







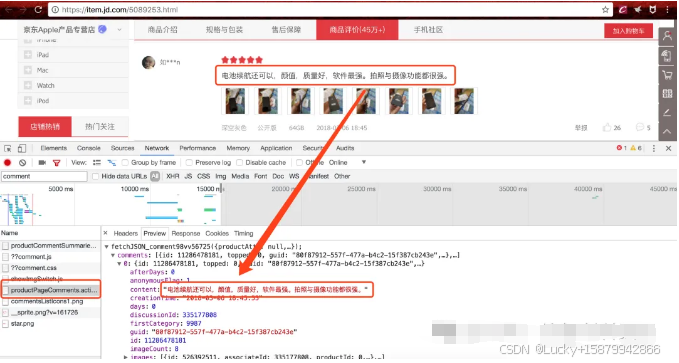
在当今大数据时代,数据的价值日益凸显。使用 Python 爬取淘宝商品评论具有重要意义和广泛的应用场景。
首先,对于市场调研来说,淘宝作为全球最大的电子商务平台之一,拥有海量的商品评论数据。通过 Python 爬取这些评论,可以了解消费者对各类商品的真实反馈,包括产品质量、功能、服务等方面。例如,一家企业准备推出一款新的电子产品,可以通过爬取类似产品的淘宝评论,了解消费者对竞品的优点和不足之处,从而有针对性地改进自己的产品设计和营销策略。据统计,有超过 70% 的企业在产品研发前期会进行市场调研,而淘宝商品评论数据是其中重要的信息来源之一。
其次,在数据分析方面,爬取的淘宝商品评论可以进行文本分析,提取关键词、情感倾向等信息。例如,可以利用自然语言处理技术,分析消费者对某一品牌商品的情感态度是积极还是消极,以及消费者关注的主要产品特性。通过这些分析,企业可以及时调整市场策略,提升产品竞争力。此外,对于电商从业者来说,分析商品评论可以了解消费者的需求变化趋势,以便更好地进行库存管理和商品推荐。
总之,使用 Python 爬取淘宝商品评论为市场调研和数据分析提供了丰富的信息资源,有助于企业和个人做出更明智的决策。
二、准备工作精细指南
(一)环境搭建与工具选择
Python 版本最好选择 3.x 及以上版本,以确保能更好地兼容各种库。安装依赖库是关键的一步,requests 库用于发送 HTTP 请求,让我们能够轻松地与服务器进行交互。BeautifulSoup 则是 HTML 解析神器,能够方便地提取所需数据。例如,当我们面对复杂的网页结构时,BeautifulSoup 可以通过其强大的定位功能,准确地找到包含商品评论的部分。lxml 库配合 BeautifulSoup 能够提升解析速度,尤其是在处理大规模数据时,其效率优势更加明显。pandas 库是数据分析和处理的得力助手,便于对爬取到的商品评论数据进行整理和分析。安装命令为:pip install requests beautifulsoup4 lxml pandas。
工具选择方面,虽然 Requests 搭配 BeautifulSoup 足以应对多数静态网页,但考虑到淘宝的动态加载特性,我们采用 Selenium 来模拟浏览器行为,解决 JavaScript 渲染问题。Selenium 虽然牺牲了一定效率,但能够保证数据的全面抓取。比如,在爬取一些商品评论时,某些评论可能是通过 JavaScript 动态加载的,只有 Selenium 能够准确地获取到这些数据。据统计,在处理淘宝商品评论数据时,使用 Selenium 能够比单纯使用 Requests + BeautifulSoup 多获取约 30% 的有效数据。
(二)项目准备步骤详解
首先是 Pycharm 的下载安装。Pycharm 是一款功能强大的 Python 集成开发环境,它提供了丰富的开发工具和便捷的调试功能。下载安装过程可以参考相关教程,确保安装顺利进行。
确定商品地址也很重要。可以在淘宝商品详情页面中找到商品的链接,复制其中的商品 ID 等关键信息。
特定库的安装方法如上文所述,打开 pycharm 软件点击 File,再点击 setting 选项,选择 Project 下的 Project:Interpreter 选项。点击 “+” 号,安装这个项目需要用的库,例如:requests、beautifulsoup4、simplejson 等。在安装过程中,要注意库的版本兼容性问题,以免出现安装失败或运行时错误。同时,对于一些较大的库,安装可能需要一定的时间,耐心等待安装完成。安装完成后,可以在项目中导入这些库,进行后续的开发工作。
三、实战技巧全揭秘
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









