







大神总结的目录:http://www.cnblogs.com/skywang12345/p/3323085.html(转载),仅供个人学习,如有抄袭请包容(我也忘了cry....)
一、 map架构
1) 概要
前面,我们已经系统的对List进行了学习。接下来,我们先学习Map,然后再学习Set;因为Set的实现类都是基于Map来实现的(如,HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的)。
首先,我们看看Map架构。

如上图:
(01) Map 是映射接口,Map中存储的内容是键值对(key-value)。
(02) AbstractMap 是继承于Map的抽象类,它实现了Map中的大部分API。其它Map的实现类可以通过继承AbstractMap来减少重复编码。
(03) SortedMap 是继承于Map的接口。SortedMap中的内容是排序的键值对,排序的方法是通过比较器(Comparator)。
(04) NavigableMap 是继承于SortedMap的接口。相比于SortedMap,NavigableMap有一系列的导航方法;如"获取大于/等于某对象的键值对"、“获取小于/等于某对象的键值对”等等。
(05) TreeMap 继承于AbstractMap,且实现了NavigableMap接口;因此,TreeMap中的内容是“有序的键值对”!
(06) HashMap 继承于AbstractMap,但没实现NavigableMap接口;因此,HashMap的内容是“键值对,但不保证次序”!
(07) Hashtable 虽然不是继承于AbstractMap,但它继承于Dictionary(Dictionary也是键值对的接口),而且也实现Map接口;因此,Hashtable的内容也是“键值对,也不保证次序”。但和HashMap相比,Hashtable是线程安全的,而且它支持通过Enumeration去遍历。
(08) WeakHashMap 继承于AbstractMap。它和HashMap的键类型不同,WeakHashMap的键是“弱键”。
在对各个实现类进行详细之前,先来看看各个接口和抽象类的大致介绍。内容包括:
1 Map
2 Map.Entry
3 AbstractMap
4 SortedMap
5 NavigableMap
6 Dictionary
2) Map
Map的定义如下:
public interfaceMap<K,V> { }
Map 是一个键值对(key-value)映射接口。Map映射中不能包含重复的键;每个键最多只能映射到一个值。
Map 接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容。
Map 映射顺序。有些实现类,可以明确保证其顺序,如 TreeMap;另一些映射实现则不保证顺序,如 HashMap 类。
Map 的实现类应该提供2个“标准的”构造方法:第一个,void(无参数)构造方法,用于创建空映射;第二个,带有单个 Map 类型参数的构造方法,用于创建一个与其参数具有相同键-值映射关系的新映射。实际上,后一个构造方法允许用户复制任意映射,生成所需类的一个等价映射。尽管无法强制执行此建议(因为接口不能包含构造方法),但是 JDK 中所有通用的映射实现都遵从它。
Map的API
abstract void clear()
abstractboolean containsKey(Objectkey)
abstract boolean containsValue(Object value)
abstractSet<Entry<K, V>> entrySet()
abstractboolean equals(Objectobject)
abstract V get(Object key)
abstract int hashCode()
abstractboolean isEmpty()
abstractSet<K> keySet()
abstract V put(K key, V value)
abstract void putAll(Map<? extends K, ?extends V> map)
abstract V remove(Object key)
abstract int size()
abstractCollection<V> values()
说明:
(01) Map提供接口分别用于返回 键集、值集或键-值映射关系集。
entrySet()用于返回键-值集的Set集合
keySet()用于返回键集的Set集合
values()用户返回值集的Collection集合
因为Map中不能包含重复的键;每个键最多只能映射到一个值。所以,键-值集、键集都是Set,值集时Collection。
(02) Map提供了“键-值对”、“根据键获取值”、“删除键”、“获取容量大小”等方法。
3) Map.Entry
Map.Entry的定义如下:
interfaceEntry<K,V> { }
Map.Entry是Map中内部的一个接口,Map.Entry是键值对,Map通过 entrySet() 获取Map.Entry的键值对集合,从而通过该集合实现对键值对的操作。
Map.Entry的API
abstractboolean equals(Object object)
abstract K getKey()
abstract V getValue()
abstract int hashCode()
abstract V setValue(V object)
4) AbstractMap
AbstractMap的定义如下:
public abstractclass AbstractMap<K,V> implements Map<K,V> {}
