







在2019年8月推出etcd 3.4时,我们主要关注存储后端改进、非投票成员与预投票等功能。在接下来的近两年中,etcd被越来越广泛地应用于各类关键任务集群及数据库程序当中,其功能集也随之变得愈发广泛且复杂。因此,提高项目稳定性与可靠性成为近期规划工作的重中之重。
今天,我们正式发布etcd 3.5。过去两年以来,我们完成了多轮迭代、修复了大量bug、确定了新的优化方向并着力培养相关生态系统。在此期间,etcd项目也成为云原生计算基金会(CNCF)的毕业项目。而此次发布的3.5版本,正是etcd社区不断进化以及众多艰难探索的集大成结果。
在本文中,我们将共同了解etcd 3.5中最为显著的变化,并展示项目的未来发展路线图。关于详尽的变更清单,请参阅CHANGELOG 3.5[1]。若需了解更多更新内容,请在Twitter @etcdio上关注我们。最后,你可以点击此处[2]获取etcd。
安全性

考虑到不少用户在使用etcd处理敏感数据,改善并维护安全水平自然成为我们的首要任务。为了全面了解etcd的安全态势,我们完成了一轮第三方安全审计:首份报告发布于2020年2月,我们借此发现并修复了多种极端案例及高严重性问题。关于更多详细信息,请参阅:https://github.com/etcd-io/etcd/blob/master/security/SECURITY_AUDIT.pdf。
为了遵循最高级别的安全最佳实践,etcd现采取一套安全发布流程[3],并使用静态分析工具运行自动化测试,包括errcheck,ineffassign等。
功能拓展

etcd面向结构化日志记录的迁移工作已经完成。现在etcd默认使用zap记录器,其中采用一项无反射、零分配JSON编码器。我们已经正式弃用基于反射的capnslog序列化记录工具。
etcd现可支持内置日志轮替,允许你配置轮替阈值、压缩算法等细则。关于更多详细信息,请参阅:https://github.com/etcd-io/etcd/pull/12774。
etcd现可针对高资源需求量请求发出更详尽的跟踪信息,例如:
{
"caller":"traceutil/trace.go:116",
"msg":"trace[123] range",
"detail":"{
range_begin:foo;
range_end:fooo; response_count:100000; response_revision:191496;}",
"duration":"132.449773ms",
"start":"...:32.611-0700",
"end":"...:32.744-0700",
"steps":[
"trace[123] step 'range keys from bolt db' (duration: 92.521911ms)",
"trace[123] step 'filter and sort the key-value pairs' (duration: 22.789099ms)"]}
