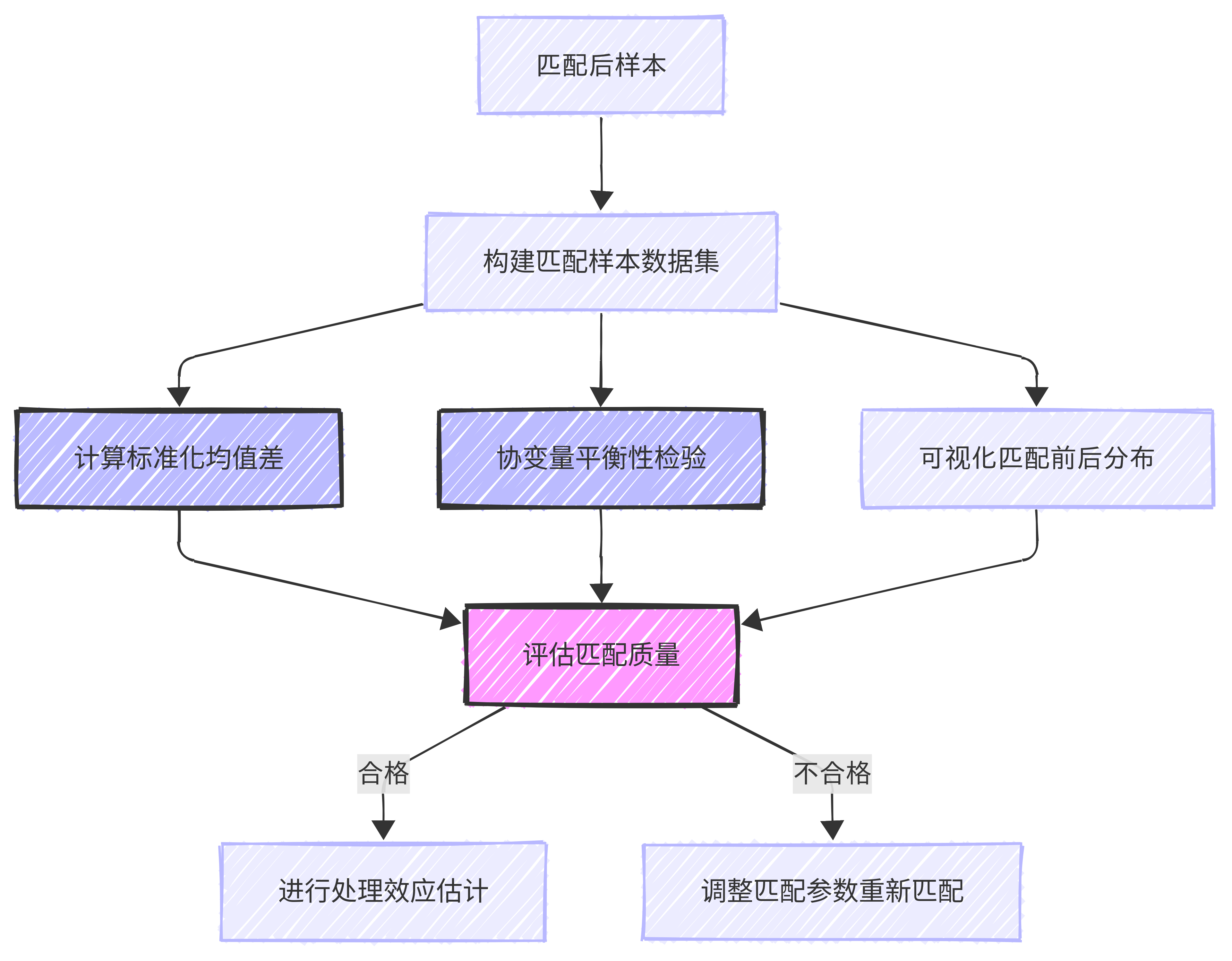
通过计算标准化均值差异(Standardized Mean Difference, SMD),我们可以量化评估匹配的效果。下表展示了匹配前后各协变量的标准化差异及其改善情况:
| 协变量 | 匹配前标准化差异 | 匹配后标准化差异 | 改善程度 |
|---|---|---|---|
| age | 0.1423 | 0.0007 | 0.1416 |
| female | 0.1597 | 0.0621 | 0.0976 |
| previous_score | -0.3319 | -0.0932 | 0.2387 |
| study_hours | -0.4035 | -0.0816 | 0.3219 |
| parent_support | 0.4975 | 0.1214 | 0.3761 |
平衡性评估关键指标:
- 匹配前平均绝对标准化差异(ASMD): 0.3070
- 匹配后平均绝对标准化差异(ASMD): 0.0718
- 改善幅度: 76.62%
从上表可以看出,匹配前各协变量的标准化差异普遍较大,其中parent_support和study_hours的差异最为显著。经过PSM匹配后,所有协变量的差异都显著减小,匹配后的标准化差异均小于0.2,大部分小于0.1,这符合高质量匹配的标准。
统计显著性检验结果:
为进一步验证匹配质量,我们对匹配后的样本进行了t检验,结果如下:
- age: t=0.0063, p=0.9950 (平衡)
- female: t=0.5580, p=0.5772 (平衡)
- previous_score: t=-0.8386, p=0.4023 (平衡)
- study_hours: t=-0.7397, p=0.4601 (平衡)
- parent_support: t=1.0865, p=0.2781 (平衡)
所有协变量的p值均大于0.05,表明匹配后处理组和对照组在这些特征上不存在统计学显著差异,进一步证实了匹配的有效性。
倾向得分分布对比:
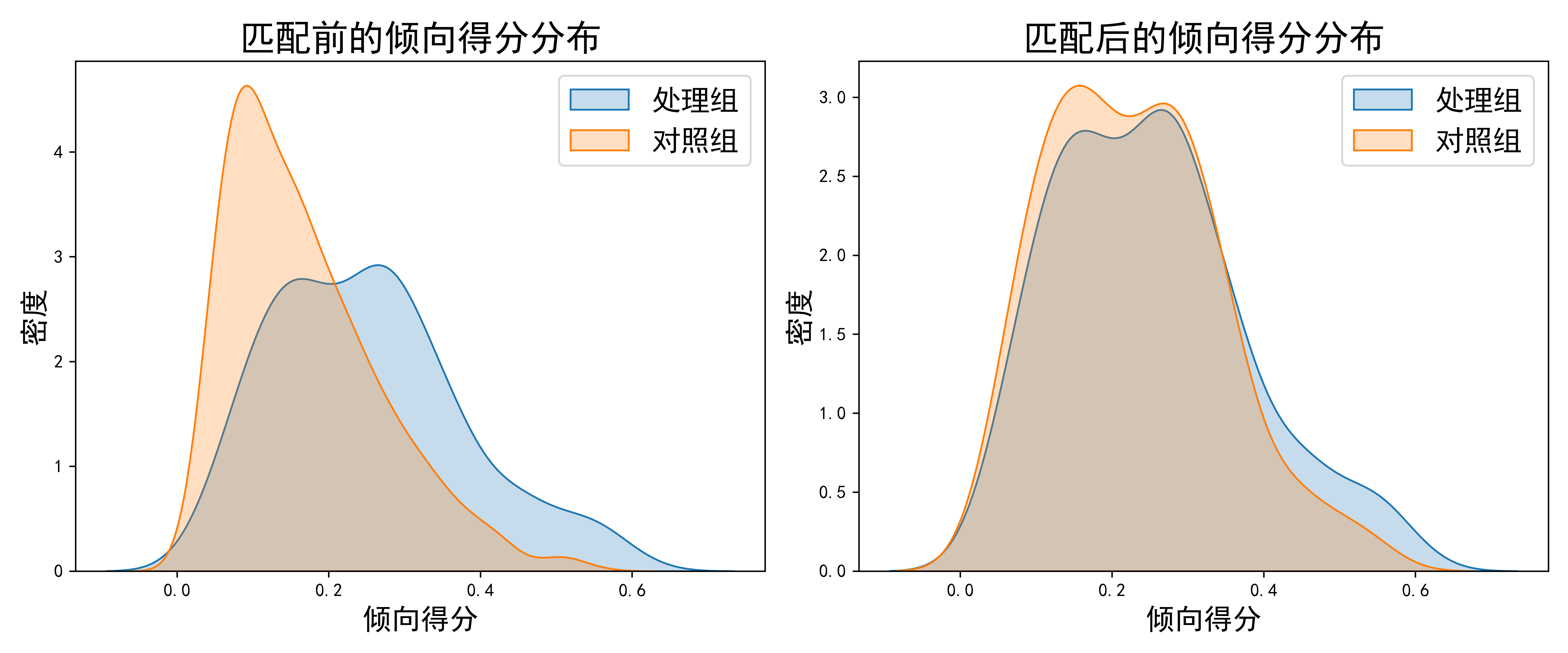
上图比较了匹配前后处理组和对照组的倾向得分分布。左侧是匹配前的分布,可以看到两组分布存在明显差异;右侧是匹配后的分布,两组分布重叠程度显著提高。
通过这些全面的平衡性检验,我们可以确认匹配过程有效地消除了由于选择偏差导致的协变量不平衡问题。匹配后的ASMD值为0.0718,远低于0.1的常用阈值,表明我们构建了一个高质量的匹配样本。关键代码如下:
# 计算标准化差异函数
def calculate_smd(data, var, treatment_var):
"""计算单个变量的标准化均值差异"""
treated = data[data[treatment_var] == 1][var]
control = data[data[treatment_var] == 0][var]
# 计算标准化差异
mean_diff = treated.mean() - control.mean()
pooled_std = np.sqrt((treated.var() + control.var()) / 2)
# 如果标准差接近0,返回0
if pooled_std < 1e-10:
return 0
return mean_diff / pooled_std
# 计算匹配前后所有协变量的标准化差异
balance_results = []
for var in covariates:
