






目录
1.总结pg和mysql的优劣势
| 特点 | PostgreSQL | MySQL |
|---|---|---|
| ACID 兼容性 | 非常好。对事务的支持非常强大,能够确保数据的完整性、一致性和持久性 | 良好。MySQL 也支持事务,但 PostgreSQL 的实现更为严格 |
| 数据类型支持 | 支持丰富的数据类型,包括标准 SQL 类型以及额外的数据类型,如数组、JSON、XML、地理空间等 | 数据类型支持相对较少,主要包括标准 SQL 类型,但 MySQL 也支持 JSON 类型等 |
| 扩展性 | 提供了丰富的扩展机制,用户可以通过编写插件或使用第三方扩展来扩展功能 | 也具有一定的扩展性,支持存储过程、触发器、用户自定义函数等,但不及 PostgreSQL |
| 高级功能 | 提供了许多高级功能,如复杂查询优化、窗口函数、表分区、全文搜索等,使其在处理复杂查询和大规模数据时表现优异 | 功能较为简单,提供了基本的功能,但缺乏一些高级功能,如窗口函数和全文搜索等 |
| 社区支持 | 拥有一个活跃的开发社区,提供大量的文档、教程和支持资源,使其易于学习和使用 | 有庞大的用户群体和社区支持,提供了大量的教程、文档和第三方工具,易于学习和使用 |
| 性能 | 在某些情况下性能稍逊于 MySQL,特别是在简单查询和写入操作方面,但在复杂查询和事务处理方面性能较好 | 性能良好,特别是在简单查询和写入操作方面表现优秀,适用于高并发读取型的应用场景 |
| 适用场景 | 适用于需要强事务支持和复杂查询的应用,如金融领域、数据分析等 | 适用于简单查询和读取操作频繁的应用,如网站、博客、小型企业应用等 |
| 使用门槛 | 学习曲线较陡,配置和使用相对复杂,需要一定的数据库知识和经验 | 学习曲线较平缓,配置和使用较简单,适合初学者和小型项目 |
2.PostgreSQL安装
2.1二进制安装
优势:
简单快速: 二进制安装是最简单的安装方法之一,不需要用户进行编译和配置,只需下载预编译的二进制文件并执行安装脚本即可完成安装过程
劣势:
定制性差: 由于二进制安装是预编译的通用版本,因此不够灵活,不能满足特定需求,如定制化的编译选项或特定的扩展
安装步骤:
[15:54:59root@localhost ~]# rpm -Uvh https://mirrors.aliyun.com/postgresql/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Retrieving https://mirrors.aliyun.com/postgresql/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
warning: /var/tmp/rpm-tmp.KOOlFg: Header V4 RSA/SHA256 Signature, key ID 08b40d20: NOKEY
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:pgdg-redhat-repo-42.0-38PGDG ################################# [100%]
[15:55:16root@localhost ~]# sed -i "s@https://download.postgresql.org/pub@https://mirrors.aliyun.com/postgresql@g" /etc/yum.repos.d/pgdg-redhat-all.repo
[15:56:49root@localhost ~]# yum install -y postgresql
Installed:
libpq5-16.2-42PGDG.rhel8.x86_64 postgresql-10.23-4.module+el8.9.0+1734+74bd286c.x86_64
Complete!
[15:58:36root@localhost ~]#
#通过阿里云配置的pg源安装
2.2源码编译安装
优势:
灵活定制: 用户可以根据自己的需求和环境进行定制编译,选择需要的功能和扩展,并进行参数配置,以达到最优性能。
兼容性强: 编译安装可以确保 PostgreSQL 和其他软件的兼容性,并且可以充分利用系统的硬件资源
劣势:
复杂繁琐: 编译安装需要用户具有一定的编译和配置经验,需要手动下载源代码、解压缩、配置编译选项、编译和安装,整个过程相对繁琐。
耗时耗力: 编译安装需要大量的时间和计算资源,尤其是在配置编译选项和等待编译过程中
安装步骤:
- 下载 PostgreSQL 源代码
- 解压缩源代码
- 配置编译选项
- 执行编译命令进行编译
- 执行安装命令进行安装
- 设置环境变量
- 验证安装结果
3.总结pg服务管理相关命令
3.1pg_ctl 命令
pg_ctl 是 PostgreSQL 的控制命令,用于启动、停止、重启、检查和管理 PostgreSQL 服务
常用选项:
-D:指定 PostgreSQL 数据目录。
-l:指定日志文件路径。
-o:传递额外的命令行参数给 PostgreSQL 进程
示例:
[16:06:01root@localhost ~]# pg_ctl start -D /data/pg
#启动数据库
[16:07:43root@localhost ~]# pg_ctl stop -D /data/pg
#停止数据库
[16:07:43root@localhost ~]# pg_ctl restart -D /data/pg
#重启数据库
[16:07:43root@localhost ~]# pg_ctl status -D /data/pg
#检查数据库服务状态
3.2psql 命令
psql 是 PostgreSQL 的交互式命令行工具,用于连接、管理和操作 PostgreSQL 数据库