这项功能将为跨越多个etcd服务器组件的请求提供非常实用的生命周期管理信号。具体请参阅:https://github.com/etcd-io/etcd/pull/11179。
每套etcd集群都维护有自己的集群版本,具体版本由集群自身按法定人数投票决定。以往,为了防止发生不兼容的变更,我们并不支持对集群版本进行降级(例如将etcd由3.5降级至3.4次要版本)。
假定我们允许3.3版本的节点加入3.4版本的集群,并向领导者发送租用检查点的请求,但这项请求在etcd 3.4版本才刚刚出现。在3.3版本的节点收到租用检查点请求时,将无法处理这项未知申请(详见etcd服务器申请代码[4])。然而,人们可能不会使用这样的租用检查点功能,而是倾向于冒着影响兼容性的风险进行版本降级(将3.4版本降级至3.3)。为了确保此类回滚能够简单可靠地实现,我们添加了新的降级API,用于验证、启用及取消etcd版本降级操作。关于更多信息,请参阅:https://github.com/etcd-io/etcd/pull/11715。
通过仲裁协议,etcd集群成员将与写入方拥有相同级别的一致性保障。但以往,成员清单调用将直接由服务器的本地数据负责提供,而这部分数据可能已经过时。现在,etcd能够以线性化方式保证为成员清单提供支持——如果服务器与仲裁端断开连接,则成员调用操作将失败。具体请参阅:https://github.com/etcd-io/etcd/pull/11639。
gRPC网关端点现已在/v3/*下获得稳定保证。gRPC网关会生成一个HTTP API,使得基于etcd gRPC的HTTP/2协议也可通过HTTP/1进行访问,例如:
curl -X POST -L http://localhost:2379/v3/kv/put -d '{"key": "Zm9v", "value": "YmFy"}'
etcd客户端现可使用最新的gRPC v1.32.0,但这需要使用新的导入路径"go.etcd.io/etcd/client/v3",并将均衡器实现迁移至上游。关于更多详细信息,请参阅:https://github.com/etcd-io/etcd/pull/12671。
Bug修复

etcd的可靠性与正确性至关重要。正因为如此,我们才将所有关键bug修复逆向移植至以往的etcd版本。下面来看我们在etcd 3.5开发过程中发现并修复的各项严重bug:
租约对象规程导致内存泄漏,解决方法是清除旧leader中的过期租约队列,详见:https://github.com/etcd-io/etcd/pull/11731
持续compact操作可能导致mvcc存储层死锁。详见:https://github.com/etcd-io/etcd/pull/11817
etcd服务器重启后,存在多余的后端数据库打开操作并导致重载4000万个键耗费掉5分钟时间。解决方案将重启时间缩短为一半,详见:https://github.com/etcd-io/etcd/pull/11779