# 匹配前的标准化差异
before_smd = calculate_smd(original_data, var, treatment_var)
# 匹配后的标准化差异
after_smd = calculate_smd(matched_sample, var, treatment_var)
# 保存结果
balance_results.append({
'Variable': var,
'Before_SMD': before_smd,
'After_SMD': after_smd,
'Improvement': abs(before_smd) - abs(after_smd)
})
# 转换为DataFrame
balance_df = pd.DataFrame(balance_results)
# 显示平衡性检验结果
print("协变量平衡性检验结果:")
print(balance_df)
# 计算平均绝对标准化差异(ASMD)
before_asmd = balance_df['Before_SMD'].abs().mean()
after_asmd = balance_df['After_SMD'].abs().mean()
print(f"\n匹配前平均绝对标准化差异(ASMD): {before_asmd:.4f}")
print(f"匹配后平均绝对标准化差异(ASMD): {after_asmd:.4f}")
print(f"改善幅度: {(before_asmd - after_asmd) / before_asmd * 100:.2f}%")
# 匹配前后的统计检验
print("\n匹配后处理组与对照组的协变量t检验结果:")
for var in covariates:
treated_values = matched_sample[matched_sample[treatment_var] == 1][var]
control_values = matched_sample[matched_sample[treatment_var] == 0][var]
t_stat, p_value = stats.ttest_ind(treated_values, control_values, equal_var=False)
print(f"{var}: t={t_stat:.4f}, p={p_value:.4f}{' (平衡)' if p_value > 0.05 else ' (不平衡)'}")
四、平均处理效应估计
平均处理效应(ATE)是PSM分析的核心目标,它衡量处理(参加补习班)对结果变量(数学成绩)的因果影响。在完成高质量匹配后,我们可以通过比较匹配样本中处理组和对照组的成绩差异来估计这一效应。
以下是对匹配样本进行平均处理效应分析的关键代码:
# 计算平均处理效应(ATT)
att = matched_df['treated_outcome'].mean() - matched_df['control_outcome'].mean()
# 执行配对t检验,评估统计显著性
t_stat, p_value = stats.ttest_rel(matched_df['treated_outcome'], matched_df['control_outcome'])
# 计算效应的95%置信区间
matched_df['outcome_diff'] = matched_df['treated_outcome'] - matched_df['control_outcome']