常用选择:
-U:指定连接的用户名
-d:指定连接的数据库名
-h:指定连接的主机地址
示例:
#连接到本地 PostgreSQL 数据库
[16:39:41root@localhost ~]# psql -U username -d database_name
#连接到远程 PostgreSQL 数据库
[16:40:01root@localhost ~]# psql -U username -h host_address -d database_name
#执行 SQL 查询
[16:40:20root@localhost ~]# psql -U username -d database_name -c "SELECT * FROM table_name;"
4.总结pg数据库结构组织
PostgreSQL(pg)数据库的结构组织主要由数据库、模式(Schema)、表(Table)、视图(View)、索引(Index)、函数(Function)等组成
数据库(Database)
- 数据库是 PostgreSQL 中数据的最顶层组织单位
- 每个数据库包含多个模式(Schema),以及表、视图、索引等对象
模式(Schema):
- 模式是 PostgreSQL 中用于组织和管理对象的命名空间。
- 每个数据库可以包含多个模式,每个模式可以包含多个表、视图、函数等对象
- 默认情况下,PostgreSQL 中会有一个名为 public 的模式,如果没有显式指定模式,对象会被创建在 public 模式下
表(Table):
- 表是存储数据的基本单位,由行和列组成
- 每个表属于一个模式,可以包含多个列和零至多个索引
- 表可以通过 SQL 的增删改查操作来管理和操作数据
视图(View):
- 视图是虚拟的表,由查询定义,不存储数据
- 视图可以简化复杂查询,隐藏底层表的结构,提高查询的可读性和灵活性
索引(Index):
- 索引是提高查询效率的关键,用于加速数据检索
- 索引可以在表的列上创建,使查询可以更快地定位和检索数据
函数(Function):
- 函数是一组 SQL 语句的集合,用于执行特定的任务
- 函数可以接受参数,执行特定的操作,并返回结果
除了以上常见的数据库结构组织外,PostgreSQL 还支持触发器(Trigger)、存储过程(Procedure)、事件(Event)等高级功能,用于实现更复杂的数据处理和逻辑控制。总的来说,PostgreSQL 提供了丰富的数据库结构组织和管理功能,能够满足各种复杂的数据组织和处理需求
5.实现pg远程连接。输入密码和无密码登陆
[16:53:57root@ubuntu ~]# vim /etc/postgresql/16/main/postgresql.conf
#listen_addresses = 'localhost' # what IP address(es) to listen on; #更改为下面表示任何主机都可以登录
listen_addresses = '0.0.0.0'
[16:55:26root@ubuntu ~]# vim /etc/postgresql/16/main/pg_hba.conf
host all all 0.0.0.0/0 md5
#这将允许来自任意 IP 地址的主机使用密码登录
#重启服务生效
#必须设置密码
postgres=# alter USER postgres with password '123456';
psql -h 10.0.0.8 -p 5432 -U username -d database_name
6. 总结库,模式,表的添加和删除操作。表数据的CURD。同时总结相关信息查看语句
库、模式、表的添加和删除操作:
库的添加和删除:
postgres=# CREATE DATABASE dbname; #创建库
CREATE DATABASE
postgres=# DROP DATABASE dbname; #删除库
DROP DATABASE
postgres=# CREATE SCHEMA schemaname; #创建模式
CREATE SCHEMA
postgres=# DROP SCHEMA schemaname; #删除模式
DROP SCHEMA ^
postgres=# create table tb1 (id serial primary key,name text); #创建表
CREATE TABLE
postgres=# DROP table tb1; #删除表
DROP TABLE
表数据的CURD操作:
postgres=# INSERT INTO tb1 (id, name) VALUES (1,'luo'); #添加数据
INSERT 0 1
postgres=# SELECT * FROM tb1; #查询数据
id | name
----+------
1 | luo
(1 row)
postgres=# DELETE FROM tb1 WHERE id=1; #删除数据
DELETE 1
postgres=# SELECT * FROM tb1;
id | name
----+------
(0 rows)
相关信息查看语句:
查看数据库列表:
\l
查看模式列表:
\dn
查看表列表:
\dt
查看表结构:
\d tablename
查看表数据:
SELECT * FROM tablename;
7.角色管理
PostgreSQL 的用户和角色管理是数据库安全的重要组成部分
用户和角色的概念:
用户(User):
用户是连接到 PostgreSQL 数据库的实体,具有登录权限和数据库操作权限。
每个用户都有一个唯一的用户名和密码
角色(Role):
角色是一组用户或其他角色的集合,用于管理和控制权限
角色可以是登录角色(具有登录权限)或非登录角色(不具有登录权限)
