







前言
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
一、安装scrapy
1、命令行
pip3 install scrapy -i https://pypi.douban.com/simple/
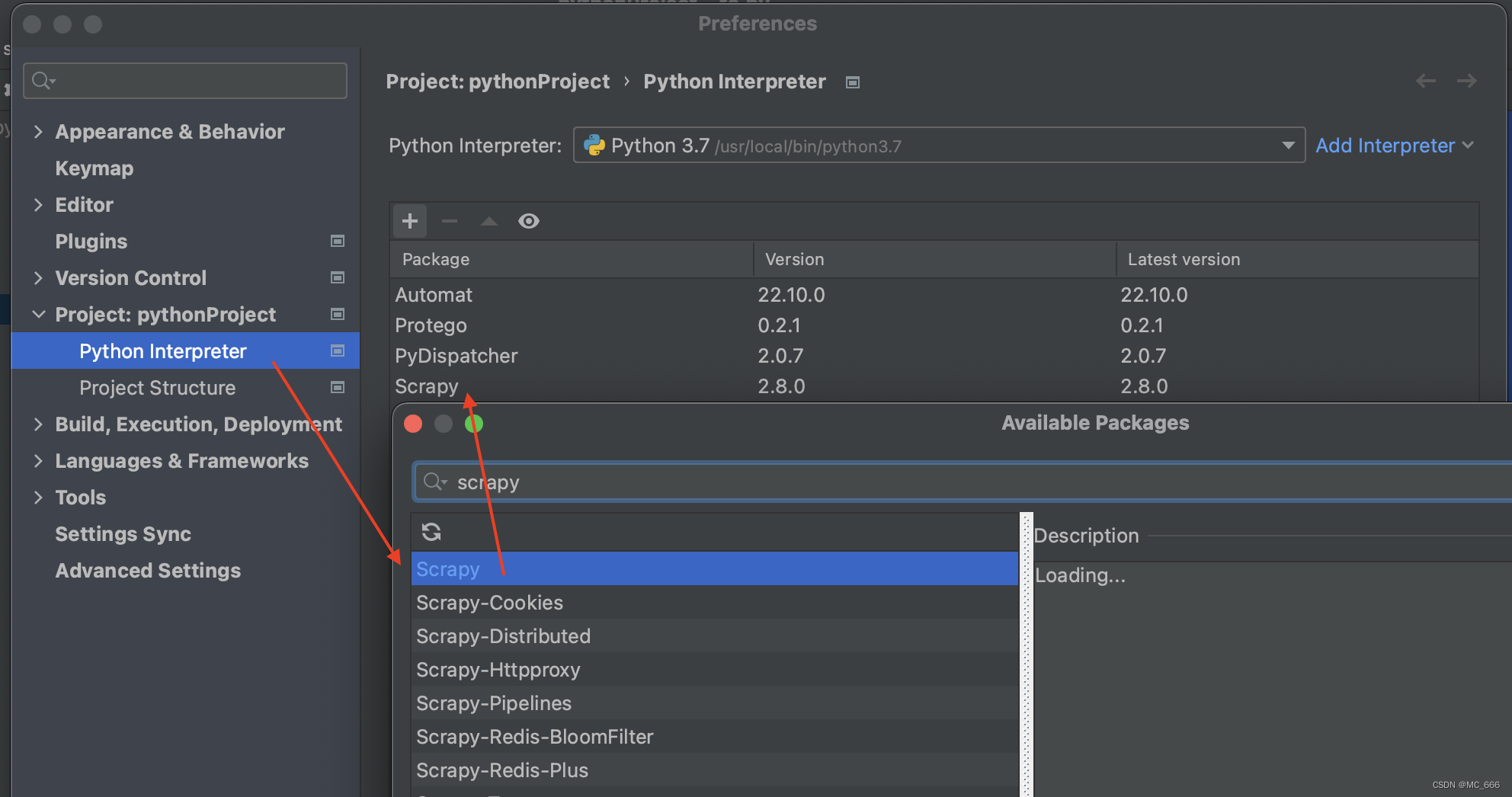
2、pycharm添加包
二、使用步骤
1.创建项目
1、创建项目
scrapy startproject scrapy_58tc
New Scrapy project 'scrapy_58tc', using template directory '/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/scrapy/templates/project', created in:
/Users/yingyan/PycharmProjects/pythonProject/scrapy_58tc
You can start your first spider with:
cd scrapy_58tc
scrapy genspider example example.com
2、进入目录
bogon:pythonProject yingyan$ cd scrapy_58tc/scrapy_58tc/spiders
3、创建
scrapy genspider tc https://tj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=classify_B
