









基于中文形近字相似度与加权编辑距离融合实现的汉字纠错算法
前言
以本篇文章记录自己在算法开发过程中----文本纠错 上遇到的问题及解决方法。
笔者调研了常用文本纠错工具及第三方库例如:pycorrector及mac-bert等,由于该库下的数据都是基于句子级文本训练得到的语言模型。
例> 我要配一副眼睛 ------------我要配一副眼镜 那么[睛,镜]是可以被纠错的。
但> 大和圩乡 ------------太和圩乡 使用该方式是无法进行纠错的。
所以在字粒度上的纠错效果并不好,更多依赖文本语义且速度较慢,故结合中文形近字相似度与加权编辑距离融合的方式来实现文本纠错。
那我们先了解一下什么是中文形近字算法与加权编辑距离
中文形近字相似度算法
首先国内对于文本的相似度计算,开源的工具是比较丰富的。但是对于两个汉字之间的相似度计算,国内基本一片空白。国内的参考的资料少的可怜,国外相关文档也是如此。故默认实现了基于 四角编码+汉字结构+汉字偏旁+笔画数 的相似度比较,当然如果有必要的话也可以引入汉语拼音。数据来源可以是:百度字典、人民日报词库、搜狗输入法词库、常用各种 NLP 比赛的词库、新华字典等。
什么是四角码
四角码是一种计算机四角汉字输入法,它包括:对汉字的编码和取码,以及与键盘的对应关系,其特征在于: 使用汉字的一些特定部首笔画作为代码,而这些代码分别与0、1、2、3……9十个数字相对应,然后,利用这些代码来拆解汉字的四个角,并以相应的数字作为编码来表示和区分汉字。
四角号码可以在线查询(四角号码查字法)收录了2万多个汉字的四角号码,支持汉字查询四角号码或通过四角号码反查汉字。
比如你不知道“四角号码”这几个汉字的四角号码是多少,在查询框中输入“四角号码”后按回车即可,即可查得这几个汉字分别的四角号码。
如果查询的字串中包含了非汉字字符,系统会自动将其滤掉,只列出其中包含的汉字的四角号码,非常方便实用。
四角号码,汉语词典常用检字方法之一,用最多5个阿拉伯数字来对汉字进行归类。
四角号码检字法由王云五发明,并在1925年5月著《号码检字法》由商务印书馆出版。四角号码检字法用数字0到9表示一个汉字四角的十种笔形,有时在最后增加一位补码。
四角号码检字法歌谣:横一垂二三点捺,叉四插五方框六;七角八八九是小,点下有横变零头。
取码规则
| 号码 | 名称 | 笔形 |
|---|---|---|
| 0 | 头 | 亠(独立的点横组合,横笔带折钩者不算。) |
| 1 | 横 | 一乚(横、挑、右钩) |
| 2 | 垂 | 丨丿亅(直、撇、左钩) |
| 3 | 点 | 丶(点、捺) |
| 4 | 叉 | 十乂(两笔相交叉) |
| 5 | 插 | 扌(一笔插入两笔以上,被插的笔画不算) |
| 6 | 方 | 口(四边齐整,笔端不外伸。) |
| 7 | 角 | ﹁「」﹂(横与垂相接处,但其两端不作角。) |
| 8 | 八 | 八丷人(两笔成八形,且不与他笔交叉。) |
| 9 | 小 | 小忄⺌(两笔中隔一笔成小形。中间有两笔,或有一旁有两笔不作小。) |
相关数据简单展示
1. 汉字笔画数
乙 1
乛 1
乚 1
丶 1
1
丩 2
乃 2
乂 2
乄 2
九 2
2. 汉字结构
黽 0
奭 0
龜 0
噩 0
巜 1
乆 1
劜 1
亿 1
乢 1
乣 1
切 1
刅 1
刈 1
3. 偏旁部首
攪 扌
攨 扌
攬 扌
攭 扌
攮 扌
氵 氵
汈 氵
氾 氵
氿 氵
汉 氵
汇 氵
4. 四角编码
胫 77212
胩 71231
胧 73214
胪 71207
脉 73292
胖 79250
胚 71219
胠 74232
朐 77220
胂 75206
胜 75210
胎 73260
胃 60227
形似字相似度算法完整代码
def initDict(path):
dict = {}
with open(path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f.readlines():
# 移除换行符,并且根据空格拆分
splits = line.strip('\n').split(' ')
key = splits[0]
value = splits[1]
dict[key] = value
return dict
# 字典初始化
bihuashuDict = initDict('./db/bihuashu_2w.txt')
hanzijiegouDict = initDict('./db/hanzijiegou_2w.txt')
pianpangbushouDict = initDict('./db/pianpangbushou_2w.txt')
sijiaobianmaDict = initDict('./db/sijiaobianma_2w.txt')
# 权重定义(可自行调整)
hanzijiegouRate = 10
sijiaobianmaRate = 8
pianpangbushouRate = 6
bihuashuRate = 2
# 计算核心方法
'''
desc: 笔画数相似度
'''
def bihuashuSimilar(charOne, charTwo):
valueOne = bihuashuDict[charOne]
valueTwo = bihuashuDict[charTwo]
numOne = int(valueOne)
numTwo = int(valueTwo)
diffVal = 1 - abs((numOne - numTwo) / max(numOne, numTwo))
return bihuashuRate * diffVal * 1.0
'''
desc: 汉字结构数相似度
'''
def hanzijiegouSimilar(charOne, charTwo):
valueOne = hanzijiegouDict[charOne]
valueTwo = hanzijiegouDict[charTwo]
if valueOne == valueTwo:
return hanzijiegouRate * 1
return 0
'''
desc: 四角编码相似度
'''
def sijiaobianmaSimilar(charOne, charTwo):
valueOne = sijiaobianmaDict[charOne]
valueTwo = sijiaobianmaDict[charTwo]
totalScore = 0.0
minLen = min(len(valueOne), len(valueTwo))
for i in range(minLen):
if valueOne[i] == valueTwo[i]:
totalScore += 1.0
totalScore = totalScore / minLen * 1.0
return totalScore * sijiaobianmaRate
'''
desc: 偏旁部首相似度
'''
def pianpangbushoutSimilar(charOne, charTwo):
valueOne = pianpangbushouDict[charOne]