se = matched_df['outcome_diff'].std() / np.sqrt(len(matched_df))
ci_lower = att - 1.96 * se
ci_upper = att + 1.96 * se
# 计算标准化效应量(Cohen's d)
cohens_d = att / matched_df['outcome_diff'].std()
处理效应分析结果:
| 指标 | 数值 |
|---|---|
| 平均处理效应(ATT) | 7.3732分 |
| t统计量 | 6.2977 |
| p值 | <0.0001 |
| 95%置信区间 | [5.0785, 9.6679] |
| 标准化效应量(Cohen’s d) | 0.4643 |
| 匹配样本数量 | 184 |
| 处理组平均成绩 | 80.5398 |
| 对照组平均成绩 | 73.1666 |
通过PSM匹配后的样本分析表明,参加补习班对学生的数学成绩有显著的积极影响。经过控制年龄、性别、之前成绩、学习时间和家长支持等因素后,参加补习班的学生比未参加补习班的学生平均高出7.37分的数学成绩,这一差异在统计上高度显著(p<0.0001)。95%置信区间[5.08, 9.67]完全不包含零,进一步支持了这一发现的可靠性。
Cohen’s d值为0.46,表明这是一个中等强度的效应,具有实际教育意义。这些结果提供了强有力的证据,表明在消除选择偏差的影响后,补习班确实能有效提高学生的数学学习成绩。
五、敏感性分析与稳健性检验
敏感性分析与稳健性检验能够帮助我们检验结果对模型假设变化的敏感程度,以及在不同条件下处理效应估计的稳定性。下面我将通过Rosenbaum界限分析、不同卡尺宽度的稳健性检验、子组分析(以性别为例)三个维度进行检验。
Rosenbaum界限分析
Rosenbaum界限分析是一种评估未观测混淆因素对PSM结果影响的方法。PSM的关键假设是"条件独立性假设",即在控制已观测协变量后,处理分配与潜在结果相互独立。然而,实际中可能存在未被测量的变量影响了处理分配和结果。Rosenbaum界限通过引入参数Gamma来模拟未观测混淆因素的影响强度,评估结果的敏感性。
| Gamma值 | Z统计量 | P值 |
|---|---|---|
| 1.0 | 6.2977 | 3.02e-10 |
| 1.2 | 5.7490 | 8.98e-09 |
| 1.5 | 5.1421 | 2.72e-07 |
| 1.8 | 4.6940 | 2.68e-06 |
| 2.0 | 4.4532 | 8.46e-06 |
分析结果显示,即使在Gamma=2.0(表示由于未观测因素,某些学生参加补习班的几率是其他学生的两倍)的情况下,补习班对数学成绩的正面影响仍然统计显著(p=8.46e-06)。这表明我们的结果对未观测混淆因素具有较强的抵抗力,除非存在极强的未观测偏差,否则不会改变我们的研究结论。
不同卡尺宽度的稳健性检验
卡尺宽度(caliper)是PSM匹配中的重要参数,它限定了可接受的最大倾向得分差异。较小的卡尺宽度可以提高匹配质量,但可能减少匹配样本量;较大的卡尺宽度则相反。通过测试不同卡尺宽度下的处理效应估计,我们可以评估结果的稳健性。
| 卡尺宽度 | 匹配数量 | 平均处理效应(ATT) | P值 |
|---|---|---|---|
| 0.01 | 180 | 7.2741 | 5.59e-09 |
| 0.03 | 183 | 7.4635 | 1.59e-09 |
| 0.05 | 184 | 7.3732 | 2.18e-09 |