结果
[1]+ Done scrapy genspider tc https://tj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91
4、运行
bogon:spiders yingyan$ scrapy crawl tc
成功打印,说明运行成功
2023-02-18 15:29:20 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://tj.58.com/> (referer: None)
哈喽爬虫
2023-02-18 15:29:20 [scrapy.core.engine] INFO: Closing spider (finished)
2.目录结构
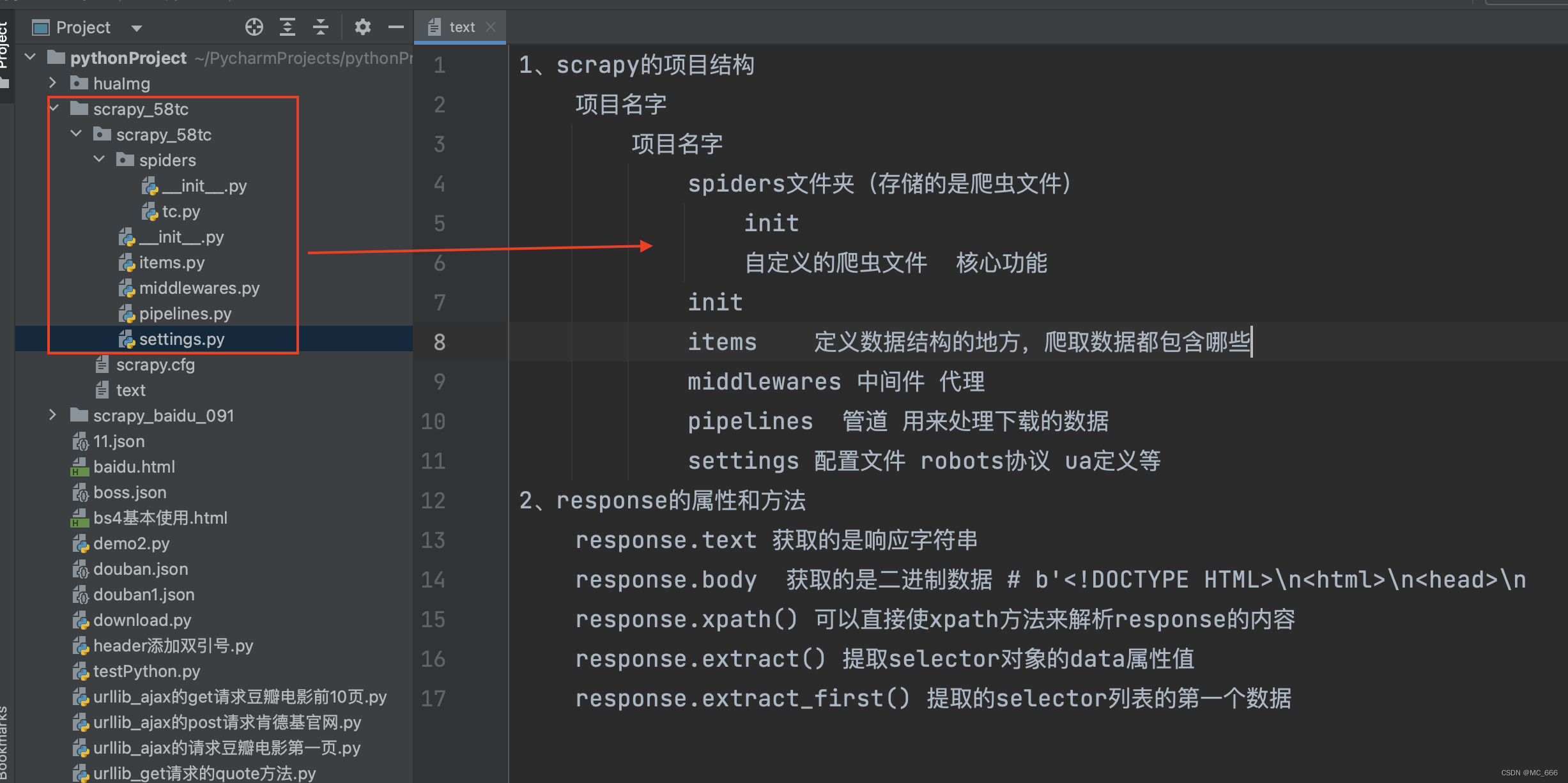
1、scrapy的项目结构
项目名字
项目名字
spiders文件夹(存储的是爬虫文件)
init
自定义的爬虫文件 核心功能
init
items 定义数据结构的地方,爬取数据都包含哪些
middlewares 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robots协议 ua定义等
2、response的属性和方法
response.text 获取的是响应字符串
response.body 获取的是二进制数据 # b'<!DOCTYPE HTML>\n<html>\n<head>\n
response.xpath() 可以直接使xpath方法来解析response的内容