如果etcd在完成碎片整理之前崩溃,则下一次碎片整理操作可能读取到已经损坏的文件。解决方案是忽略并直接覆盖现有文件。具体请参阅:https://github.com/etcd-io/etcd/pull/11613
客户端取消watch时没有向服务器发出信号,因此可能导致所创建watcher外泄。解决方案是向服务器显式发送取消请求,具体参见:https://github.com/etcd-io/etcd/pull/11613
性能改进

作为etcd最重要的用户之一,Kubernetes会查询整个键空间以罗列并监控集群资源。每当在kube-apiserver反射器缓存中找不到资源时,即会发生这项范围查询(例如请求的etcd修订版已被压缩,详见kube-apiserver v1.21 code[5]),由此导致etcd服务器过载并引发读取缓慢。在这种情况下,kube-apiserver跟踪会发出如下警告:
"List" url:/api/v1/pods,user-agent... (started: ...) (total time: 1.208s): Trace[...]: [1.208s] [1.204s] Writing http response done count:4346
而etcd给出的警告如下所示:
etcdserver: read-only range request key:"/registry/pods/" range_end:"/registry/pods0" revision:... range_response_count:500 size:291984 took too long (723.099118ms) to execute
我们对etcd堆配置文件进行了深入研究,并发现服务器警告记录器效率低下的主要原因,在于该记录器中存在冗余的编码操作,仅用于使用proto.Size调用计算范围响应的大小。在其影响下,大范围查询的堆分配开销高达60%,因此会导致在过载的etcd服务器中发生内存不足崩溃或OOM(参见图一)。我们优化了协议部级区消息大小的相关操作,使得峰值使用期间etcd的内存消耗量降低了50%(参见图二)。虽然具体变更只涉及少量代码,但如果没有多年以来广泛的测试与工作负载模拟,这样的性能改进根本不可能实现。具体请参阅:https://github.com/etcd-io/etcd/issues/12835与https://github.com/etcd-io/etcd/pull/12871。
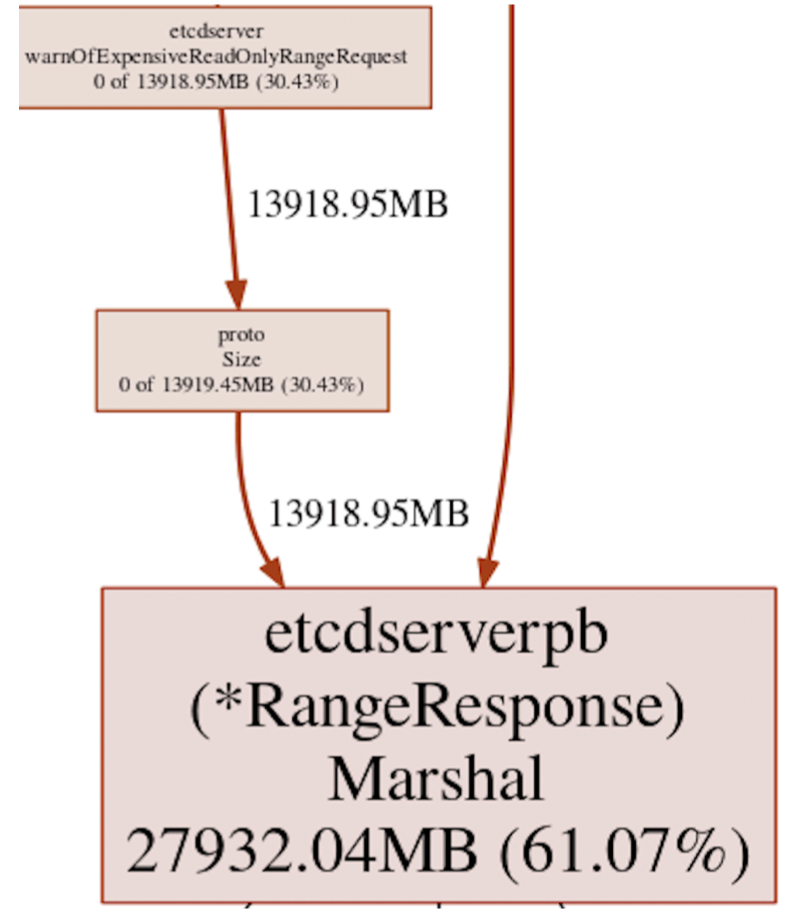
图一:用于计算协议缓冲区消息响应大小的缓慢请求警告日志,其中记录了期间etcd堆的使用情况。有61%的堆被分配给proto.Size调用路径当中,此调用路径负责对消息内的所有键值进行编码以计算其大小。
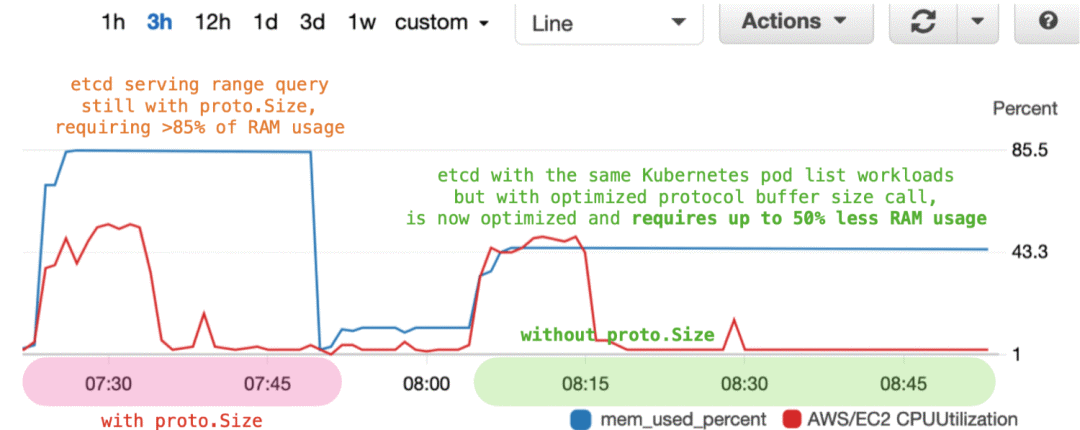