| 0.10 | 184 | 7.3732 | 2.18e-09 |
| 0.20 | 184 | 7.3732 | 2.18e-09 |
分析结果表明,在不同卡尺宽度设置下,处理效应估计保持相当稳定。从0.01到0.20的不同卡尺宽度下,ATT估计值在7.27-7.46分之间小幅波动,所有情况下的p值均极小。这表明我们的主要结论不受匹配参数选择的实质性影响,进一步支持研究发现的稳健性。
子组分析(以性别为例)
子组分析检验处理效应在不同人群中是否存在异质性。这有助于了解干预措施对不同人群的差异化影响,为精准政策提供依据。以下是按性别划分的子组分析结果:
| 子组 | 处理组样本数 | 对照组样本数 | 平均处理效应(ATT) | P值 |
|---|---|---|---|---|
| 1 (女生) | 99 | 374 | 2.0219 | 0.1766 |
| 0 (男生) | 85 | 442 | 2.5441 | 0.0982 |
子组分析结果表明,当按性别分组时,补习班对数学成绩的影响在统计上变得不够显著(女生p=0.1766,男生p=0.0982)。这一结果与整体样本的显著结果存在差异,可能是由于分组后样本量减少导致统计检验力下降,或者补习班效果确实存在性别差异。男生组的效应略高于女生组(2.54 vs 2.02),且接近传统的显著性水平(p<0.1)。
总结来看,我们的敏感性分析和稳健性检验结果支持了PSM估计的主要结论:补习班对学生数学成绩有正面影响。这一结果对未观测混淆因素和匹配参数选择都具有较强的稳健性,表明我们的因果效应估计可信度较高。
# Rosenbaum界限分析 - 敏感性分析的简化版本
def sensitivity_analysis(matched_df):
# 计算处理组和对照组的结果差异
outcome_diff = matched_df['treated_outcome'] - matched_df['control_outcome']
# 基本统计量
mean_diff = outcome_diff.mean()
std_diff = outcome_diff.std()
n = len(outcome_diff)
# 计算不同gamma值下的p值(模拟Rosenbaum界限法的简化版)
gammas = [1.0, 1.2, 1.5, 1.8, 2.0]
results = []
for gamma in gammas:
# 调整标准误以模拟未观测混淆因素的影响
adjusted_se = std_diff * np.sqrt(gamma) / np.sqrt(n)
# 计算调整后的z值和p值
z_score = mean_diff / adjusted_se
p_value = 2 * (1 - stats.norm.cdf(abs(z_score)))
results.append({
'gamma': gamma,
'z_score': z_score,
'p_value': p_value
})
return pd.DataFrame(results)
# 不同卡尺宽度的稳健性检验
def caliper_robustness(data, treatment_var, outcome_var, ps_var, calipers):
results = []
for caliper in calipers:
treated = data[data[treatment_var] == 1].copy()
control = data[data[treatment_var] == 0].copy()