AbstractMap类提供 Map 接口的骨干实现,以最大限度地减少实现此接口所需的工作。
要实现不可修改的映射,编程人员只需扩展此类并提供 entrySet 方法的实现即可,该方法将返回映射的映射关系 set 视图。通常,返回的 set 将依次在 AbstractSet 上实现。此 set 不支持 add() 或remove() 方法,其迭代器也不支持 remove() 方法。
要实现可修改的映射,编程人员必须另外重写此类的put 方法(否则将抛出 UnsupportedOperationException),entrySet().iterator() 返回的迭代器也必须另外实现其 remove 方法。
AbstractMap的API
abstractSet<Entry<K, V>> entrySet()
void clear()
boolean containsKey(Object key)
boolean containsValue(Object value)
boolean equals(Object object)
V get(Object key)
int hashCode()
boolean isEmpty()
Set<K> keySet()
V put(K key, V value)
void putAll(Map<? extends K, ?extends V> map)
V remove(Object key)
int size()
String toString()
Collection<V> values()
Object clone()
5) SortedMap
SortedMap的定义如下:
public interfaceSortedMap<K,V> extends Map<K,V> { }
SortedMap是一个继承于Map接口的接口。它是一个有序的SortedMap键值映射。
SortedMap的排序方式有两种:自然排序 或者 用户指定比较器。 插入有序 SortedMap 的所有元素都必须实现 Comparable 接口(或者被指定的比较器所接受)。
另外,所有SortedMap 实现类都应该提供 4 个“标准”构造方法:
(01) void(无参数)构造方法,它创建一个空的有序映射,按照键的自然顺序进行排序。
(02) 带有一个 Comparator 类型参数的构造方法,它创建一个空的有序映射,根据指定的比较器进行排序。
(03) 带有一个 Map 类型参数的构造方法,它创建一个新的有序映射,其键-值映射关系与参数相同,按照键的自然顺序进行排序。
(04) 带有一个 SortedMap 类型参数的构造方法,它创建一个新的有序映射,其键-值映射关系和排序方法与输入的有序映射相同。无法保证强制实施此建议,因为接口不能包含构造方法。
SortedMap的API
// 继承于Map的API
abstract void clear()
abstractboolean containsKey(Objectkey)
abstractboolean containsValue(Objectvalue)
abstractSet<Entry<K, V>> entrySet()
abstractboolean equals(Objectobject)
abstract V get(Object key)
abstract int hashCode()
abstractboolean isEmpty()
abstractSet<K> keySet()
abstract V put(K key, V value)
abstract void putAll(Map<? extends K, ?extends V> map)
abstract V remove(Object key)
abstract int size()
abstractCollection<V> values()
// SortedMap新增的API
abstractComparator<? super K> comparator()
abstract K firstKey()
abstractSortedMap<K, V> headMap(KendKey)
abstract K lastKey()
abstractSortedMap<K, V> subMap(K startKey,K endKey)
abstractSortedMap<K, V> tailMap(KstartKey)
6) NavigableMap
NavigableMap的定义如下:
public interfaceNavigableMap<K,V> extends SortedMap<K,V> { }
NavigableMap是继承于SortedMap的接口。它是一个可导航的键-值对集合,具有了为给定搜索目标报告最接近匹配项的导航方法。
NavigableMap分别提供了获取“键”、“键-值对”、“键集”、“键-值对集”的相关方法。
NavigableMap的API
abstractEntry<K, V> ceilingEntry(K key)
abstractEntry<K, V> firstEntry()
abstractEntry<K, V> floorEntry(K key)
abstractEntry<K, V> higherEntry(K key)
abstractEntry<K, V> lastEntry()
abstractEntry<K, V> lowerEntry(K key)
abstractEntry<K, V> pollFirstEntry()
abstractEntry<K, V> pollLastEntry()
abstract K ceilingKey(K key)