valueTwo = pianpangbushouDict[charTwo]
if valueOne == valueTwo:
# 后续可以优化为字的拆分
return pianpangbushouRate * 1
return 0
'''
desc: 计算两个汉字的相似度
'''
def similar(charOne, charTwo):
if charOne == charTwo:
return 1.0
sijiaoScore = sijiaobianmaSimilar(charOne, charTwo)
jiegouScore = hanzijiegouSimilar(charOne, charTwo)
bushouScore = pianpangbushoutSimilar(charOne, charTwo)
bihuashuScore = bihuashuSimilar(charOne, charTwo)
totalScore = sijiaoScore + jiegouScore + bushouScore + bihuashuScore
totalRate = hanzijiegouRate + sijiaobianmaRate + pianpangbushouRate + bihuashuRate
result = totalScore * 1.0 / totalRate * 1.0
print('总分:' + str(totalScore) + ', 总权重: ' + str(totalRate) + ', 结果:' + str(result))
print('四角编码:' + str(sijiaoScore))
print('汉字结构:' + str(jiegouScore))
print('偏旁部首:' + str(bushouScore))
print('笔画数:' + str(bihuashuScore))
return result
if __name__ == '__main__':
similar(charOne, charTwo)
加权编辑距离算法
我们先了解一下什么是编辑距离。
编辑距离:是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。
也就是说:给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种编辑操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
有了这个基础的理解我们接下来了解一下加权与不加权的区别在哪里。
首先编辑距离权重即字符串之间添加、删除、修改字符的比重是一样的,但这其实是不太合理的。
比如ABC转换为ABV,我们只需要将字母C转换为字母V即可,我们记为编辑距离为1。
对于ABC转换为ABP,只需要将字母C转换为字母P即可,编辑距离也为1。
但我们知道,在键盘上字母C和字母V的距离很近,但字母C和字母P的距离很远,所以一个人将字母C误编辑为字母P的概率是比较低的。因此我们在之前的基础上添加加权的操作。
加权编辑距离算法代码
代码上可以选择自己编写也可以使用开源库,笔者这里使用的是开源库。
执行命令 pip install -U strsimpy导入格式如下
from strsimpy.weighted_levenshtein import WeightedLevenshtein
融合
首先形似字相似度算法返回的是一个相似度概率,我们需要将其概率作为权重融入至编辑距离算法中,所以我们需要修改加权编辑距离的源码。如下所示
from functools import reduce
from .string_distance import StringDistance
def initDict(path):
dict = {}
with open(path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f.readlines():
# 移除换行符,并且根据空格拆分
splits = line.strip('\n').split(' ')
key = splits[0]
value = splits[1]
dict[key] = value
return dict
# 字典初始化
bihuashuDict = initDict('./db/bihuashu_2w.txt')
hanzijiegouDict = initDict('./db/hanzijiegou_2w.txt')
pianpangbushouDict = initDict('./db/pianpangbushou_2w.txt')
sijiaobianmaDict = initDict('./db/sijiaobianma_2w.txt')
# 权重定义(可自行调整)
hanzijiegouRate = 10
sijiaobianmaRate = 8
pianpangbushouRate = 6
bihuashuRate = 2
# 计算核心方法
'''
desc: 笔画数相似度
'''
def bihuashuSimilar(charOne, charTwo):
valueOne = bihuashuDict[charOne]
valueTwo = bihuashuDict[charTwo]
numOne = int(valueOne)
numTwo = int(valueTwo)
diffVal = 1 - abs((numOne - numTwo) / max(numOne, numTwo))
return bihuashuRate * diffVal * 1.0
'''
desc: 汉字结构数相似度
'''
def hanzijiegouSimilar(charOne, charTwo):
valueOne = hanzijiegouDict[charOne]
valueTwo = hanzijiegouDict[charTwo]
if valueOne == valueTwo:
# 后续可以优化为相近的结构
return hanzijiegouRate * 1
return 0
'''
desc: 四角编码相似度
'''
def sijiaobianmaSimilar(charOne, charTwo):
valueOne = sijiaobianmaDict[charOne]
valueTwo = sijiaobianmaDict[charTwo]
totalScore = 0.0
minLen = min(len(valueOne), len(valueTwo))
for i in range(minLen):
if valueOne[i] == valueTwo[i]:
totalScore += 1.0
totalScore = totalScore / minLen * 1.0
return totalScore * sijiaobianmaRate
'''
desc: 偏旁部首相似度
'''
def pianpangbushoutSimilar(charOne, charTwo):