图二:在替换proto.Size调用之前与之后,etcd堆的不同使用情况。经过优化,etcd服务器中proto.Size调用所点明禾的内存量降低了50%。
etcd 3.4版本通过复制事务缓冲区(而非在写入就并发读取之间共享)实现后端读取事务的完全并发。但这种缓冲机制不可避免地带来复制开销,并给写入密集型事务的性能产生了负面影响。这是因为创建并发读取事务需要互斥锁,而这会阻塞传入的写入事务。
etcd 3.5通过改进进一步提升了事务并发性水平。
如果事务中包含一项PUT(更新)操作,则此事务在读取与写入之间共享事务缓冲区(同3.4版本中的设定)以避免复制缓冲区。这种事务处理模式可通过etcd --experimental-txn-mode-write-with-shared-buffer=false禁用。
基准测试结果表明,通过在创建写入事务时避免复制缓冲区,高写入率事务的吞吐量增长了2.7倍(详见图三与图四)。这有利于一切指向使用etcd事务的kube-apiserver的创建与更新调用。关于更多详细信息,请参阅:https://github.com/etcd-io/etcd/pull/12896
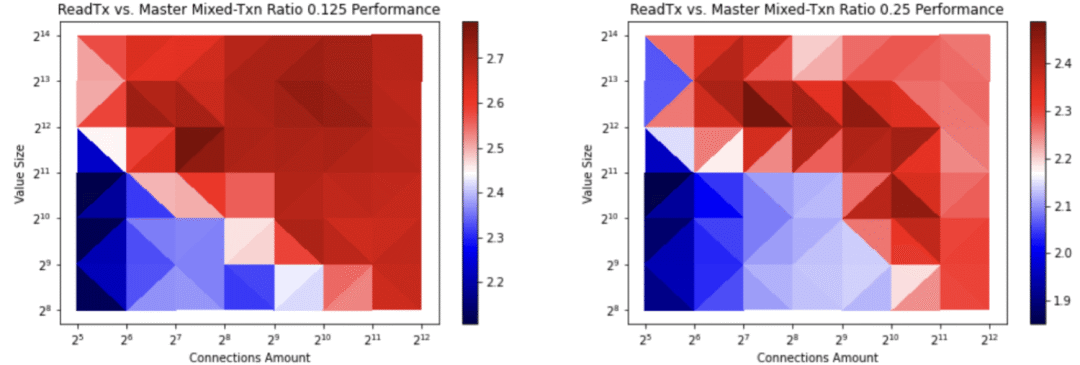
图三:具有高写入率的etcd事务率。顶部的值为读取与写入间的比例。第一项比率0.125代表每发生8次写入,对应1次读取。第二项比率0.25代表每发生1次读取,对应发生4次写入。右边栏的数值代表的是etcd/pull/12896事务前后吞吐量的反比。使用共享缓冲区写入方法,事务的吞吐量提升了2.7倍。
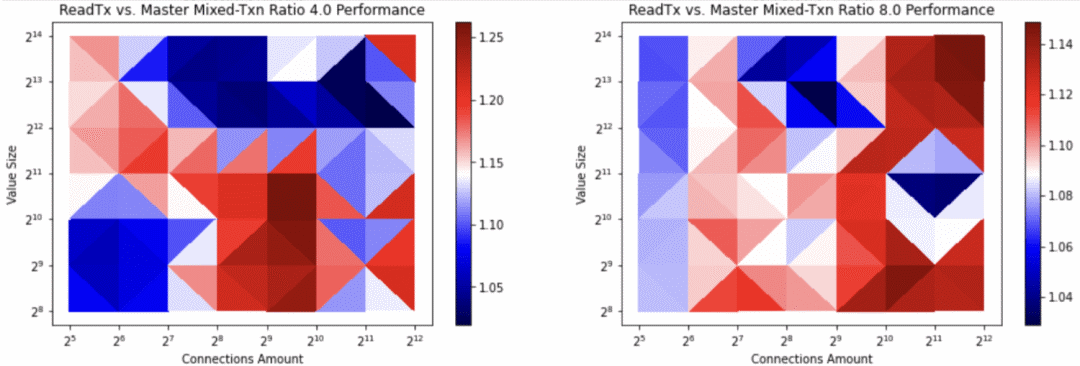
图四:具有高读取率的etcd事务率。顶部的值为读取与写入的比率。第一项比率4.0代表每1次写入对应4次读取。第二项比率8.0代表第1次写入对应8次读取。右边栏的数值代表的是etcd/pull/12896事务前后吞吐量的反比。使用共享缓冲区写入方法,事务的吞吐量提升了25%。
etcd现在会缓存事务缓冲区以避免不必要的复制操作。这加快了并发读取事务的创建速度,借此将具有高读取率的事务速率提升了2.4倍(详见图五与图六)。具体参见:https://github.com/etcd-io/etcd/pull/12933
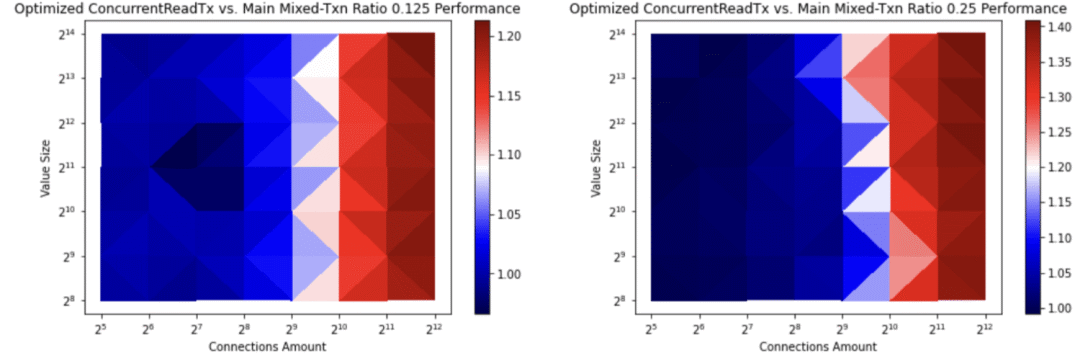
图五:具有高写入率的etcd事务率。顶部的值为读取与写入间的比率。第一项比率0.125代表每发生8次写入,对应1次读取。第二项比率0.25代表每发生1次读取,对应发生4次写入。右边栏的数值代表的是etcd/pull/12933事务前后吞吐量的反比。使用共享缓冲区写入方法,事务的吞吐量提升了1.4倍。
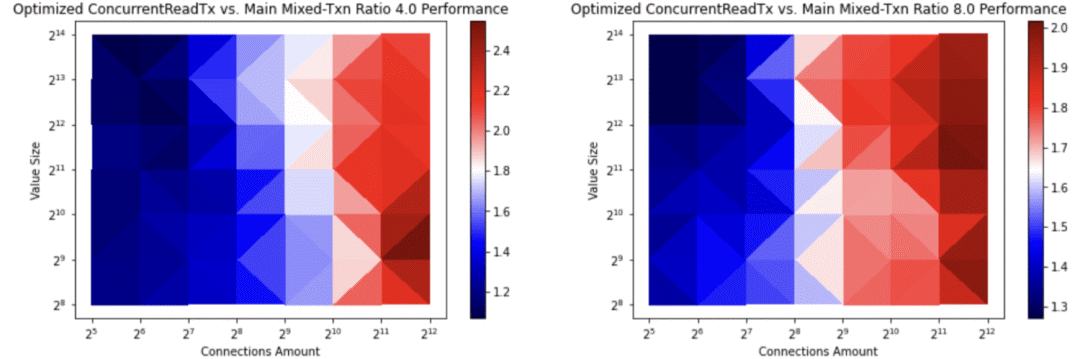
图六:具有高读取率的etcd事务率。顶部的值为读取与写入的比率。第一项比率4.0代表每1次写入对应4次读取。第二项比率8.0代表第1次写入对应8次读取。右边栏的数值代表的是etcd/pull/12933事务前后吞吐量的反比。使用共享缓冲区写入方法,事务的吞吐量提升了2.5倍。
