






简介
Fetch是一个提供网页内容抓取功能的模型上下文协议服务器。此服务器使大型语言模型能够从网页中检索和处理内容,并将 HTML 转换为 markdown 以便更容易地使用。
获取工具会截断响应,但通过使用 start_index 参数,您可以指定从何处开始提取内容。这让模型可以分块读取网页,直到找到所需的信息。
可用工具
-
fetch - 从互联网上抓取一个 URL 并将其内容作为 markdown 提取。
-
url (字符串, 必需): 要抓取的 URL
-
max_length (整数, 可选): 返回的最大字符数 (默认: 5000)
-
start_index (整数, 可选): 从此字符索引开始提取内容 (默认: 0)
-
raw (布尔值, 可选): 获取未经 markdown 转换的原始内容 (默认: false)
-
提示
-
fetch
-
抓取一个 URL 并将其内容作为 markdown 提取
-
参数:
-
url (字符串, 必需): 要抓取的 URL
-
-
配置
在 Cursor 的 Cursor Settings 中找到 MCP,点击右侧上方的 Add new global MCP server 按钮,便自动打开 mcp.json文件,然后将mcp server 的配置信息粘贴进去。
{
"mcp": {
"servers": {
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
}
}实操
通过Fetch 快速生成科技日报,输入 URL,Fetch去把内容弄回来,然后把乱七八糟的 HTML 转成干净的 Markdown(还能支持其他格式,比如纯文本),把抓来的内容通过 MCP 接口丢给智能体处理,最后整理出来科技日报。
