







项目场景:
项目场景:我们有俩个大数据集群 一个用usdp管理起来的主要用来做Spark计算用的,另外一个是以前的老集群,主要用来做数据存贮用的。
现在,我们需要将储存集群的hive数据 通过计算集群的spark bulk load任务 写到存储集群的hbase 里面去。
问题描述
问题:我们两个集群的组件版本不一致,因为usdp是高度封装的它最高支持的版本,也达不到我们存储集群的组件版本,这样两个集群的组件版本做不到一致,就很扯淡,但是我们还是测试了。
下面贴一下两个集群的组件的版本:
usdp--计算节点:
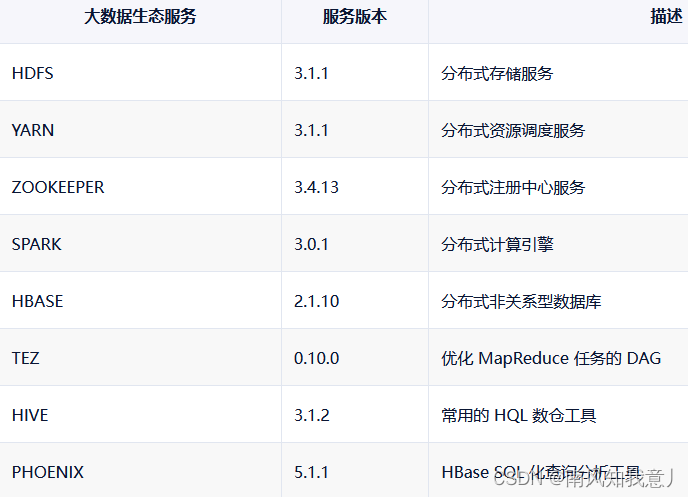
存储节点
zookeeper-3.6.3
hadoop-3.2.2
hbase-2.3.5
spark-3.0.3
hive-3.1.2
phoenix-5.1.2
redis-6.2.6
mysql-8.0.28
dolphinscheduler-2.0.2
主要bug:
2022-06-02 10:33:37 ERROR yarn.ApplicationMaster: User class threw exception: java.lang.NoSuchMethodError: org.apache.hadoop.hdfs.client.HdfsDataInputStream.getReadStatistics()Lorg/apache/hadoop/hdfs/DFSInputStream$ReadStatistics;
java.lang.NoSuchMethodError: org.apache.hadoop.hdfs.client.HdfsDataInputStream.getReadStatistics()Lorg/apache/hadoop/hdfs/DFSInputStream$ReadStatistics;
at org.apache.hadoop.hbase.io.FSDataInputStreamWrapper.updateInputStreamStatistics(FSDataInputStreamWrapper.java:253)
at org.apache.hadoop.hbase.io.FSDataInputStreamWrapper.close(FSDataInputStreamWrapper.java:300)
at org.apache.hadoop.hbase.io.hfile.HFile.isHFileFormat(HFile.java:590)
at org.apache.hadoop.hbase.io.hfile.HFile.isHFileFormat(HFile.java:571)
at org.apache.hadoop.hbase.tool.LoadIncrementalHFiles.visitBulkHFiles(LoadIncrementalHFiles.java:1072)
at org.apache.hadoop.hbase.tool.LoadIncrementalHFiles.discoverLoadQueue(LoadIncrementalHFiles.java:988)
at org.apache.hadoop.hbase.tool.LoadIncrementalHFiles.prepareHFileQueue(LoadIncrementalHFiles.java:249)
at org.apache.hadoop.hbase.tool.LoadIncrementalHFiles.doBulkLoad(LoadIncrementalHFiles.java:356)
at org.apache.hadoop.hbase.tool.LoadIncrementalHFiles.doBulkLoad(LoadIncrementalHFiles.java:281)
at MidToHbase_daily$.main(MidToHbase_daily.scala:226)
at MidToHbase_daily.main(MidToHbase_daily.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:728)
原因分析:
主要bug:java.lang.NoSuchMethodError: org.apache.hadoop.hdfs.client.HdfsDataInputStream.getReadStatistics
起初我先在本地idea编码调试
1,其实出现 java.lang.NoSuchMethodError 我先想到的就是版本冲突的问题,然后我仔细比对了pom和存储集群的组件版本,发现是一致的。
2,你不是缺个方法吗,那我就在pom中加上下面的依赖包,再debug一次
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>3.2.2</version>
</dependency>
3,此时,成功运行,存储集群的指定文件夹下hfile也生成了,hbase测试表内也有数据了,大功告成?打包、上海豚调度器、运行、tmd报错
现在我在usdp小海豚上调试
1,why?为什么本地idea稳定的一批,一打包上集群就给老子出bug,还是那个熟悉的bug,我依赖也引了,它为什么还是找不到
hadoop-hdfs-client-3.2.2.jar中的方法???
