






 本文分享了Kubernetes在SHAREit的实际落地经验,包括节点调度、污点管理、日志收集、Prometheus优化、资源审计、自动化注入、流量与数据处理应用策略、操作系统和镜像优化、DNS管理、服务优化以及集群扩展和容灾能力增强等多个方面。
本文分享了Kubernetes在SHAREit的实际落地经验,包括节点调度、污点管理、日志收集、Prometheus优化、资源审计、自动化注入、流量与数据处理应用策略、操作系统和镜像优化、DNS管理、服务优化以及集群扩展和容灾能力增强等多个方面。



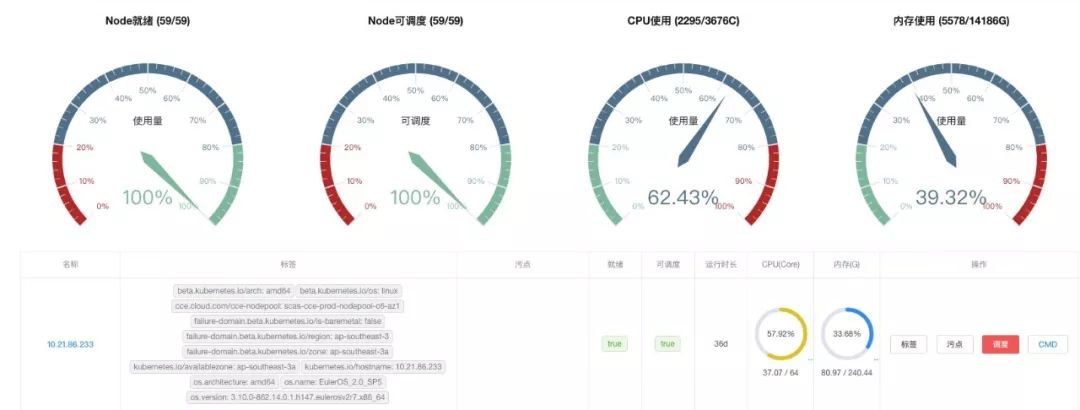
需要下线替换某些Node节点。此时需要调度控制功能,将该Node标记为不可调度,然后再驱赶该Node上的Pod,最后完成Node的替换。
污点管理。例如Promethues这种高耗CPU和Memory的系统组件,如果和关键业务应用混跑到一台Node节点上,在高峰期容易影响关键应用响应时间。此时就可以使用污点管理功能,配合Pod级别的容忍来实现。
Webshell。在某些特殊情况下,需要快速SSH到指定主机上进行debug。
标签管理。例如给不同的机型,根据特点打上不同的标签,例如:storage:ssd等,配合Pod的nodeSelector和亲和性,满足业务更复杂的调度要求。
将日志收集Agent打到业务容器镜像中。
将日志收集Agent作为sidercar的方式与业务容器运行在同一个Pod中。
宿主机Node层面统一收集:将宿主机的目录挂载为容器的日志目录,然后在宿主机上收集。
我们会将一块1T大小的块存储挂载到Node节点上,作为数据盘(/data)。保证系统盘和数据盘分离。该数据盘主要用来存放业务日志和镜像。
防止若干写日志比较多的Pod调度到同一个主机上,将数据盘写满,影响到其他的业务,以及防止日志收集系统有故障期间,日志丢失。我们编写了applog-cleaner组件,会定期清除旧日志数据。我们承诺保留最近两天的日志。
容器本身的特点就是太多的不确定性,并且在弹性扩缩容的时候,你无法确定你的Pod调度到哪一个具体的计算节点,导致我们无法事先配置好日志收集路径。而我们规定业务日志的收集目录是/data/logs/命名空间名/应用名/poduid/下,所以我们自研了hostpathperpod volume组件。该组件通过flex volume实现,在Pod视角,业务依旧将日志写到了/data/logs下,实际上该目录挂载到了主机的/data/logs/命名空间名/应用名/poduid/ 。而在Pod的yaml中,如下配置即可:
volumes:
- flexVolume:
driver: sgt.shareit.com/hostpathperpod
options:
hostPath: /data/logs
name: log-dir- add_kubernetes_metadata:
in_cluster: true
host: ${NODE_NAME}
# namespace: ${POD_NAMESPACE}
default_indexers.enabled: false
default_matchers.enabled: false
indexers:
- pod_uid:
matchers:
- logs_path:
logs_path: /data/logs/
resource_type: hostpath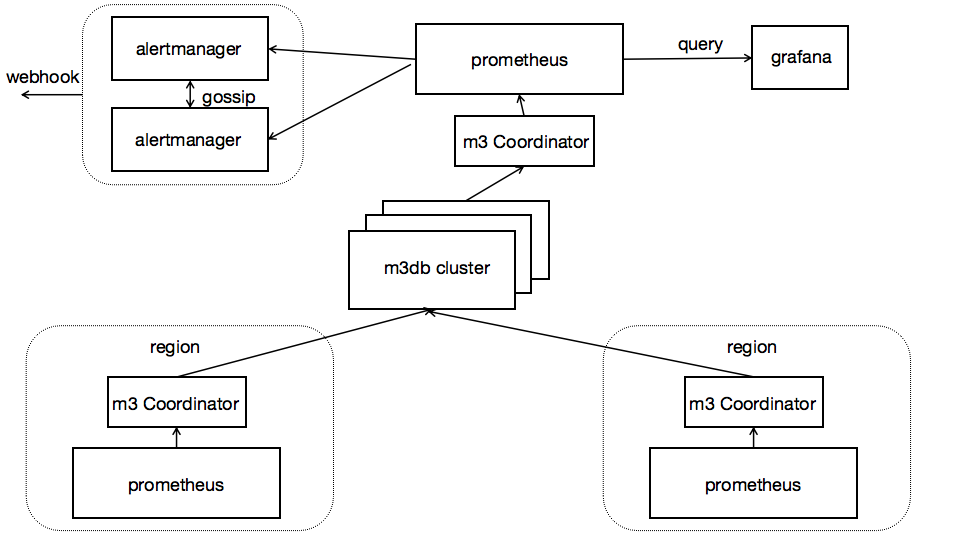
采集查询分离。我们严格规定不得从采集Prometheus查询数据。如果是单一的Prometheus,在实际使用中,大家在查询了一个较大时间维度后,Prometheus会OOM,这个时候,你在Grafana中看到,你的曲线是有中断的。同时查询端,可以多个Prometheus,前置一个LB,起到高可用的作用。
metrics,不仅仅是在监控领域发挥作用,而且对于资源的计费和审计也是极其重要的,将不同采集源的metrics汇聚到一个TSDB集群中,提供了一个全公司的维度。同时对于后续的AIOps也是非常重要的。
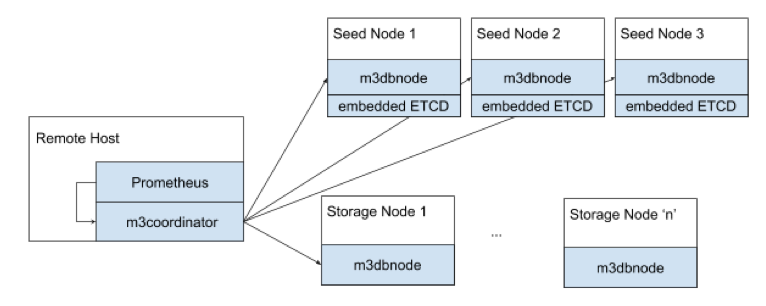
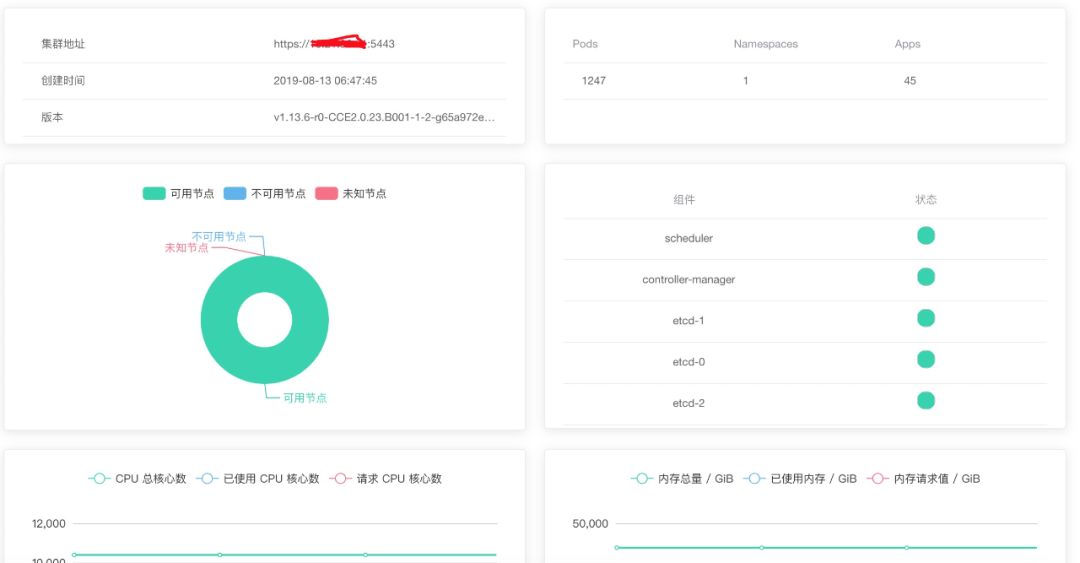
在生产环境,我们3个etcd节点单独部署,6个高配主机作为storage节点。
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: prometheus
name: prometheus
namespace: kube-admin
data:
prometheus.yml: |-
global:
scrape_interval: 30s
evaluation_interval: 30s
# The labels to add to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
cluster: 'SGT-eks-apse1-prod'