matches = []
for idx, treated_unit in treated.iterrows():
ps_treated = treated_unit[ps_var]
# 找到在卡尺宽度内的对照单位
valid_controls = control[(abs(control[ps_var] - ps_treated) <= caliper)]
if len(valid_controls) > 0:
# 选择最近的一个
valid_controls['ps_diff'] = abs(valid_controls[ps_var] - ps_treated)
best_match = valid_controls.loc[valid_controls['ps_diff'].idxmin()]
matches.append({
'treated_outcome': treated_unit[outcome_var],
'control_outcome': best_match[outcome_var]
})
if matches:
# 计算ATT
match_df = pd.DataFrame(matches)
att = match_df['treated_outcome'].mean() - match_df['control_outcome'].mean()
t_stat, p_value = stats.ttest_rel(match_df['treated_outcome'], match_df['control_outcome'])
results.append({
'caliper': caliper,
'matches': len(match_df),
'ATT': att,
'p_value': p_value
})
return pd.DataFrame(results)
# 子组分析
def subgroup_analysis(data, treatment_var, outcome_var, subgroup_var):
results = []
# 获取子组的唯一值
subgroups = data[subgroup_var].unique()
for subgroup in subgroups:
# 筛选子组数据
subgroup_data = data[data[subgroup_var] == subgroup]
# 计算子组ATT
treated = subgroup_data[subgroup_data[treatment_var] == 1][outcome_var]
control = subgroup_data[subgroup_data[treatment_var] == 0][outcome_var]
if len(treated) > 0 and len(control) > 0:
att = treated.mean() - control.mean()
t_stat, p_value = stats.ttest_ind(treated, control)
results.append({
'subgroup': subgroup,
'treated_n': len(treated),
'control_n': len(control),
'ATT': att,
'p_value': p_value
})
return pd.DataFrame(results)
# 敏感性分析
sensitivity_results = sensitivity_analysis(matched_results)