监控功能

长期运行的负载测试表明,etcd服务器会掩盖Go语言的垃圾回收机制并歪曲实际内存使用情况。我们发现,使用Go 1.12的etcd服务器会变更运行时以使用Linux内核中的MADV_FREE,因此回收的内存没有被反映在常驻集大小或RSS指标当中。这使得etcd内存使用指标发生了意外且错误的静态化,因此无法体现Go垃圾回收机制的效果。为了解决这个监控问题,我们使用Go 1.16编译了etcd 3.5,其在Linux上默认为MADV_DONTNEED。关于更多详细信息,请参阅:https://github.com/golang/go/issues/42330
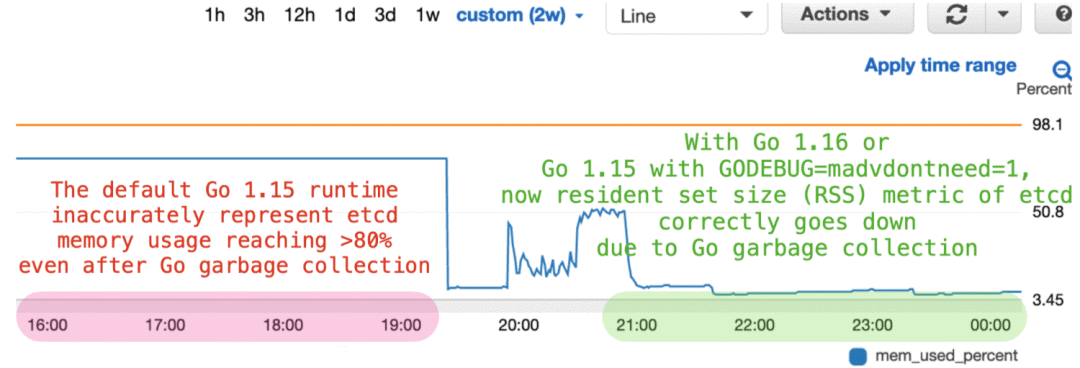
图七:在Go运行时设置为MADV_DONTNEED前后,etcd在执行范围查询时的内存使用情况。当使用GODEBUG=madvdontneed=1"或者Go 1.16及更高版本时,etcd服务器在CloudWatch mem_used指标或其他监控工具(例如top)中能够准确报告内存使用情况。
监控是一项用于支持可靠性与可观察性的基础服务。准确有力的监控将帮助各服务所有者充分理解当前状态,并确定问题报告的潜在原因。以此为基础,大家可以检测早期预警信号并诊断潜在问题。etcd能够创建出带有跟踪信息的服务器日志并发布Prometheus指标。
利用这部分信息,我们可以确定潜在的服务影响与发生原因。然而,当某条请求调用链跨越多种外部组件时(例如从kube-apiserver到etcd),我们就很难识别出问题。为了高效确定根本原因,我们使用OpenTelemetry添加了分布式跟踪支持:启用分布式跟踪机制后,etcd现在可使用OpenTelemetry生成跨RPC调用链的跟踪路径,由此轻松与周边生态系统相集成。详见图八,https://github.com/etcd-io/etcd/pull/12919与 https://github.com/etcd-io/etcd/issues/12460。
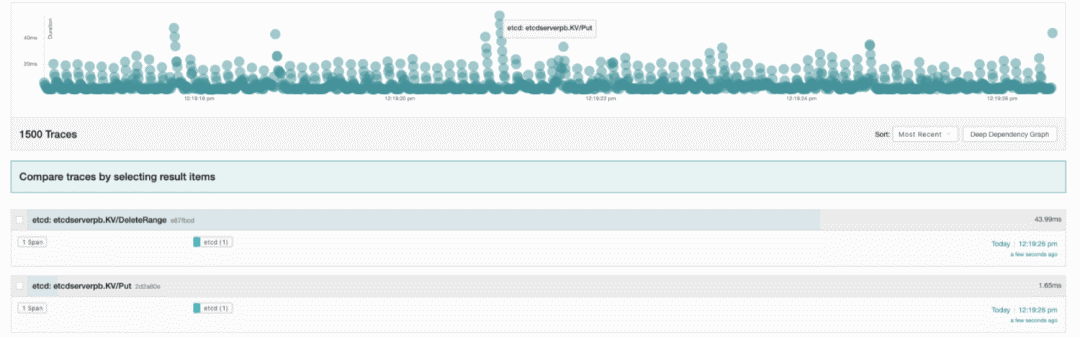
图八:用于etcd的jaeger跟踪UI示例。
测试功能

分布式系统当中充满了微妙的极端状况。某些bug很可能只在特殊情况下出现,这意味着简单的单元测试根本无法覆盖实际使用情况。为此,etcd引入了集成、端到端以及故障注入测试,借此以更可靠、更高效的方式验证每一项变更。但随着扩展功能集的不断发展与膨胀,测试问题也开始快速规程,几乎耗尽我们的生产力。我们面临着种种艰难的任务,往往需要几个小时的调试才能找出引发问题的根本原因。为了提高测试质量,我们在新版本中实现了以下改进:
将单元测试运行时长缩短一半(https://github.com/etcd-io/etcd/pull/12286)
配置测试记录器(https://github.com/etcd-io/etcd/pull/12753)