abstract K floorKey(K key)
abstract K higherKey(K key)
abstract K lowerKey(K key)
abstractNavigableSet<K> descendingKeySet()
abstractNavigableSet<K> navigableKeySet()
abstractNavigableMap<K, V> descendingMap()
abstractNavigableMap<K, V> headMap(KtoKey, boolean inclusive)
abstractSortedMap<K, V> headMap(KtoKey)
abstractSortedMap<K, V> subMap(KfromKey, K toKey)
abstractNavigableMap<K, V> subMap(KfromKey, boolean fromInclusive, K toKey, boolean toInclusive)
abstractSortedMap<K, V> tailMap(KfromKey)
abstractNavigableMap<K, V> tailMap(KfromKey, boolean inclusive)
说明:
NavigableMap除了继承SortedMap的特性外,它的提供的功能可以分为4类:
第1类,提供操作键-值对的方法。
lowerEntry、floorEntry、ceilingEntry 和 higherEntry 方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键关联的 Map.Entry 对象。
firstEntry、pollFirstEntry、lastEntry和 pollLastEntry 方法,它们返回和/或移除最小和最大的映射关系(如果存在),否则返回 null。
第2类,提供操作键的方法。这个和第1类比较类似
lowerKey、floorKey、ceilingKey 和 higherKey 方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键。
第3类,获取键集。
navigableKeySet、descendingKeySet分别获取正序/反序的键集。
第4类,获取键-值对的子集。
7) Dictionary
Dictionary的定义如下:
public abstractclass Dictionary<K,V> {}
NavigableMap是JDK 1.0定义的键值对的接口,它也包括了操作键值对的基本函数。
Dictionary的API
abstractEnumeration<V> elements()
abstract V get(Object key)
abstractboolean isEmpty()
abstractEnumeration<K> keys()
abstract V put(K key, V value)
abstract V remove(Object key)
abstract int size()
二、 HashMap类
1) 概要
这一章,我们对HashMap进行学习。
我们先对HashMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashMap。内容包括:
第1部分 HashMap介绍
第2部分 HashMap数据结构
第3部分 HashMap源码解析(基于JDK1.6.0_45)
第3.1部分 HashMap的“拉链法”相关内容
第3.2部分 HashMap的构造函数
第3.3部分 HashMap的主要对外接口
第3.4部分 HashMap实现的Cloneable接口
第3.5部分 HashMap实现的Serializable接口
第4部分 HashMap遍历方式
第5部分 HashMap示例
2) HashMap介绍
HashMap简介
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生rehash 操作。
HashMap的构造函数
HashMap共有4个构造函数,如下:
// 默认构造函数。
HashMap()
// 指定“容量大小”的构造函数
HashMap(intcapacity)
// 指定“容量大小”和“加载因子”的构造函数
HashMap(intcapacity, float loadFactor)
// 包含“子Map”的构造函数
HashMap(Map<?extends K, ? extends V> map)
HashMap的API
void clear()
Object clone()
boolean containsKey(Object key)
boolean containsValue(Object value)
Set<Entry<K,V>> entrySet()
V get(Object key)
boolean isEmpty()
Set<K> keySet()
V put(K key, V value)
void putAll(Map<? extends K, ?extends V> map)
V remove(Object key)
int size()
Collection<V> values()
3) HashMap数据结构
HashMap的继承关系
java.lang.Object
java.util.AbstractMap<K, V>
java.util.HashMap<K, V>
public classHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable,Serializable { }
