






Question
有哪些不同的GPU训练方式?这些方式有什么不同?
训练模式
多GPU训练模式可以分为两类:一类是将数据分割后再多个GPU上并行处理,另一类是当模型大小超过单个GPU的显存时,将模型分割到多个GPU上处理。数据并行属于第一类,而模型并行和张量并行属于第二类。流水线并行则融合了这两种模式的思想。此外,目前一些产品如DeepSpeed、Colossal-AI这些产品页将多种思想结合,形成了新的混合方案。
接下来将讨论模型并行、数据并行、张量并行和序列并行等多GPU训练模式。
模型并行
模型并行也称为操作间并行,是一种将大规模的不同部分放到不同的GPU设备上按序计算的技术,计算的过程中数据会在不同设备间传递。这项技术让不适合单设备的模型能够得到训练和部署,但同时也需要更复杂的调度能力来管理弄醒在不同模块间的依赖关系。
模型并行的直观示例:例如对于仅有一个隐藏层和一个输出层的简单神经网络,可以将两层分别放在不同的GPU上。这种做法也可以扩展至任意数量的层和GPU。
模型并行是应对GPU显存限制的优秀策略,尤其是在完整网络无法适配单GPU的情况下。但要利用多GPU,还有更高效的方式,比如张量并行,因为模型并行中的链式结构(第1层在GPU1上->第2层在GPU2上->…)会产生性能瓶颈。换句话说,模型并行的主要缺陷是GPU之间必须相互等待,从而不能高效地并行工作,因为它们依赖彼此的输出。
数据并行
近几年来,多GPU模型训练默认采用的是数据并行。在该模式下,会将小批量数据(mini-batch)划分成更小的微批量数据(micro-batch),然后让每个GPU分别处理一个微批量数据,并计算模型权重的损失和梯度。在所有单设备上完成这些微批量数据后,梯度会被汇总,用于计算下一轮的梯度更新。
