







目录
1.问题描述
一个数如果恰好等于它的因子之和,这个数就称为“完数”。例如6=1+2+3,再如8的因子和是7(即1+2+4),8不是完数。输入一个数n,编程找出n以内的所有完数及其个数。
2.算法设计
2.1 串行算法设计
串行算法步骤如下
①因为1不算入一个完数,所以令数i=2,初始化答案值ans=0;
②因为1是任何数的一个因数,所以可初始化因数之和sum=1;
③令数k=2;
④如果数i能整除数k,说明k是i的一个因数,则sum += k;
⑤若k<=i/2(控制范围保证i%k能进行计算),++k,转到④,否则转到⑥;
⑥若sum = i,++ans;
⑦若i <=n,++i,转到②,否则转到⑧;
⑧函数返回答案值ans。
2.2 并行算法设计
并行算法步骤如下
①因为1不算入一个完数,所以令数i=2,初始化答案值ans=0;
②“#pragmaomp parallel for”
②因为1是任何数的一个因数,所以可初始化因数之和sum=1;
“#pragmaomp parallel for”
③令数k=2;
“#pragmaomp critical”
④如果数i能整除数k,说明k是i的一个因数,则sum += k;
⑤若k<=i/2(控制范围保证i%k能进行计算),++k,转到④,否则转到⑥;
⑥若sum = i,++ans;
⑦若i <=n,++i,转到②,否则转到⑧;
⑧函数返回答案值ans。
2.3 理论加速比分析
若p个处理器上数据量为n,则S=np/(n+2plogp)。
本机测试中,p=4:若n=10000,则S=3.9981;若n=100000,则S=3.9998。
3.基于OpenMP的并行算法实现
3.1 代码及注释(变量名 名字首字母 开头)
/*问题描述:一个数如果恰好等于它的因子之和,这个数就称为“完数”。例如6=1+2+3,再如8的因子和是7(即1+2+4),8不是完数。编程找出1000以内的所有完数。
*/
//test.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <cstdlib>
#include <iostream>
#include <cmath>
#include <ctime>
#include <omp.h>
#include <windows.h>
using namespace std;
int OMP_Perfect(long long n) //并行计算n以内的完数个数
{
int ans = 0; // n以内的完数个数
long long i, k; //循环变量
#pragma omp parallel for
for (i = 2; i <= n;i++) //1不算入一个完数。
{
long long sum = 1; //数的因数之和,1是任何数的一个因数。
#pragma omp parallel for reduction(+:sum) //解决sum数据冲突
for (k = 2; k <= i / 2; k++) //k<=i/2是要保证i%k能进行计算。
if(i%k == 0)
sum += k; //因数之和
if (sum == i) //找到一个完数
++ans; //函数返回答案值ans
}
return ans;
}
int Perfect(long long n)
{
int ans = 0; // n以内的完数个数
long long i, k; //循环变量
for (i = 2; i <= n;i++) //1不算入一个完数。
{
long long sum = 1; //数的因数之和,1是任何数的一个因数。
for (k = 2; k <= i / 2; k++) //k<=i/2是要保证i%k能进行计算。
if(i%k == 0)
sum += k; //因数之和
if (sum == i) //找到一个完数
++ans; //函数返回答案值ans
}
return ans;
}
int main()
{
long long n;
cin >> n;
printf("%lld以内的完数有:\n",n);
clock_t t1, t2;
t1 = clock();
printf("Sum= %d\n", OMP_Perfect(n)); //输出并行计算出的n以内的完数个数
t2 = clock();
printf("parallel time: %d\n", t2 - t1);//输出并行计算时间
t1 = clock();
printf("Sum= %d\n", Perfect(n)); //输出串行计算出的n以内的完数个数
t2 = clock();
printf("serail time: %d\n", t2 - t1); //输出串行计算时间
system("pause");
return 0;
}3.2 执行结果截图
(1)小数据量验证正确性的执行结果截图(不考虑加速比)

(2)大数据量获得较好加速比的执行结果截图
(体现串行时间、并行时间 和好的加速比)
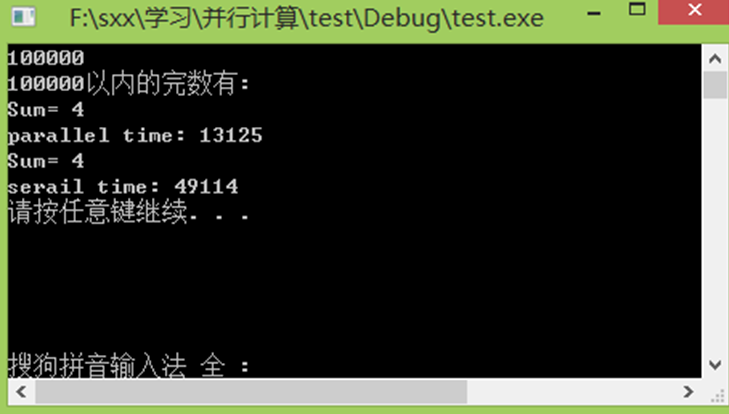
3.3 实验加速比分析
若n=10000,S=Ts/Tp=3.7857;若n=100000,S=Ts/Tp=3.7420。
实验加速比与理论加速比相差不大,在误差允许范围内可认为结果正确。
3.4 遇到的问题及解决方案
3.4.1错误代码
int OMP_Perfect(longlong n)
{
int ans = 0;
long long i, k;
#pragma omp parallel for
for (i = 2; i <= n;i++)
{
long long sum = 1;
#pragma omp parallel for
for (k = 2; k <= i / 2; k++)
if(i%k == 0)
sum += k;
if (sum == i) ++ans;
}
return ans;
}
3.4.2后果
n以内的完数数量答案错误。
3.4.3正确代码
int OMP_Perfect(longlong n) //并行计算n以内的完数个数
{
int ans = 0; // n以内的完数个数
long long i, k; //循环变量
#pragma omp parallel for
for (i = 2; i <= n;i++) //1不算入一个完数。
{
long long sum = 1; //数的因数之和,1是任何数的一个因数。
#pragma omp parallel for reduction(+:sum) //解决sum数据冲突
for (k = 2; k <= i / 2; k++) //k<=i/2是要保证i%k能进行计算。
if(i%k == 0)
sum += k; //因数之和
if (sum == i) //找到一个完数
++ans; //函数返回答案值ans
}
return ans;
}
3.4.4分析
由于是多线程执行,有超过两个线程同时访问一个内存区域,并且至少有一个线程的操作是写操作,这样就产生了数据竞争。如果不对数据竞争进行处理,结果会产生错误。
第二个for语句并行使用“#pragma ompparallel for reduction(+:sum)”来解决sum的数据竞争问题。因为reduction子句为变量指定一个操作符,每个线程都会创建reduction变量的私有副本,在OpenMP区域结束处,将使用各个线程私有复制的值通过制定的操作符进行迭代运算,并赋值给原来的变量。















 4448
4448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