简化测试数据清理步骤(https://github.com/etcd-io/etcd/pull/12805)
在测试后关闭gRPC服务器(https://github.com/etcd-io/etcd/pull/12782)
平台支持

etcd的提交前测试已经达成了快速与可靠两大重要目标,但问题在于其目前主要支持x86处理器。社区中有不少声音呼吁我们支持更多其他架构,例如ARM与s390x。为此,我们推出了GitHub自托管操作运行器[6],它会以统一的方式托管各类外部测试工具。使用GitHub操作运行器,etcd现在可以在基于ARM架构的AWS EC2实例(Graviton)上运行测试,从而正式支持ARM64(aarch64)平台。此外,我们还引入了一种新的多平台支持机制,并根据测试覆盖率对支持能力进行划分。关于更多详细信息,请参阅:https://github.com/etcd-io/website/pull/273与https://github.com/etcd-io/website/pull/273。
开发者体验

为了更好地支持与外部项目的集成能力,etcd现在全面采用Go 1.16模块。这当然也带来了挑战,因为现有代码库使得迁移工作变得困难重重,也引发了关于社区是否乐于接纳的担忧。工具一直是etcd发展过程中的重要组成部分,因此我们需要一套更好的解决方案以支持我们的贡献者体验。
使用Go模块,我们得以将服务器与客户端代码之间建立起清晰边界,降低了对依赖项更新的变更管理难度,同时打造出一套可验证的构建系统、且不会对供应商的复杂代码库造成影响。有了这套可重现的构建解决方案,我们不再需要直接提供依赖项,借此将etcd代码库的体积削减了一半。具体请参见:https://docs.google.com/document/d/19UvKD7by_fEkzLMRi-QNSKEed4kYAW286S3DsNRPDOM/edit与https://github.com/etcd-io/etcd/pull/12279。
为了更好地隔离依赖树,etcd命令行界面现在引入了新的管理工具etcdutl(请注意,不是etcdut-i-l),其子命令包括etcdutl snapshot与etcdutl defrag。此项变更与新的Go模块布局高度吻合:etcdctl仅依赖于客户端v3库,而etcdutl则可能依赖于etcd服务器端包,例如bolt及后端数据库代码。具体请参阅:https://github.com/etcd-io/etcd/pull/12971。
为了支持包容性命名计划,etcd项目将默认分支master重命名为main。此次变更将无缝进行,GitHub方面将负责处理必要的重新定向工作。
每一次etcd写入都会在Raft中产生一条附加消息,并将其同步至磁盘。但是这种持久性可能并不适合测试场景。为了解决这个问题,我们添加了etcd-unsafe-no-fsync标记以绕过Raft WAL的磁盘写入操作。具体请参阅:https://github.com/etcd-io/etcd/pull/11946与https://github.com/etcd-io/etcd/issues/11930。
