






1.Simple function
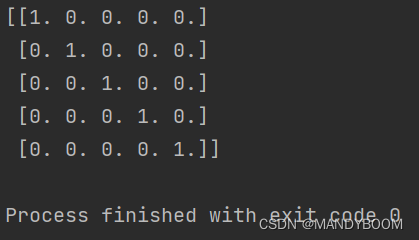
返回一个5x5的单位矩阵
import numpy as np//用到了numpy.eye(),所以先导包
A = np.eye(5) //创建矩阵
print(A) //输出- 输出:
2.Linear regression with one variable
通过城市人口,预测小吃车的利润
- 先导入数据(人口、利润),数据读取方法用到read_csv,所以需要导pandas包
import pandas as pd //导包
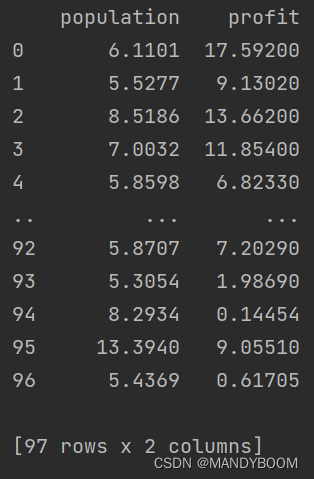
data = pd.read_csv("D:\Pycharm\Machine-Learning\ex1\ex1data1.txt",names=["population","profit"])) //读取数据,并将第一列数据命名为population,第二列profit
print(data)//打印- 打印,结果如下,说明数据导入成功
2.1 Plotting the Data(绘制数据)
用点状图画出上面导入的数据
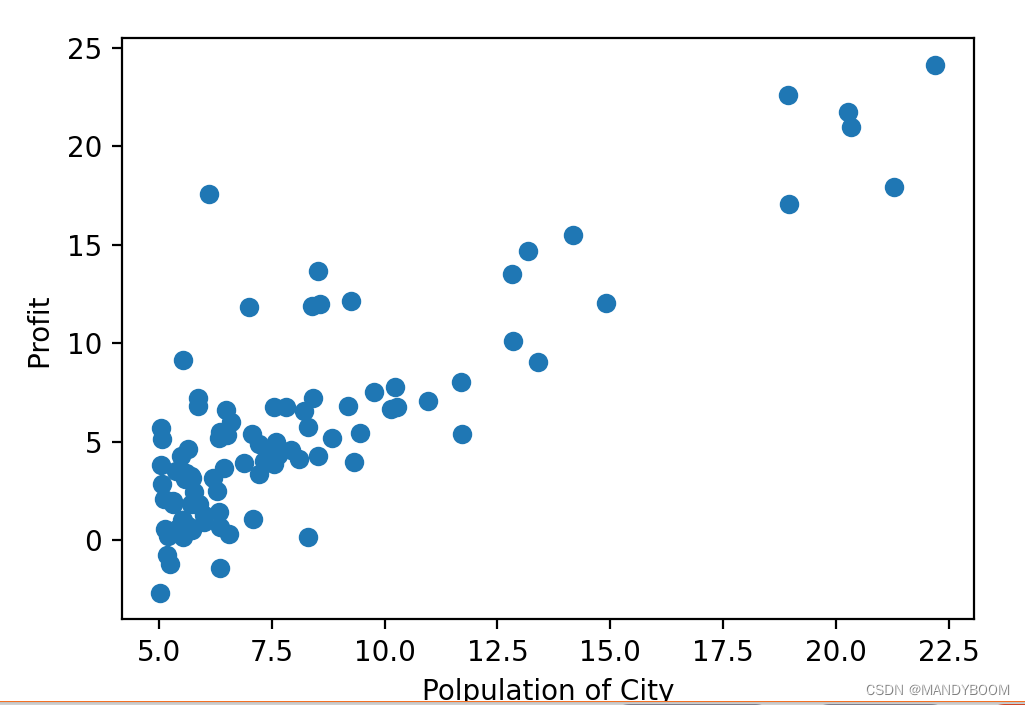
- 绘图需要Pyplot,它是常用的绘图模块,能很方便绘制 2D 图表,并且它是Matplotlib的一个子库,所以需要先导入。然后用到scatter(x,y)这个函数绘制点状图,并将x,y设置好,x为人口,y为利润。
import matplotlib.pyplot as plt//导包
X = data.population//设置x、y变量
Y = data.profit
plt.scatter(X,Y) //绘制点状图
plt.xlabel("Polpulation of City") //设置x、y轴含义
plt.ylabel("Profit ")
plt.show()//输出图像- 图像如图所示:
2.2 Gradient Descent(梯度下降)
使用梯度下降将线性回归参数 θ 拟合到数据集。
2.2.1 Update Equations(更新方程)

