







注意
本文是线上实战,已经应用到公司线上,并不是自己测试。量级:每天500W消息。
需求
每天500W 聊天消息,将聊天消息先分词,然后汇总提取出热词(出现次数最多的词)然后进行排序展示。
线上效果图:

展示对应热词名称和历史触发次数。
原始消息数据量展示图:

由于数据量巨大,每天有近500w数据,所以存储到ES ,然后按照每天建立索引。
实现思路(温馨提示: 请耐心阅读)
第一种方案:
每天零点,起一个定时器,分页查询当天ES数据,直到查完今天数据为止。然后分页去处理消息,进行分词汇总。
缺点: 一天的消息巨大,会导致分词,汇总延迟特别高,而且有可能内存溢出。抛弃这个方案。
第二种方案(拆分):
每隔一个小时,起一个定时器,分页查询前一个小时的聊天ES数据(平均大概20W),然后分页去处理消息,进行分词汇总。将得到的热词,热词出现的次数 存储到数据仓库(ADB)或者Mysql。
优点: 延迟只有一个小时。而且拆分后,只需要处理20W数据,绝对不会内存溢出,而且汇总很快。
热词数据存储方案
存储介质采用ADB,也可以用mysql。下面是表结构:
CREATE TABLE `t_word_data` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`word` int NOT NULL DEFAULT '0' COMMENT '热词',
`count` int DEFAULT '0' COMMENT '热词出现的历史次数',
PRIMARY KEY (`api_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='热词汇总表';目前公司线上热词数据量:
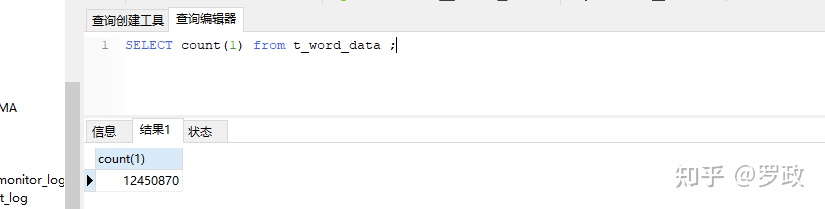
也就1千多万。mysql存储也没关系。ADB是 云原生数据仓库AnalyticDB,支持每天上亿数据存储(不用分表)。官网:
https://www.aliyun.com/product/ApsaraDB/adswww.aliyun.com
云原生数据仓库AnalyticDB_阿里云www.aliyun.com
分页读取 ES 方案
由于ES查询超过1w数据就会报错,所以要先修改支持能查50W(预估1个小时消息不超过50W):
max_result_window = 500000然后使用ES的范围查询(当前时间前一个小时的数据):
QueryBuilders.rangeQuery("createTime").to(一个小时前时间戳, false);这个是伪代码。就是简单的ES 范围查询而已。
分词方案
当查询前1个小时ES的聊天数据后,提取聊天内容,然后就要进行分词,这里我采用 HanLP ,为什么要选他? 先瞧下实验结果。
我这里有个原始聊天文件:

每行一个聊天消息,共有234W行,总大小234M :
这是我分词的耗时:
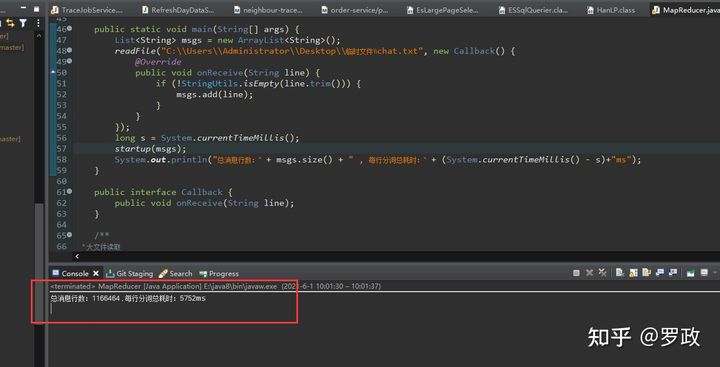
去掉了空行,有效行数:1166464 ,开了25个线程去执行分词,总耗时: 5752ms , 说实话,我真佩服这个分词效率!!!!!!
代码:
public class MapReducer {
private static final List<String> natureList =
Arrays.asList("nl", "n", "nr", "nrj", "nrf", "nr1", "nr2", "ns", "nsf", "nt", "ntc", "ntcf", "ntcb", "ntch",
"nto", "ntu", "nts", "nth", "nh", "nhm", "nhd", "nn", "nnt", "nnd", "ng", "nf", "ni", "nit", "nic", "nis",
"nm", "nmc", "nb", "nba", "nbc", "nbp", "nz", "g", "gm", "gp", "gc", "gb", "gbc", "gg", "gi", "s", "an");
public static void startup(List<String> msgs) {
// 多线程 提取 25个线程
AsyncTask.newMultiTasker().map(msgs, 25, curs -> {
for (String msg : curs) {
// 将单个消息进行分词
List<Term> terms = HanLP.segment(msg);
for (Term term : terms) {
if (!natureList.contains(term.nature.toString())) {
// 过滤 一些无用的词,比如感叹词,标点符号等
continue;
}
// 分好的词
String word = term.word.toString();
// 这里千万不要打印。打印出来的话非常慢,必须是放在mq里面,消费落库
// System.out.println(word);
}
}
});
}
public static void main(String[] args) {
List<String> msgs = new ArrayList<String>();
// !!!!!!!! 读者自己把聊天文件替换成自己的
readFile("C:\\Users\\Administrator\\Desktop\\临时文件\\chat.txt", new Callback() {
@Override
public void onReceive(String line) {
if (!StringUtils.isEmpty(line.trim())) {
msgs.add(line);
}
}
});
long s = System.currentTimeMillis();
startup(msgs);
System.out.println("总消息行数:" + msgs.size() + " , 每行分词总耗时:" + (System.currentTimeMillis() - s)+"ms");
}
public interface Callback {
public void onReceive(String line);
}
/**
* 大文件读取
*
* @param filePath
*/
public static void readFile(String filePath, Callback callback) {
File file = new File(filePath);
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file), 20 * 1024 * 1024); // 如果是读大文件,设置缓存
String tempString = null;
while ((tempString = reader.readLine()) != null) {
callback.onReceive(tempString);
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}上面 AsyncTask.newMultiTasker().map 为多线程工具,后面会给到。当使用HanLP.segment 拿到分好的词后,千万不要执行打印(打印特别耗时),线上的话应该放到MQ里面,慢慢消费落到 t_word_data 表里面(当然还有统计相同词的个数没做)。
HanLP maven:
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.6</version>
</dependency>AsyncTask.newMultiTasker() 工具代码 比较长,提供下载链接:
多线程执行工具.zipwww.jianguoyun.com
如链接失效,被和谐 等打不开,请联系我QQ: 657455400 。
接下来就是将分好的词,进行相同的词汇总出现的个数。也就是MapReduce过程。
MapReduce实现
这个比较重要,先看下结果:
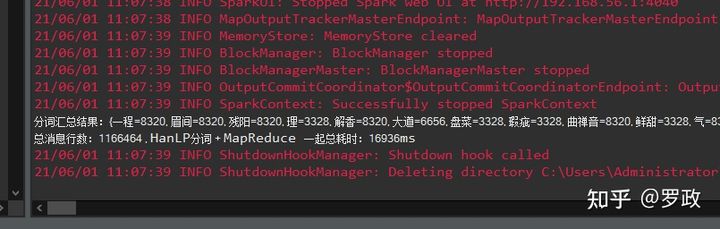
数据量就是上面分词的 1166464 数据,分词+汇总 总耗时:16秒 , 这个效率还是很惊人的,毕竟我机器性能也不好。
上面分词结果:
- 一程 出现了 8320 次
- 眉间 出现了 8320 次
- 理 出现了 3328 次
- ......
代码
public class MapReducer {
private static final List<String> natureList =
Arrays.asList("nl", "n", "nr", "nrj", "nrf", "nr1", "nr2", "ns", "nsf", "nt", "ntc", "ntcf", "ntcb", "ntch",
"nto", "ntu", "nts", "nth", "nh", "nhm", "nhd", "nn", "nnt", "nnd", "ng", "nf", "ni", "nit", "nic", "nis",
"nm", "nmc", "nb", "nba", "nbc", "nbp", "nz", "g", "gm", "gp", "gc", "gb", "gbc", "gg", "gi", "s", "an");
public static void startup(List<String> msgs) {
MapReduceEngine.open();
// 热词结果存储 <热词, 热词出现次数>
Map<String, Integer> results = new ConcurrentHashMap<String, Integer>();
try {
// 25 个线程 进行, 分词+MapReduce
AsyncTask.newMultiTasker().map(msgs, 25, curMsgs -> {
List<String> usefullyWorlds= new ArrayList<>();
for (String msg : curMsgs) {
// 将单个消息进行分词
List<Term> terms = HanLP.segment(msg);
for (Term term : terms) {
if (!natureList.contains(term.nature.toString())) {
// 过滤 一些无用的词,比如感叹词,标点符号等
continue;
}
// 分好的有用的词
usefullyWorlds.add(term.word.toString());
}
}
// MapReduce过程。 将reduce结果放入到results map集合中 <热词,热词出现次数>
MapReduceEngine.mapReduce(results, usefullyWorlds);
});
} finally {
MapReduceEngine.close();
}
System.out.println("分词汇总结果:" + results);
// 将 results 结果 发送mq 去 落库(数据库存在词,就要累加更新次数) , 逻辑我就不写了
}
public static void main(String[] args) {
List<String> msgs = DataProvider.find();
long s = System.currentTimeMillis();
startup(msgs);
System.out.println(
"总消息行数:" + msgs.size() + " , HanLP分词 + MapReduce 一起总耗时:" + (System.currentTimeMillis() - s) + "ms");
}
}DataProvider
读取聊天消息,只是封装成了工具:
public class DataProvider {
public interface Callback {
public void onReceive(String line);
}
/**
* 大文件读取
*
* @param filePath
*/
public static void readFile(String filePath, Callback callback) {
File file = new File(filePath);
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file), 20 * 1024 * 1024); // 如果是读大文件,设置缓存
String tempString = null;
while ((tempString = reader.readLine()) != null) {
callback.onReceive(tempString);
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
// 读取文件,然后返回内容
public static List<String> find() {
List<String> msgs = new ArrayList<String>();
readFile("C:\\Users\\Administrator\\Desktop\\临时文件\\chat.txt", new Callback() {
@Override
public void onReceive(String line) {
if (!StringUtils.isEmpty(line.trim())) {
msgs.add(line);
}
}
});
return msgs;
}
}
重点在于 MapReduceEngine工具。
由于代码是我花很多时间写和调式,也应用到现在公司线上,属于知识产权吧。 实在不易,需要花 5 Yuan RMb,在这也感谢您的支持! 现在有点质量的东西都是要花钱的,您也请谅解~
要是赞赏有问题,或者线上的使用问题,可以联系我。
在这篇文章,最下面直接点赞赏。赞赏完后,请联系我(知乎留言也行):
qq: 657455400
wx: hadluo














 1127
1127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