2,开始分析,可能是jar包没打进去的原因?那就试试spark指定class path
然后在spark-submit提交jar时,加入配置:
--conf spark.driver.extraClassPath="/srv/udp/2.0.0.0/spark/test/hadoop-hdfs-client-3.2.2.jar"
--conf spark.executor.extraClassPath="/srv/udp/2.0.0.0/spark/test/hadoop-hdfs-client-3.2.2.jar"
设置spark.driver.extraClassPath和spark.executor.extraClassPath适合于引入大量依赖jar包的情况。
对于只需要引入几个jar的情况,还可以使用-jars选项或者SparkContext.addJar(…)方法。
两者的区别在于,前者要求集群中所有节点必须都在设置的extreClassPath路径中含有所需的jar包。后者只要求在提交的节点上含有jar,集群中其他节点可以使用http get方式,通过网络请求的方式获取所需的jar包(只是一种情况,还有其他情况)。
3,好的,开干,运行、报错,依然是熟悉的 java.lang.NoSuchMethodError: org.apache.hadoop.hdfs.client.HdfsDataInputStream.getReadStatistics
tmd,为啥?还是找不到呢?好的,我去找源码
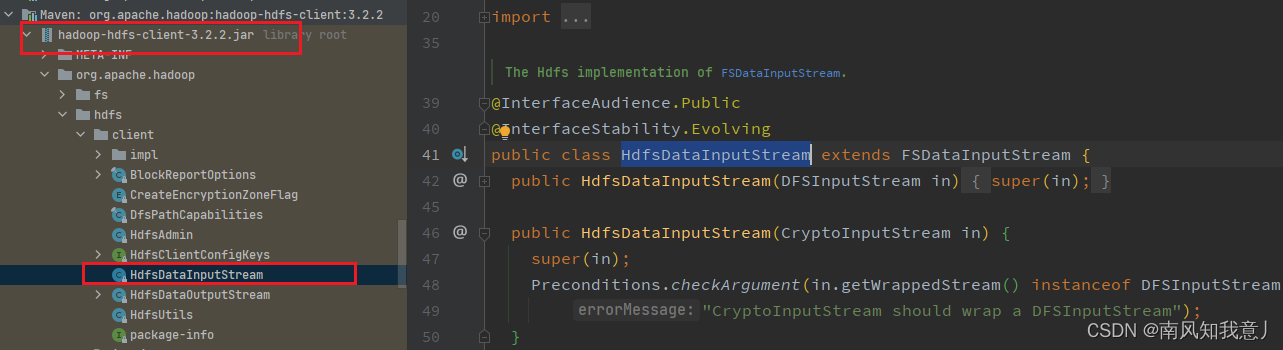
这不好好的在hadoop-hdfs-client-3.2.2.jar里面吗?为什么找不到呐?奇了怪了,
4,一通分析,对于spark依赖的jar,使用spark-submit命令提交任务时会自动将spark目录下jars目录中的所有jar包加入classpath