2.2.2 Implementation
- 将上面的公式向量化后,用代码进行定义
def J(X,Y,theta):
cost = np.sum((X.dot(theta)-y)**2)/(2*len(X))
return cost2.2.3 Computing the cost J(θ
- 将数据带入公式
data = np.array(data) //将数据转换为数组形式,方便计算代价函数
X = data[:,0].reshape(-1,1) //将X也就是人口,从数据中的第一列数值取出,并在数组中转换成一列的形式
X = np.hstack([np.ones((len(X),1)),X])//给X添加一列全为1的元素,使用np.hstack,水平方向堆叠,np.ones可以生成一列元素
Y = data[:,1].reshape(-1,1)//将Y也就是利润,从数据中的第二列数值取出,并在数组中转换成一列的形式
theta = np.zeros(X.shape[1]).reshape(-1,1)//将theta初始化为0
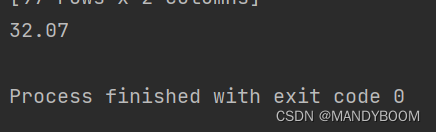
result = round(J(X,Y,theta),2) //运行定义的方法(函数公式)并保留2位小数
print(result) //输出代价函数值
- 输出结果为32.07,值较高,因此需要进行梯度下降
2.2.4 Gradient descent(开始梯度下降)
不断更新θ,使最小化

- 先求代价函数的导数为
- 代码定义代价函数的导数
def dJ(theta,X,Y) //定义导数
res = X.T.dot(X.dot(theta)-Y)/len(X) //导数等于
return res //返回导数值- 更新θ,定义求参数θ的公式(梯度下降)
def gradient_descent(dJ,X,Y,initial_theta,alpha,iters=1500,epsilon=1e-8)//定义,输入数据的参数,除了利润、人口,还有学习率,迭代次数,以及一个非常小的差值,当代价函数插值非常小,基本上趋于稳定,此时最小化代价函数值
theta = initial_theta //使θ等于最初值
now_iters = 0 //此时迭代次数为0
while now_iters<iters: //只要迭代次数没到1500就循环
gradient = dJ(theta,X,Y)
last_theta = theta //保留上一个θ值
theta = theta - alpha*gradient //更新
if(abs(J(X,Y,theta)-J(X,Y,last_theta))<epsilon): //代价函数趋于不变跳出循环
break
now_iters += 1 //否则,迭代次数加一,继续更新
return theta//最后返回最佳θ值- 调用梯度下降的方法
theta = [0,0] //初始化θ
theta = gradient_descent(dJ,X,Y,theta,alpha=0.01,all_iters=1500)//调用梯度下降算法
print(theta)//打印结果为最优θ值- 结果为如图,因为假设函数为
,故结果为最优截距和斜率

- 对 θ 的最终值也将用于预测35,000 和 70,000 人的地区的利润是多少,利用参数进行数据拟合并可视化。预测函数为
predict1 = np.array([1,3.5]).dot(theta) predict2 = np.array([1,7]).dot(theta) print("3w5人口的城市小吃车利润是:",predict1) print("7w人口的城市小吃车利润是:",predict2)结果为:

- 绘制最终的预测函数图像
plt.scatter(data[:,0],data[:,1])//绘制点状图
plt.plot(X[:,1],X.dot(theta),color='r')//绘制预测函数的线型图
plt.xlabel("population of city")//设置坐标含义
plt.ylabel("profit")
plt.show()//输出图像- 最终的利润预测图像为
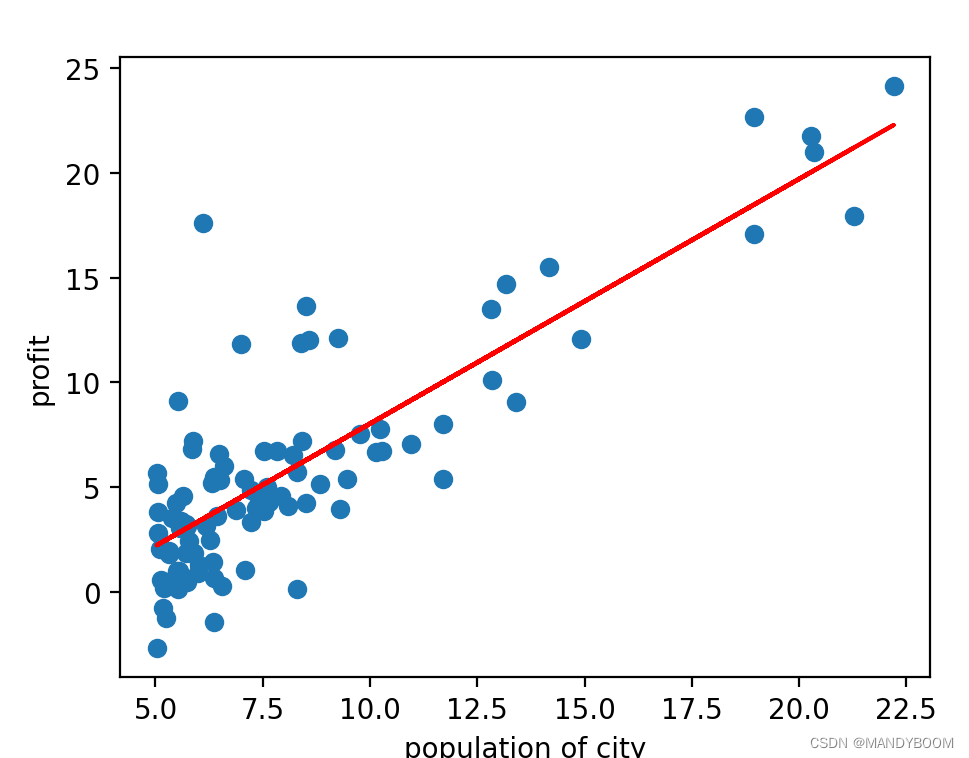
- 绘制代价函数的图像
iters=1500 print(np.shape(cost)) plt.plot(np.arange(iters),cost,color='r') plt.xlabel("Iterations") plt.ylabel("Cost") plt.show()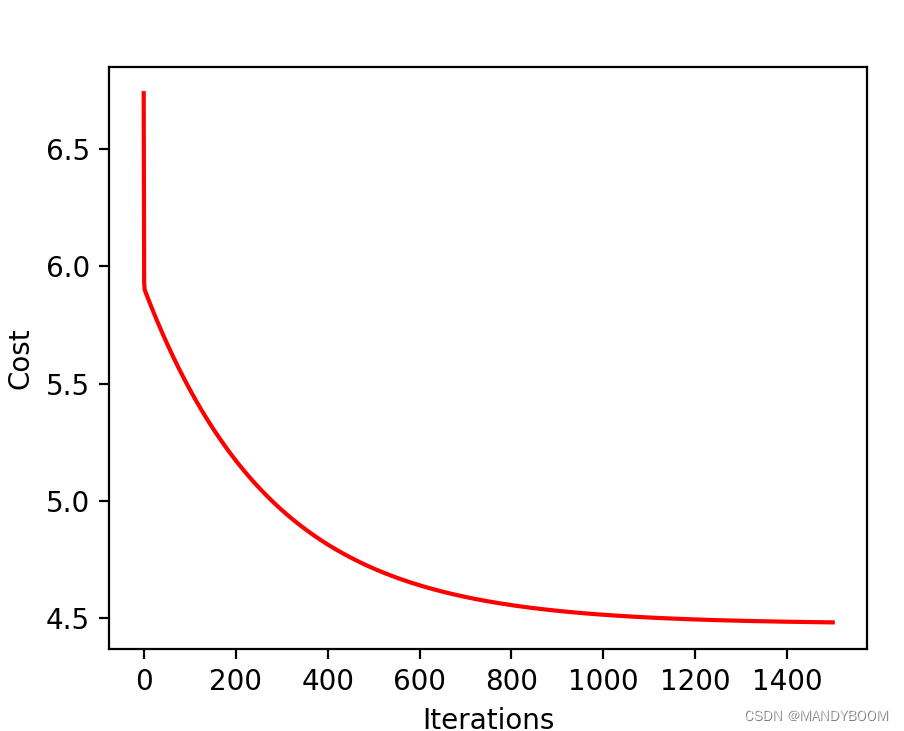















 1688
1688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