数据并行相较于模型并行的优势在于GPU能够并行运行。每个GPU训练小批量数据中的一部分,即一个微批量。但需要注意的是,每个GPU都需要模型的一份完整副本。如果模型大道放不到GPU的显存中,数据并行就不可用了。
张量并行
张量并行,也成为操作内并行,是一种更高效的模型并行形式。在张量并行中,我们将权重和激活矩阵拆分到各个设备上,而非将不同的模型层分散到各个设备上。矩阵拆分使得我们能够将矩阵乘法分布到多个GPU上执行。
可以运用线性代数的基本原来来实现张量并行。如下图所示,在两个GPU上按行或按列分割矩阵乘法进行计算。
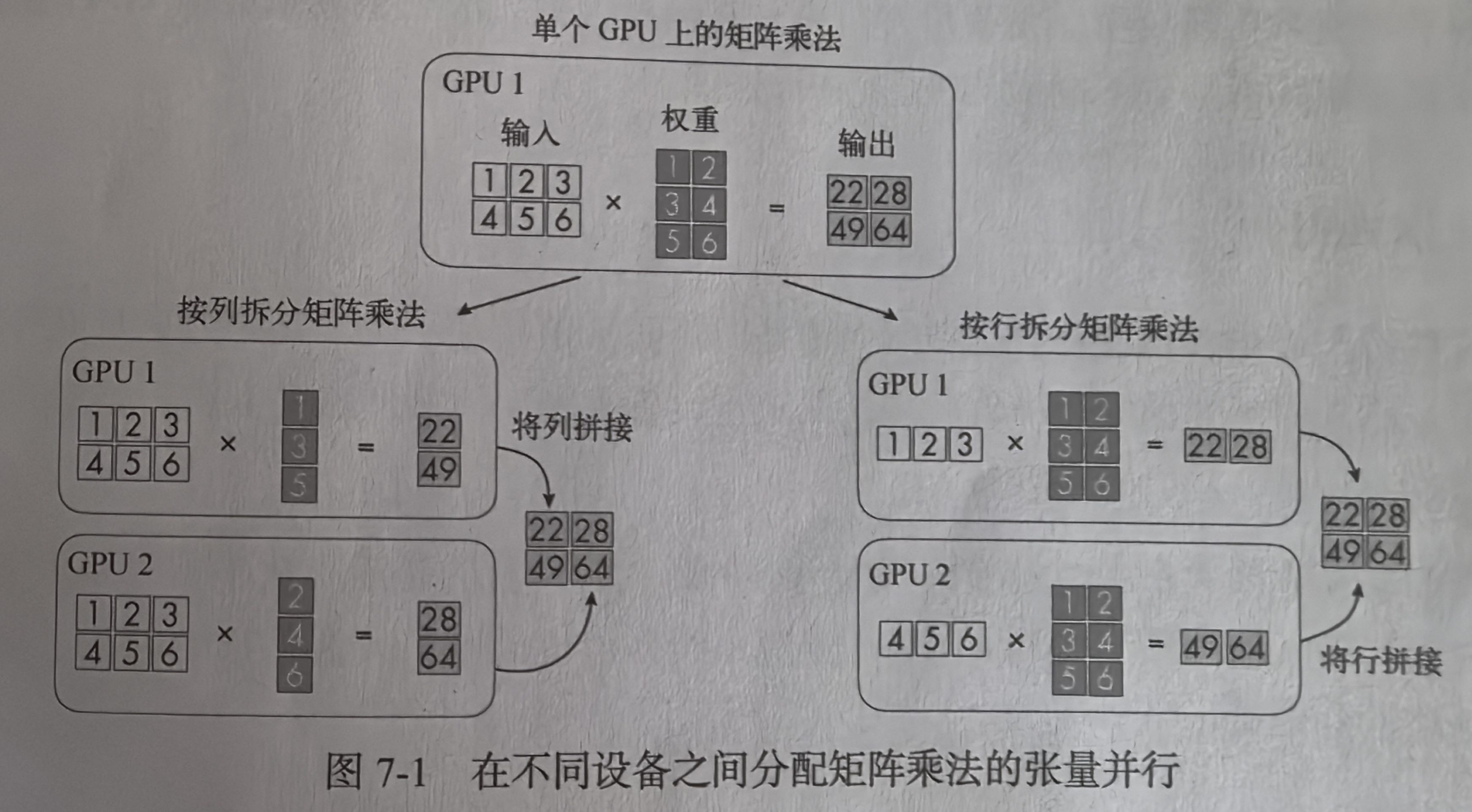
与模型并行类似,张量并行能够绕绕过内存限制。同时,也能像数据并行那样并行执行操作。
张量并行的一个缺点是,可能导致多个GPU之间进行矩阵分割的通信开销变高。例如,张量并行需要再设备间频繁同步模型参数,这可能会拖慢整体训练速度。
在模型并行策略下,将不同的层分布到不同的GPU上,以解决单GPU显存限制的问题。在数据并行中,将批量数据拆分到多个GPU上,以解决无法并行训练的问题,数据并行会计算梯度的平均值来更新权重。张量并行是在模型大到无法装载进单GPU显存时,输入矩阵和权重矩阵拆分到不同GPU上并行处理。

流水线并行
流水线并行(Pipeline Parallelism)在模型并行基础上,进一步引入数据并行的方法。可以看做是数据并行和模型并行的一种高阶混合版。可以将流水线并行视为模型并行的另一种形式,其目的是最小化穿行计算的性能瓶颈。增强部署在不同设备上的模型层的并行性。但流水线并行也借鉴了数据并行的思想,例如将小批量数据进一步拆分为微批量数据。
核心原理
-
模型划分:
将神经网络模型按层或模块切分成多个子块,每个设备负责计算其中一个子块。例如,一个10层的模型分配到4个设备上,可能分配为:设备1(1-3层)、设备2(4-5层)、设备3(6-8层)、设备4(9-10层)。 -
流水线执行:
数据(如一个批次的样本)被分成更小的微批次(micro-batches),依次进入流水线。当一个设备处理完当前微批次后,会立即将结果传递给下一个设备,同时开始处理下一个微批次,从而实现设备间的并行计算。 -
消除空闲时间:
通过重叠不同设备上的计算和通信,减少设备等待时间。例如,设备1处理第2个微批次时,设备2可以同时处理第1个微批次的结果。
尽管流水线并行的方案还未至臻完美,设备仍有空闲时间,但已经是对模型并行的升级。流水线并行的一个缺点是,可以需要投入大量精力来设计和实施流水线编排及通信。
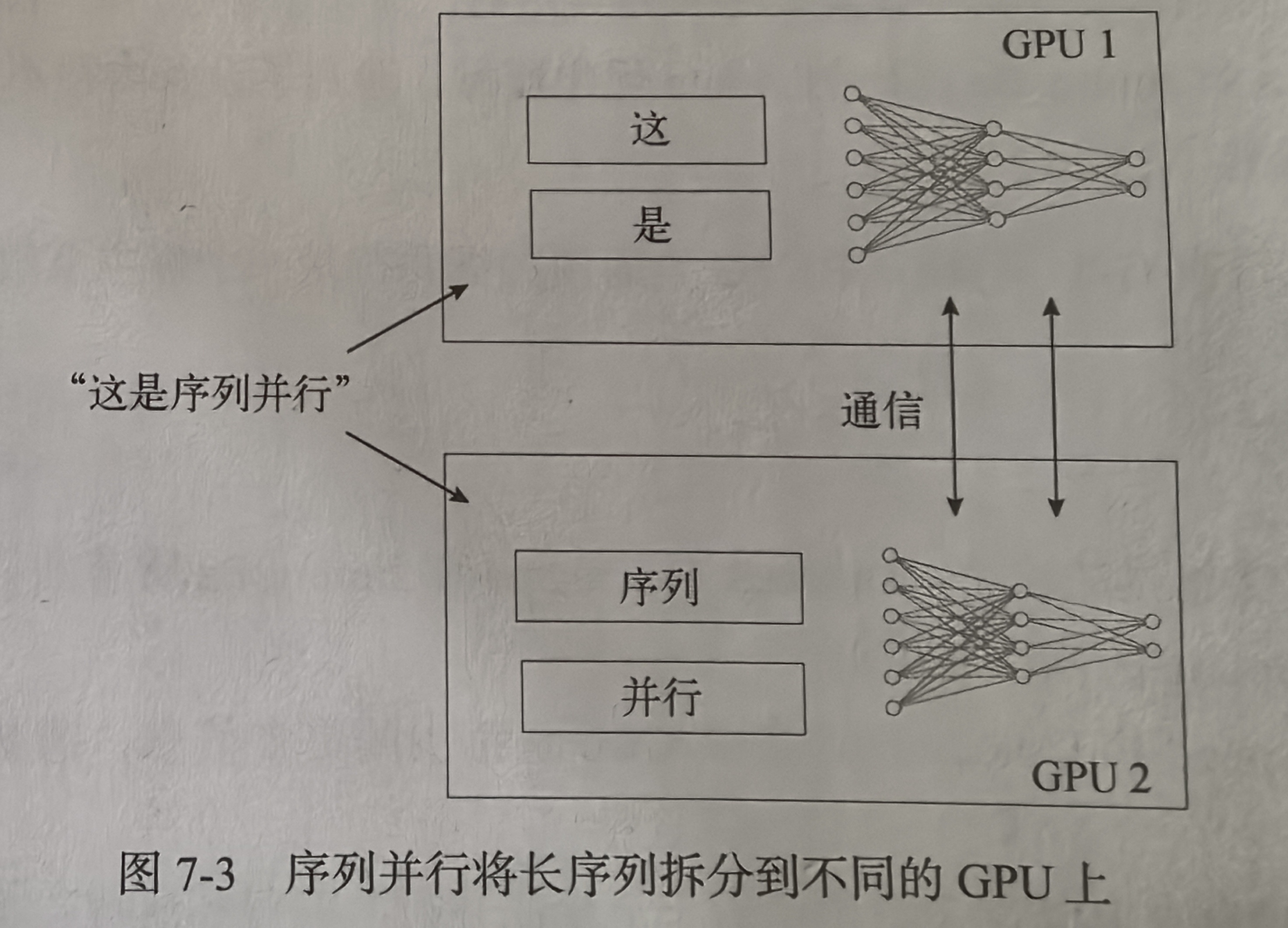
序列并行
序列并行旨在解决Transformer架构大模型处理长序列任务时会碰到的计算瓶颈问题。Transformer的缺点在于自注意力机制与输入序列的规模是二次方计算复杂度关系。序列并行方案将输入序列分割成更小的块,拆分到不同的GPU上,从而减少自注意力机制对计算内存的需求。
与以上方法不同的是,序列并行专门处理有序数据,张量并行更多地针对模型的内部结构,而数据并行则针对训练数据的划分。由于这些并行策略各自针对的是计算难题的不同方面,因此理论上他们可以以不同方式结合使用,实现训练和推理过程的优化。
虽然序列并行在实践中看起来很管用,但他们也像前面提到的并行技术一样引入了额外的通信开销。与数据并行类似,序列并行也需要复制模型,并确保模型能够装载到单设备内存中。序列并行的另一个缺点是(取决于实现方式),在使用多GPU模式训练Transformer时,将输入序列分解成更小的子序列可能会降低模型的准确率。
参考文献
[1] 塞巴斯蒂安·拉施卡, 大模型技术30讲, 人民邮电出版社(北京), 2025, P30-35.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