社区建设

etcd最终用户的多样性不断扩大:Cloudflare依靠etcd管理其数据中心,Grafana Cortex将其配置数据存储在etcd之内,Netflix Titus使用etcd管理其容器工作负载,而Tailscale则在etcd之上运行其控制平面。
我们还扩展了供应商贡献者规模。在etcd 3.5版本中,我们迎来两位新增核心维护者:来自谷歌、一直领导etcd社区会议与Kubernetes集成工作的Wenjia Zhang,以及同样来自谷歌、长期负责bug修复与代码库模块化工作的Piotr Tabor。贡献者的多样性是构建可持续、高人气开源项目并改善工作环境可管理性的必要前提。
关于更多详细信息,请参阅:https://www.cncf.io/cncf-etcd-project-journey-report。
新的etcd.io

自从etcd项目于2018年12月加入云原生计算基金会(CNCF)以来,我们已经将全部面向用户的文档重构为专用库etcd-io/website[7],并使用Hugo完成了对网站托管的现代化改造。这项迁移是一项艰巨的任务,需要长达数月的时间投入与维护人员间的相互沟通。这里要感谢lucperkins@[8]、CNCF的chalin@[9]以及nate-double-u@[10]的大力支持,也感谢其他社区贡献者的积极协助。
发展路线图

流量过载会导致级联节点故障,为此,集群的扩展一直是项颇具挑战的工作,甚至可能削弱由仲裁丢失中恢复过来的能力。但考虑到大量关键任务系统已然建立在etcd基础之上,保护etcd免受过载影响无疑至关重要。我们将重新审视etcd节流功能,借此更好地缓解过度负载。目前,etcd项目拥有两项尚未决定的限速机制提案:https://docs.google.com/document/d/1wQQ_L3cLyI1t14zp-PvarbjJYtlRsz_P9LwDR3uelc8/edit#heading=h.jofsq6eav4x7与https://github.com/etcd-io/etcd/pull/12290。
来自kube-apiserver的大范围查询仍是导致进程崩溃的最主要根源,其情况也相对难以预测。我们对此类工作负载的堆配置文件进行了研究,并发现etcd范围请求处理程序在整个响应发送至gRPC服务器前会解码并保存整个响应,这会额外增加37%不必要的堆分配负载。具体参见:https://github.com/etcd-io/etcd/issues/12835。
客户端代码中的分页范围调用并不能完全解决这个问题,因为其中还涉及额外的一致性考量。为了解决这个低效难题,etcd需要支持范围流。我们将重新审视https://github.com/etcd-io/etcd/pull/12343,但这项提案要求投入大量努力以在etcd乃至下游项目中全面引入新的语义变化。