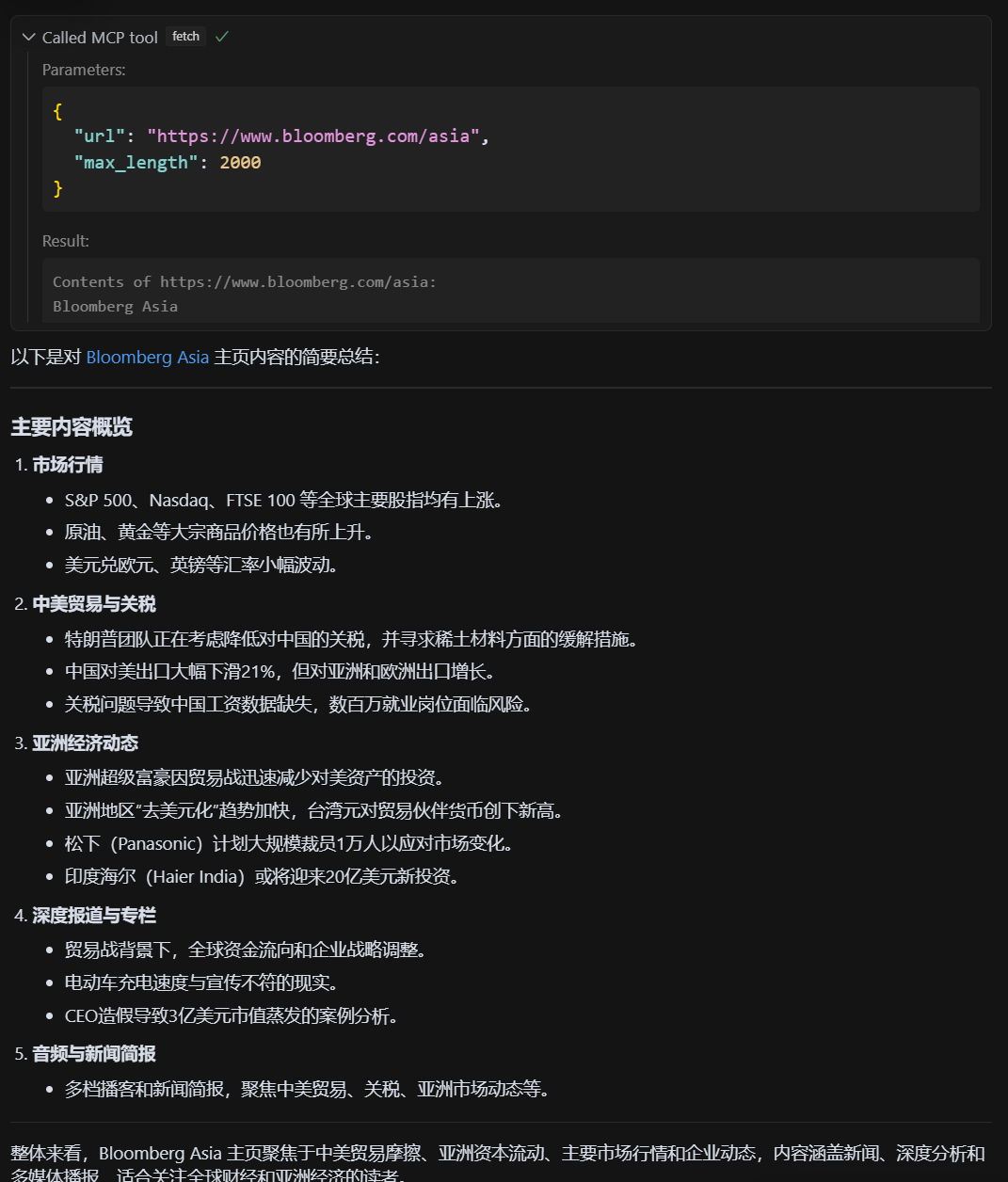
请用fetch工具,帮我总结下链接内容@https:/www.bloomberg.com/asia
将会调用fetch工具,梳理网页内容,调用结果如下图:
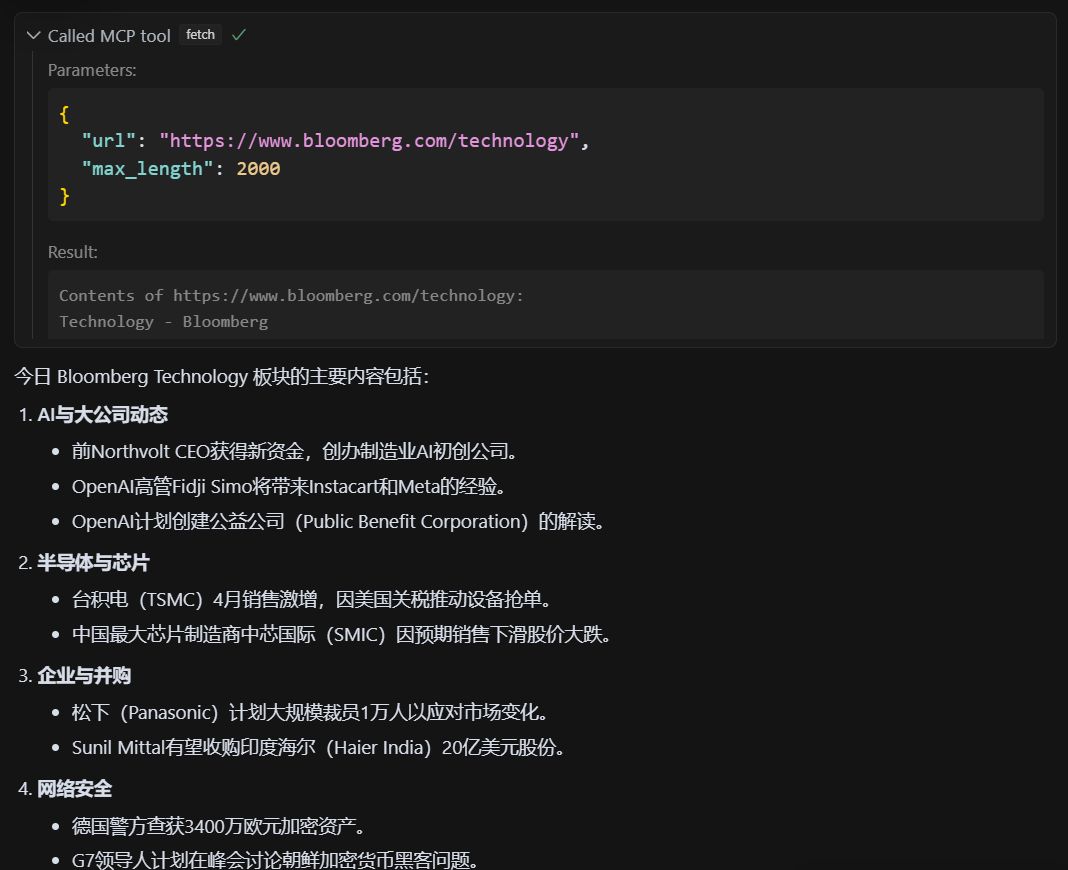
帮我找下里面下Bloomberg Technology板块,今日有什么内容
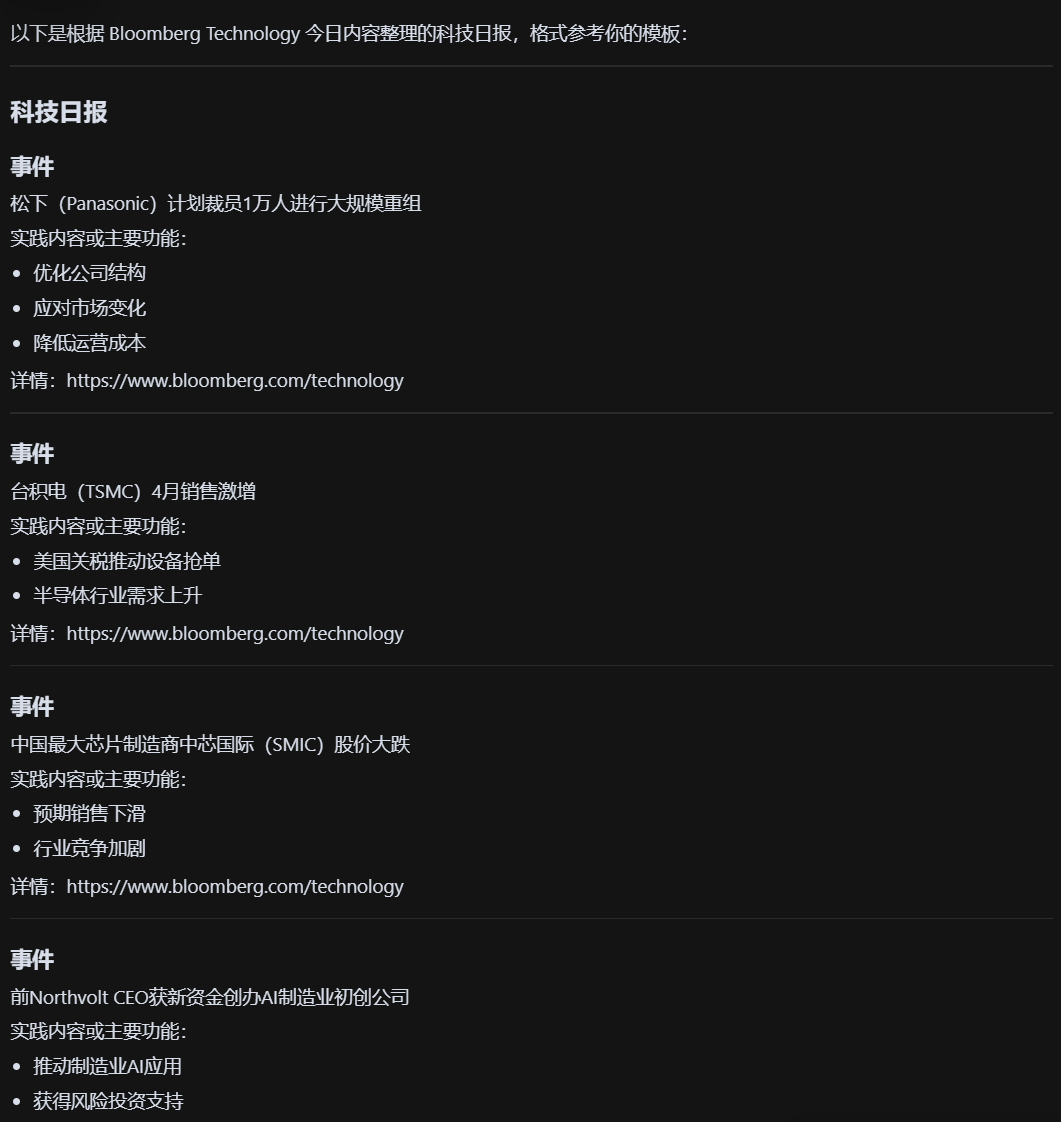
帮我整理整一个科技日报,参考模板
事件
实践内容或注要功能(一句话描达内容,或者列举最多3个点)
详情:url地址
复制链接,打开网址,如下图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