response.extract() 提取selector对象的data属性值
response.extract_first() 提取的selector列表的第一个数据
3.实战代码
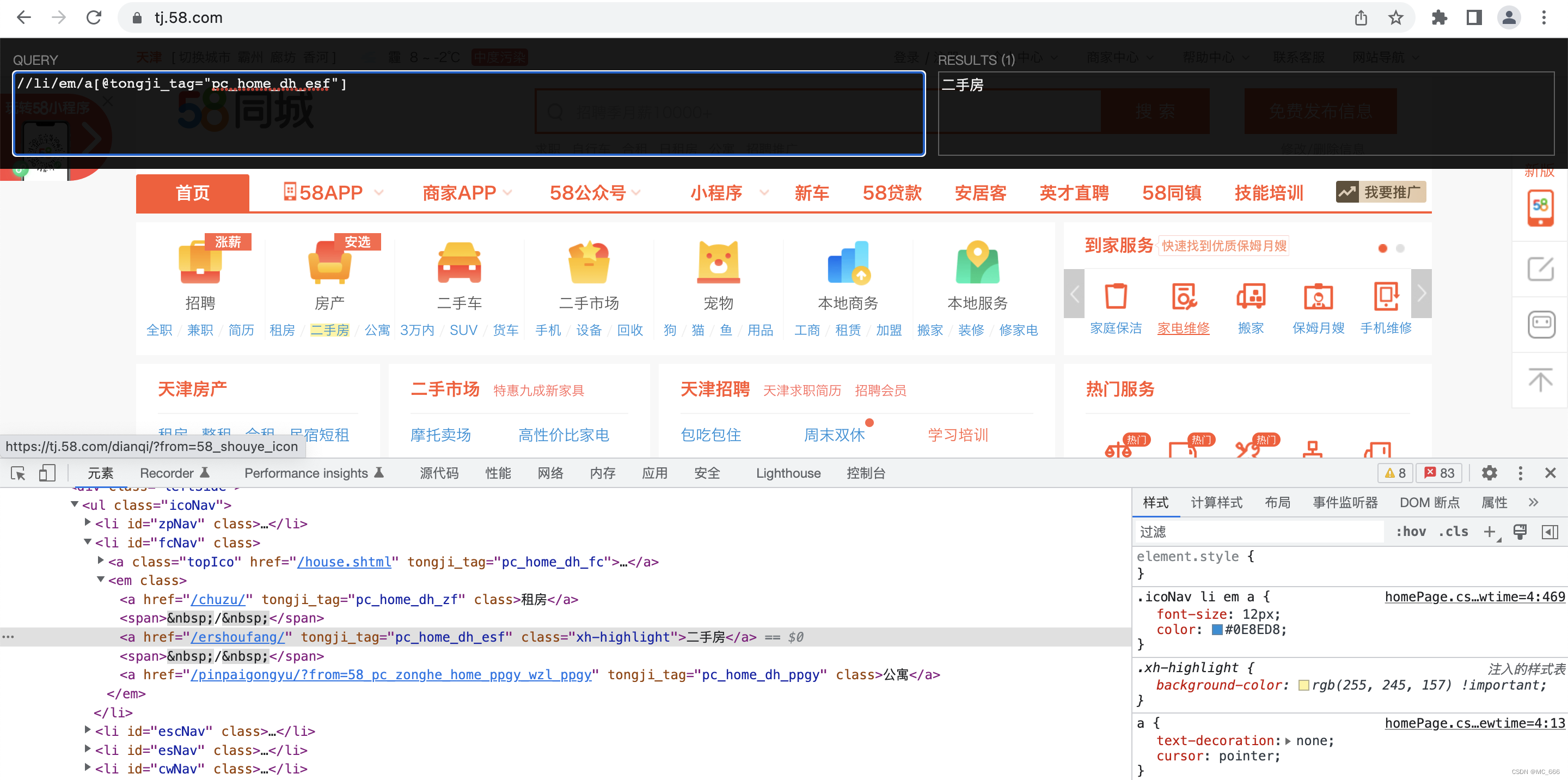
1)利用xpath插件确定数据
2)代码如下(示例):
import scrapy
class TcSpider(scrapy.Spider):
name = "tc"
allowed_domains = ["tj.58.com"]
start_urls = ["https://tj.58.com/"]
def parse(self, response):
content = response.xpath('//li/em/a[@tongji_tag="pc_home_dh_esf"]')
print("============================")
print(content.extract())
# content =response.text
# content = response.body
# b'<!DOCTYPE HTML>\n<html>\n<head>\n
# print("========================")
# print(content)
命令行运行
bogon:spiders yingyan$ scrapy crawl tc
结果


















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