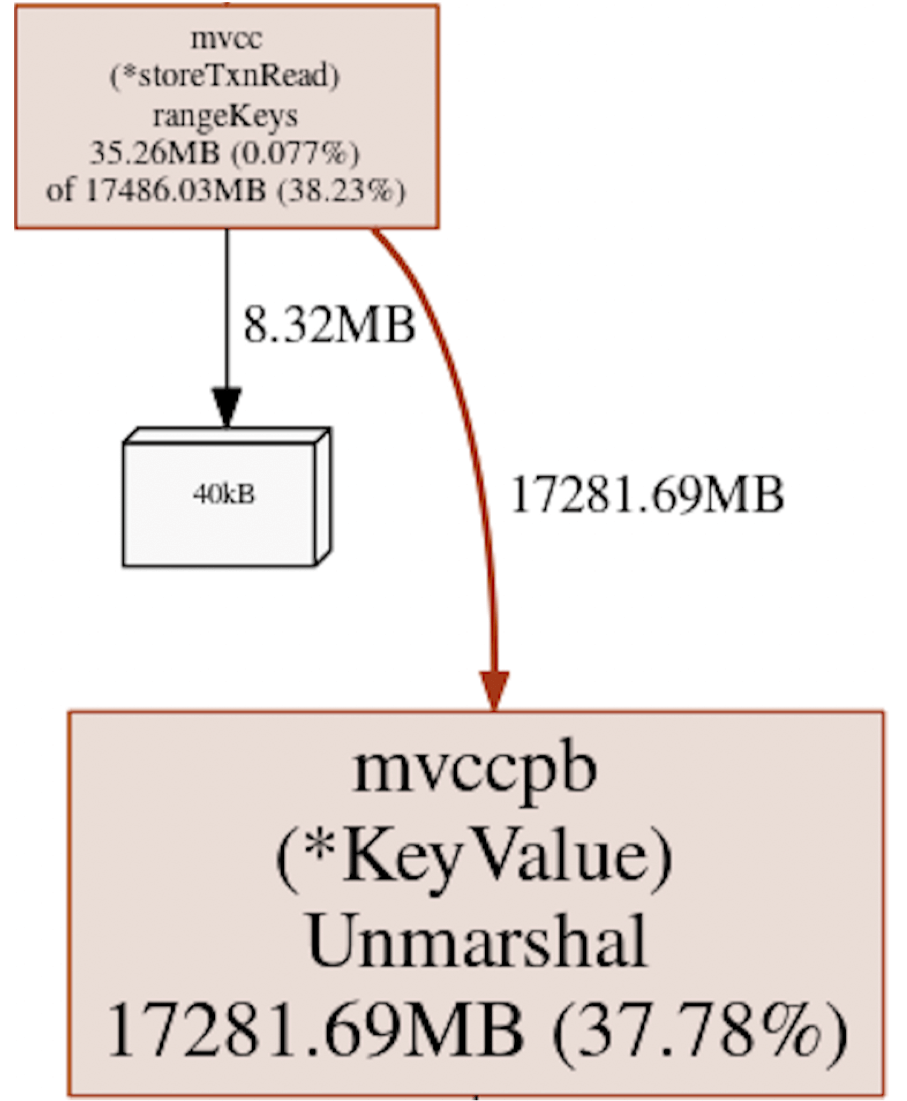
图九:在罗列Kubernetes Pod范围查询期间的etcd使用情况。可以看到,37%的堆分配被用于在etcd mvcc rangeKeys中保存键值对以创建范围查询响应。
为了降低维护开销,我们完全弃用了etcd v2 API,转而使用性能更高且已经得到广泛采用的v3 API。通过etcd --experimental-enable-v2v3实现的v2存储转换层在此次3.5版本中仍处于实验阶段,并将在下个版本中被删除。关于更多细节,请参阅:https://github.com/etcd-io/etcd/issues/12913。
纵观整个发展历程,受到频度低、增量大以及发布自动化等现实条件的影响,etcd发布一直是项艰巨的任务。我们也将着手开发一套更易于社区访问的自动发布系统,敬请期待!
相关链接:
https://github.com/etcd-io/etcd/blob/master/CHANGELOG-3.5.md
https://etcd.io/docs/v3.5/install/
https://github.com/etcd-io/etcd/blob/master/security/security-release-process.md
https://github.com/etcd-io/etcd/blob/v3.3.25/etcdserver/apply.go#L119-L170
https://github.com/kubernetes/kubernetes/blob/v1.21.0/staging/src/k8s.io/client-go/tools/cache/reflector.go#L302-L312
https://docs.github.com/en/actions/hosting-your-own-runners/adding-self-hosted-runners
https://github.com/etcd-io/website
https://github.com/lucperkins
https://github.com/chalin
https://github.com/nate-double-u
原文链接:https://etcd.io/blog/2021/announcing-etcd-3.5/
Kubernetes线下培训

本次培训在上海开班,基于最新考纲,通过线下授课、考题解读、模拟演练等方式,帮助学员快速掌握Kubernetes的理论知识和专业技能,并针对考试做特别强化训练,让学员能从容面对CKA认证考试,使学员既能掌握Kubernetes相关知识,又能通过CKA认证考试,学员可多次参加培训,直到通过认证。点击下方图片或者阅读原文链接查看详情。


















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