# Settings related to the remote write feature.
remote_write:
- url: "http://localhost:7201/api/v1/prom/remote/write"
queue_config:
max_samples_per_send: 60000
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: kube-state-metrics
static_configs:
- targets:
- kube-state-metrics.kube-system:8080
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-kubelet
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __metrics_path__
replacement: /metrics/cadvisor
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module:
- http_2xx
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
m3coordinator.yaml: |-
listenAddress:
type: "config"
value: "0.0.0.0:7201"
metrics:
scope:
prefix: "coordinator"
prometheus:
handlerPath: /metrics
listenAddress: 0.0.0.0:7203 # until https://github.com/m3db/m3/issues/682 is resolved
sanitization: prometheus
samplingRate: 1.0
extended: none
tagOptions:
idScheme: quoted
clusters:
# Fill-out the following and un-comment before using, and
# make sure indent by two spaces is applied.
- namespaces:
- namespace: default
retention: 48h
type: unaggregated
- namespace: metrics
type: aggregated
retention: 720h
resolution: 5m
client:
config:
service:
env: default_env
zone: embedded
service: m3db
cacheDir: /var/lib/m3kv
etcdClusters:
- zone: embedded
endpoints:
- 172.xx.61.23:2379
- 172.xx.70.225:2379
- 172.xx.77.220:2379
# ... etc, list only M3DB seed nodes
writeConsistencyLevel: majority
readConsistencyLevel: unstrict_majority
检查部署到生产环境中的应用,资源的limit和request是否相等,保证业务的稳定性。同时检查是否具有env,group,project等标签,方便后续的分析和审计。检查容器是否以特权容器模式运行。
根据Pod的annotations,注入volume或环境变量或注入特定功能的init container或注入sidecar辅助容器。例如AKSK,之前我们的业务代码运行在虚机上,引用了公有云的SDK后,SDK会自动优先到某路径下查找credentials文件,获取访问对应资源的操作凭证。在容器化的过程中,我们为了让业务代码不做任何更改,所以会自动注入AKSK到指定路径下。同时也保证了AKSK的安全,避免了泄露的风险。
关键流量处理应用:该类应用希望在流量到来时快速的扩容,在流量高峰过去后,希望慢慢的缩容,以避免流量反弹。
关键数据处理应用:该类应用希望当大量数据到达时希望快速扩容,在数据减少时,希望快速的缩容,以节省成本。
一些不重要的业务,我们希望缓慢的扩缩,避免抖动,尤其是频繁的扩缩,可能导致Node节点的频繁的扩缩。
操作系统优化:单机支持百万TCP并发,/etc/sysctl.conf,/etc/security/limits.conf。传统的虚拟机基本上运行一个业务,很多内核参数不需要过多更改,即可满足业务。但是在Kubernetes中,一个Node节点会混跑,此时必须优化一些内核参数,从而满足混跑业务。
基础镜像的优化和把控。一方面,容器镜像的内核参数并不是全部继承了Node主机,所以对于核心高并发业务,必须在镜像内核级再次调优。另外一方面,出于安全的考虑,所以我们专门定制了基础镜像,供业务研发使用。
CoreDNS。在实际大集群中,DNS实例数目需要根据集群规模或是Pod数目进行扩缩。但是传统的PHA存在诸多问题,并不适合用于CoreDNS的扩缩。我们选择了dns-horizontal-autoscaler,进行梯度扩缩。此外CoreDNS耗费资源非常小,尤其是在集群规模比较小的时候,及其容易被调度到同一台主机,假如恰好调度到一台上,当由于物理故障,Node节点需要下线的时候,会引起大面积DNS解析失败。所以需要加上Pod的硬反亲和。
修改Docker存储目录和kubelet存储目录到数据盘,做到数据盘和系统盘分离。
配置Node节点的系统预留资源和Kubernetes预留资源,防止雪崩。
对于一些高并发业务,使用Kubernetes svc spec external TrafficPolicy: Local方式,不对客户端IP做SNAT。Local模式性能最优最稳定。
业务优化,主要是容器感知容器分配资源。例如Java程序,我们选择了OpenJDK 8u212版本。对于Go程序,我们设置了CPUs环境变量,而代码中在init函数中根据环境变量值设置GOMAXPROCS。
加强应用容灾能力,增加备份和一键恢复功能。
将自研插件和集群管理采用cluster-operator的模式,方便集群管理。进一步提高集群管理者的工作效率。
扩展Kuberntes调度器,增加更丰富的调度方式,比如组调度。
Service Mesh试落地和产品化。
我们已经配合大数据团队做了Spark on Kubernetes的实践工作。接着我们将配合基础架构和推荐团队,做好AI on Kubernetes和Flink on Kubernetes等。

















 4948
4948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