我在usdp集群里面执行的,因为usdp集群的hadoop版本是3.1.1的,所以当在集群上执行的时候3.2.2的包就没用的,他还是会用3.1.1的包,为此我们使用 arthas 做了验证
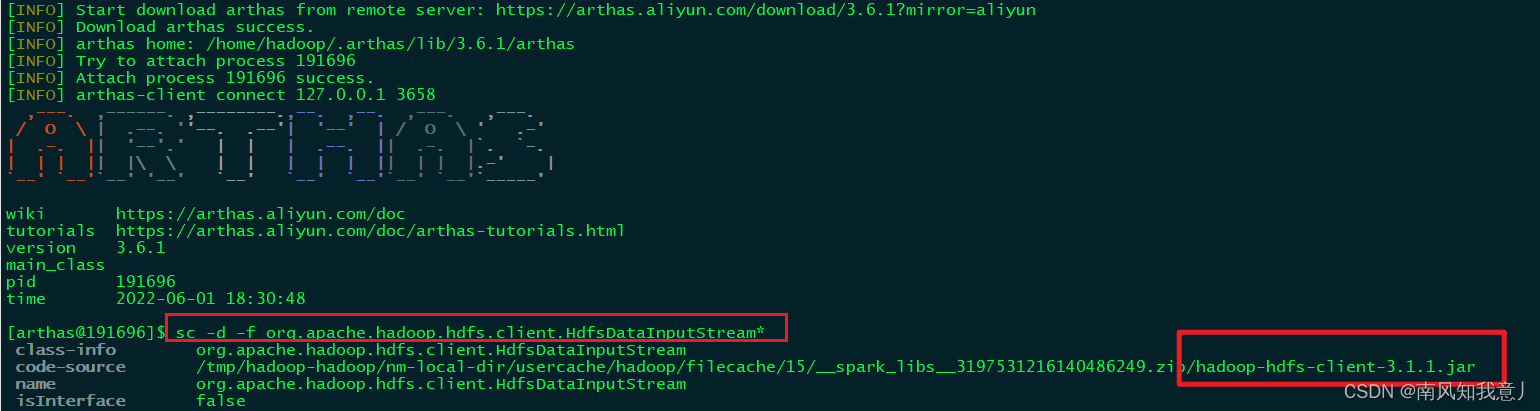
的确是的,无论你hadoop版本怎么改动都没用,它还是会优先找 spark/jars下的包。
5,那不对啊,即使你去找hadoop-hdfs-client-3.1.1那还是有HdfsDataInputStream这个类的啊,那也不至于找不到啊,为什么一致报错呐?
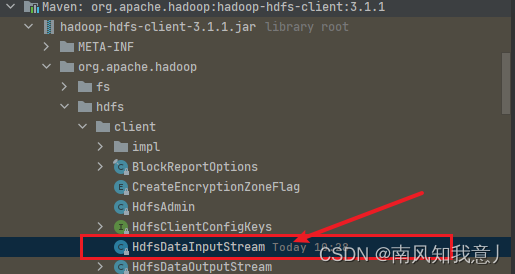
解决方案:
还记不记得:一看到
java.lang.NoSuchMethodError就想到了jar冲突,突然有个想法出现在我的脑海里面,会不会是hbase版本和hadoop版本冲突导致找不到类,明明有却找不到那就很不正常啊。
1,当时我们pom文件的hbase版本是hbase-2.3.5的,因为要写到存储集群的hbase,那么pom中的版本和存储集群的组件版本保持一致,很合理啊 ?
2,我们usdp集群的hadoop是3.1.1的hbase是2.1.10的,这是usdp官方给的的搭配方案,那一定是经过验证的,既然hadoop版本我们动不了,那就换一下hbase版本吧
3,可能是hbase-2.3.5和hadoop-3.1.1版本冲突导致找不到类吧,然后我把pom文件改了一下,按照usdp集群的组件版本改的,

再次打包 上海豚运行 wok,成了
nice!这次bug困扰了我们两个人两天时间,期间各种测试,各种倒腾版本,就在快要放弃的时候,灵光乍现,想到hbase版本问题,突然就成了,太魔幻。。。














 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









