







优化背景
由于Driver的单线程运行以及Spark的任务调度决定了Job是串行执行的,但是当各个job之间的业务逻辑是相互独立的时候,我们就可以考虑多线程并行处理!
因为是测试: 以下代码 是单表(TMP)跑四次,实际情况下是多张表
串行处理
def main(args: Array[String]): Unit = {
val watch = new StopWatch
watch.start()
val session: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[10]")
.getOrCreate()
val df: DataFrame = session.read
.json("file:///C:\\Users\\HR\\Desktop\\测试数据\\courseshoppingcart.log")
val df2: Dataset[Row] = df.coalesce(8)
df2.createOrReplaceTempView("TMP")
val list = List(
"select * from TMP where courseid=103",
"select * from TMP where courseid=101",
"select * from TMP where courseid=9514",
"select * from TMP where courseid=4894"
)
var sum=0L
list.foreach(sql=>{
sum+=session.sql(sql).count()
})
println(sum)
watch.stop()
println(watch.getTime)
session.close()
}

如上图所示:提交的四个任务是串行执行的
线程池并行处理
本地测试,本机10个cpu,4个job,每个job2个并行度也就是2个cpu。此时耗用8个cpu,所以不存在线程切换。
def main(args: Array[String]): Unit = {
val watch = new StopWatch
watch.start()
val session: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[10]")
.getOrCreate()
val df: DataFrame = session.read
.json("file:///C:\\Users\\HR\\Desktop\\测试数据\\courseshoppingcart.log")
val df2: Dataset[Row] = df.coalesce(2) // 2个分区
df2.createOrReplaceTempView("TMP")
var executor: ExecutorService = null
try {
val list = List(
"select * from TMP where courseid=103",
"select * from TMP where courseid=101",
"select * from TMP where courseid=9514",
"select * from TMP where courseid=4894"
)
// 创建线程池
executor = Executors.newWorkStealingPool(4)
// 创建future以便于接收返回值
val futureList = new util.ArrayList[Future[Integer]](4)
list.foreach(sql => {
val callable: Callable[Integer] = new Callable[Integer]() {
override def call() = {
session.sql(sql).count().toInt
}
}
//接收返回值
futureList.add(executor.submit(callable))
})
var sum = 0
// 累加返回值
futureList.forEach(future => {
val res: Int = future.get().toInt //get是阻塞方法
sum += res
})
println(sum)
} finally {
executor.shutdown()
session.close()
}
watch.stop()
println(watch.getTime)
}
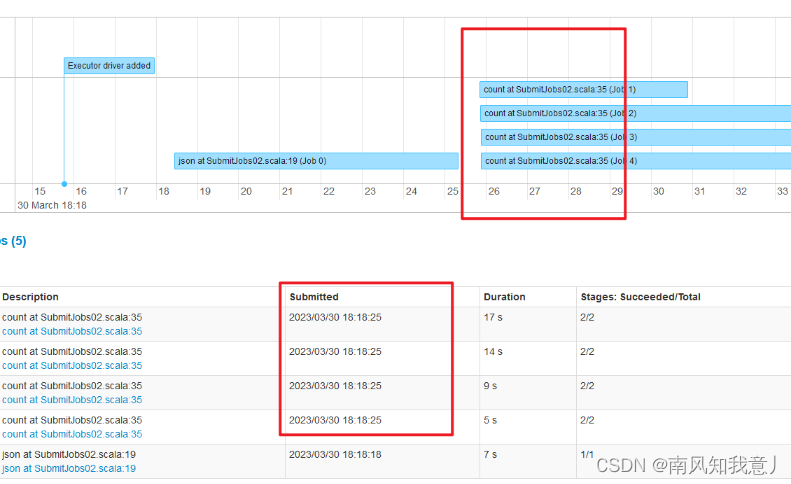
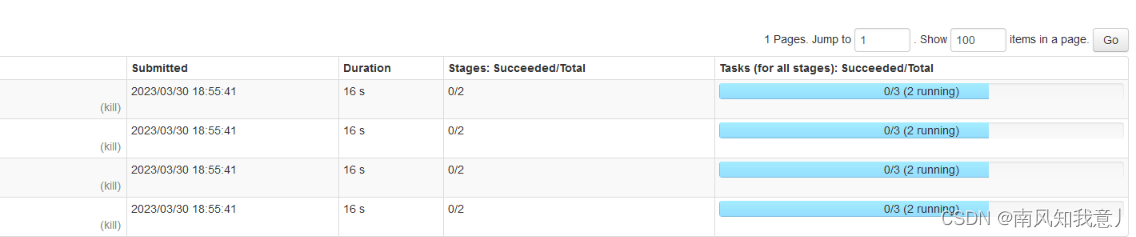
可以看到,job之间并行处理,在cpu资源充足的情况下,可以很大的提升任务效率!
小结
- 多线程提交任务时,当资源申请足够多时,会同时执行,即使资源不足,也会在上一个任务结束释放资源后立即执行
- 哪些动作是需要统一做的,哪些是需要并行执行的,在哪里做Cache来应对Lazy执行带来的问题
- 合理提升Executor的内存来保证并行执行过程中内存是够用的















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