valueOne = pianpangbushouDict[charOne]
valueTwo = pianpangbushouDict[charTwo]
if valueOne == valueTwo:
# 后续可以优化为字的拆分
return pianpangbushouRate * 1
return 0
'''
desc: 计算两个汉字的相似度
'''
def similar(charOne, charTwo):
if charOne == charTwo:
return 1.0
sijiaoScore = sijiaobianmaSimilar(charOne, charTwo)
jiegouScore = hanzijiegouSimilar(charOne, charTwo)
bushouScore = pianpangbushoutSimilar(charOne, charTwo)
bihuashuScore = bihuashuSimilar(charOne, charTwo)
totalScore = sijiaoScore + jiegouScore + bushouScore + bihuashuScore
totalRate = hanzijiegouRate + sijiaobianmaRate + pianpangbushouRate + bihuashuRate
result = totalScore * 1.0 / totalRate * 1.0
# print('总分:' + str(totalScore) + ', 总权重: ' + str(totalRate) + ', 结果:' + str(result))
# print('四角编码:' + str(sijiaoScore))
# print('汉字结构:' + str(jiegouScore))
# print('偏旁部首:' + str(bushouScore))
# print('笔画数:' + str(bihuashuScore))
return result
def default_insertion_cost(char):
return 1.0
def default_deletion_cost(char):
return 1.0
def default_substitution_cost(char_a, char_b):
# print(char_a, char_b,similar(char_a, char_b))
return 1-similar(char_a, char_b)
class WeightedLevenshtein(StringDistance):
def __init__(self,
substitution_cost_fn=default_substitution_cost,
insertion_cost_fn=default_insertion_cost,
deletion_cost_fn=default_deletion_cost,
):
self.substitution_cost_fn = substitution_cost_fn
self.insertion_cost_fn = insertion_cost_fn
self.deletion_cost_fn = deletion_cost_fn
def distance(self, s0, s1):
if s0 is None:
raise TypeError("Argument s0 is NoneType.")
if s1 is None:
raise TypeError("Argument s1 is NoneType.")
if s0 == s1:
return 0.0
if len(s0) == 0:
return reduce(lambda cost, char: cost + self.insertion_cost_fn(char), s1, 0)
if len(s1) == 0:
return reduce(lambda cost, char: cost + self.deletion_cost_fn(char), s0, 0)
v0, v1 = [0.0] * (len(s1) + 1), [0.0] * (len(s1) + 1)
v0[0] = 0
for i in range(1, len(v0)):
v0[i] = v0[i - 1] + self.insertion_cost_fn(s1[i - 1])
for i in range(len(s0)):
s0i = s0[i]
deletion_cost = self.deletion_cost_fn(s0i)
v1[0] = v0[0] + deletion_cost
for j in range(len(s1)):
s1j = s1[j]
cost = 0
if s0i != s1j:
cost = self.substitution_cost_fn(s0i, s1j)
insertion_cost = self.insertion_cost_fn(s1j)
v1[j + 1] = min(v1[j] + insertion_cost, v0[j + 1] + deletion_cost, v0[j] + cost)
v0, v1 = v1, v0
return v0[len(s1)]
总结
def default_insertion_cost(char):
return 1.0
def default_deletion_cost(char):
return 1.0
def default_substitution_cost(char_a, char_b):
# print(char_a, char_b,similar(char_a, char_b))
return 1-similar(char_a, char_b)
对这里为什么会返回 1-similar(char_a, char_b)做出解释。
例如>大 与 太 这两个字符在经过形似字相似度算法计算后的概率是高度相似的,也就意味着从大转变为太付出的代价是很小的,所以我们需要将其相似度转换为加权编辑距离中的代价,因此需要做1减操作。在最后的输出我们需要将其编辑距离转为相似度,所以需要引入如下公式计算
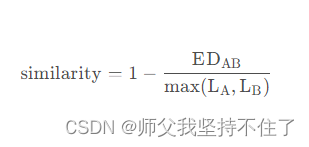
实验效果展示如下
str1 = 大和圩乡
str2 = 太和圩乡
weighted_levenshtein = WeightedLevenshtein()
result = weighted_levenshtein.distance(str1, str2)
print(str1, str2, result, 1 - result / max((len(str1), len(str))))
文本1:大和圩乡 文本2:太和圩乡 编辑距离:0.14230769230769225 相似度:0.9644230769230769
炼丹路漫漫 山高路远,看世界也找自己–Luofan




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