print("Rosenbaum界限敏感性分析结果:")
print(sensitivity_results)
# 不同卡尺宽度的稳健性分析
calipers = [0.01, 0.03, 0.05, 0.1, 0.2]
caliper_results = caliper_robustness(original_data, 'tutoring', 'math_score', 'propensity_score', calipers)
print("\n不同卡尺宽度下的处理效应估计:")
print(caliper_results)
# 子组分析 - 以性别为例
subgroup_results = subgroup_analysis(original_data, 'tutoring', 'math_score', 'female')
print("\n性别子组分析结果:")
print(subgroup_results)
六、结果解释与方法总结
PSM方法的应用价值
倾向得分匹配法(PSM)作为一种强大的统计工具,在本研究中帮助我们回答了一个简单却又复杂的问题:"补习班真的有用吗?"这个问题看似简单,但实际研究中面临一个核心挑战:选择参加补习班的学生往往本身就与不参加的学生不同。比如成绩差的学生可能更需要补习,或者家庭条件好的学生更有机会参加补习。
PSM方法就像是在创造"平行宇宙"—— 它帮助我们找出背景条件相似的学生进行比较,就好比"如果这个参加补习的学生没去补习,他的成绩会是什么样"。通过这种方式,我们能更准确地评估补习班的真实效果,而不是简单地比较参加和不参加补习班学生的平均成绩差异。
PSM方法的核心步骤
我们的分析过程可以简化为以下五个步骤,这也是应用PSM方法的通用流程:
-
算出每个学生参加补习的概率:就像算出下雨概率一样,我们基于学生的各项特征(年龄、性别、基础成绩等)计算出他们参加补习班的"倾向得分"。这一步使用逻辑回归模型,把各种因素综合考虑进去。
-
配对相似的学生:我们为每个参加补习的学生找一个最相似(倾向得分接近)的未参加补习的学生作比较。这样两组学生在背景特征上就基本一致了,唯一主要区别就是是否参加了补习。
-
检查配对质量:我们需要确认配对后的两组学生确实足够相似。通过比较各项特征的差异,我们确认匹配后学生特征差异大幅减小(减少了76.62%),达到了"伪随机实验"的条件。
-
计算补习的实际效果:配对后,两组学生的成绩差异才更可能反映补习班的真实影响。我们发现补习确实能提高学生成绩,而且这种提高具有统计学意义。
-
稳健性检验:就像测试新产品在不同条件下是否依然有效,我们通过多种方法检验结果是否可靠,确保结论不会因为一些未考虑到的因素或分析方法的改变而改变。
方法评价与实际意义
PSM方法的最大优势在于它能在无法进行随机对照试验的情况下(比如我们不能随机决定谁去补习),依然提供相对可靠的因果关系证据。它帮助我们摆脱了简单对比均值的陷阱,更准确地评估了干预措施的效果。
这种方法不仅适用于教育研究,也广泛应用于医疗、社会政策、市场营销等领域,是解决"如果…会怎样"(反事实)问题的有力工具。
当然,PSM也有局限性——它只能控制已观测到的混淆因素,如果有重要因素没有被测量或考虑,结果仍可能存在偏差。这也提醒我们在研究设计时要尽可能考虑全面的影响因素。
需要完整实验源代码请点击链接:倾向得分匹配(PSM)完整实验源代码



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