PostgreSQL 中的用户实际上是特殊类型的角色,称为登录角色
用户和角色管理操作:
创建用户和角色:
创建登录用户:CREATE USER username WITH PASSWORD 'password';
创建非登录角色:CREATE ROLE rolename;
修改用户和角色:
修改用户密码:ALTER USER username WITH PASSWORD 'new_password';
修改角色权限:ALTER ROLE rolename [WITH] LOGIN | NOLOGIN;
删除用户和角色:
删除用户:DROP USER username;
删除角色:DROP ROLE rolename;
授权和撤销权限:
授权给用户或角色:GRANT permission ON object TO user_or_role;
撤销用户或角色的权限:REVOKE permission ON object FROM user_or_role;
角色组:
使用 CREATE GROUP 命令创建角色组,将一组角色集合到一个组中,可以更方便地管理权限。
查看用户和角色信息:
查看所有用户:\du
查看所有角色:\dg
查看用户权限:\du username
查看角色权限:\dg rolename
8.添加mage用户,magedu模式,准备zabbix库,配置mage用户的默认模式magedu,要求mage用户给zabbix库有所有权限
postgres=# CREATE USER mage WITH PASSWORD '123456'; #创建用户
CREATE ROLE
postgres=# CREATE SCHEMA magedu;#创建模式
CREATE SCHEMA
postgres=# CREATE DATABASE zabbix; #创建数据库
CREATE DATABASE
postgres=# GRANT ALL PRIVILEGES ON DATABASE zabbix TO mage; #授权
GRANT
postgres=# ALTER ROLE mage SET search_path TO magedu; #配置用户默认模式
ALTER ROLE
9.总结pgsql的进程结构,说明进程间如何协同工作的
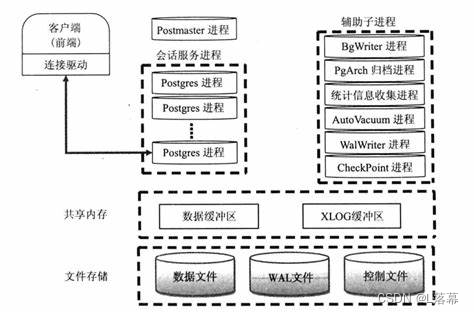
在 PostgreSQL 中,有多个类型的进程共同协同工作以提供数据库服务。以下是 PostgreSQL 进程结构的总结:
Postmaster 进程:
- Postmaster 是 PostgreSQL 的主进程,负责启动、停止和监控其他后台进程
- 当 PostgreSQL 服务启动时,会首先启动 Postmaster 进程
后台工作者进程:
- PostgreSQL 有多个类型的后台工作者进程,每种类型的工作者进程负责不同的任务,例如处理客户端连接、执行后台任务等
- 后台工作者进程在启动时由 Postmaster 进程创建并监kong
客户端进程:
- 客户端进程是连接到 PostgreSQL 数据库的应用程序进程
- 当客户端应用程序连接到 PostgreSQL 时,会创建一个客户端进程,该进程与服务器进行通信以执行数据库操作
其他辅助进程:
- 除了主要的后台工作者进程和客户端进程外,PostgreSQL 还可能启动其他辅助进程,用于执行特定任务,如自动化备份、日志管理等
这些进程之间通过共享内存和消息队列等机制进行通信和协同工作。例如,客户端进程通过与后台工作者进程建立连接来执行数据库操作,后台工作者进程在接收到客户端请求后会执行相应的数据库操作,并将结果返回给客户端进程
10.总结pgsql的数据目录中结构,说明每个文件的作用
base 目录:
存储数据库中的所有表数据文件。每个数据库有一个对应的子目录
global 目录:
存储全局共享的系统数据文件,如系统表空间文件等
pg_clog 目录:
存储事务提交日志文件,用于实现数据库的事务功能
pg_commit_ts 目录:
存储提交时间戳文件,用于实现多版本并发控制(MVCC)
pg_dynshmem 目录:
存储动态共享内存文件,用于处理动态分配的共享内存
pg_logical 目录:
存储逻辑复制相关的文件,用于实现逻辑复制功能
pg_logical 目录:
存储逻辑复制相关的文件,用于实现逻辑复制功能
pg_multixact 目录:
存储多事务共享文件,用于实现并发控制
pg_notify 目录:
存储通知文件,用于实现异步通知功能
pg_replslot 目录:
存储复制插槽文件,用于实现流复制功能
pg_serial 目录:
存储序列化事务日志文件,用于实现流复制功能
pg_snapshots 目录:
存储快照文件,用于实现快照隔离级别功能
pg_stat 目录:
存储统计信息文件,包括表、索引等对象的统计信息
pg_stat_tmp 目录:
存储临时统计信息文件
pg_subtrans 目录:
存储子事务文件,用于实现并发控制
pg_tblspc 目录:
存储表空间链接文件
pg_twophase 目录:
存储两阶段提交事务文件
pg_wal 目录:
存储WAL日志文件,用于实现数据库的持久性和恢复功能
PG_VERSION 文件:
记录 PostgreSQL 数据库的版本号
postgresql.conf 文件:
存储 PostgreSQL 数据库的配置信息,如监听地址、端口号、日志等级等
pg_hba.conf 文件:
存储 PostgreSQL 数据库的身份验证配置信息,用于控制用户访问权限
pg_ident.conf 文件:
存储 PostgreSQL 数据库的身份映射配置信息,用于将操作系统用户映射到数据库用户














 4753
4753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