HashMap与Map关系如下:
从中可以看出:
(01) HashMap继承于AbstractMap类,实现了Map接口。Map是"key-value键值对"接口,AbstractMap实现了"键值对"的通用函数接口。
(02) HashMap是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的。
4) HashMap源码解析
为了更了解HashMap的原理,下面对HashMap源码代码作出分析。
在阅读源码时,建议参考后面的说明来建立对HashMap的整体认识,这样更容易理解HashMap。
说明:
在详细介绍HashMap的代码之前,我们需要了解:HashMap就是一个散列表,它是通过“拉链法”解决哈希冲突的。
还需要再补充说明的一点是影响HashMap性能的有两个参数:初始容量(initialCapacity) 和加载因子(loadFactor)。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
第3.1部分 HashMap的“拉链法”相关内容
3.1.1 HashMap数据存储数组
transient Entry[]table;
HashMap中的key-value都是存储在Entry数组中的。
3.1.2 数据节点Entry的数据结构
从中,我们可以看出 Entry 实际上就是一个单向链表。这也是为什么我们说HashMap是通过拉链法解决哈希冲突的。
Entry 实现了Map.Entry 接口,即实现getKey(),getValue(), setValue(V value), equals(Object o), hashCode()这些函数。这些都是基本的读取/修改key、value值的函数。
第3.2部分 HashMap的构造函数
HashMap共包括4个构造函数
第3.3部分 HashMap的主要对外接口
3.3.1 clear()
clear() 的作用是清空HashMap。它是通过将所有的元素设为null来实现的。
3.3.2containsKey()
containsKey() 的作用是判断HashMap是否包含key。
public booleancontainsKey(Object key) {
return getEntry(key) != null;
}
containsKey() 首先通过getEntry(key)获取key对应的Entry,然后判断该Entry是否为null。
getEntry() 的作用就是返回“键为key”的键值对,它的实现源码中已经进行了说明。
这里需要强调的是:HashMap将“key为null”的元素都放在table的位置0处,即table[0]中;“key不为null”的放在table的其余位置!
3.3.3containsValue()
containsValue() 的作用是判断HashMap是否包含“值为value”的元素。
从中,我们可以看出containsNullValue()分为两步进行处理:第一,若“value为null”,则调用containsNullValue()。第二,若“value不为null”,则查找HashMap中是否有值为value的节点。
containsNullValue()的作用判断HashMap中是否包含“值为null”的元素。
3.3.4 entrySet()、values()、keySet()
它们3个的原理类似,这里以entrySet()为例来说明。
entrySet()的作用是返回“HashMap中所有Entry的集合”,它是一个集合。实现代码如下:
HashMap是通过拉链法实现的散列表。表现在HashMap包括许多的Entry,而每一个Entry本质上又是一个单向链表。那么HashMap遍历key-value键值对的时候,是如何逐个去遍历的呢?
下面我们就看看HashMap是如何通过entrySet()遍历的。
entrySet()实际上是通过newEntryIterator()实现的。 下面我们看看它的代码:
当我们通过entrySet()获取到的Iterator的next()方法去遍历HashMap时,实际上调用的是 nextEntry() 。而nextEntry()的实现方式,先遍历Entry(根据Entry在table中的序号,从小到大的遍历);然后对每个Entry(即每个单向链表),逐个遍历。
3.3.5 get()
get() 的作用是获取key对应的value
3.3.6 put()
put() 的作用是对外提供接口,让HashMap对象可以通过put()将“key-value”添加到HashMap中。
若要添加到HashMap中的键值对对应的key已经存在HashMap中,则找到该键值对;然后新的value取代旧的value,并退出!
若要添加到HashMap中的键值对对应的key不在HashMap中,则将其添加到该哈希值对应的链表中,并调用addEntry()。
addEntry() 的作用是新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
说到addEntry(),就不得不说另一个函数createEntry()。
它们的作用都是将key、value添加到HashMap中。而且,比较addEntry()和createEntry()的代码,我们发现addEntry()多了两句:
if (size++ >=threshold)
resize(2 * table.length);
那它们的区别到底是什么呢?
阅读代码,我们可以发现,它们的使用情景不同。
(01) addEntry()一般用在 新增Entry可能导致“HashMap的实际容量”超过“阈值”的情况下。
例如,我们新建一个HashMap,然后不断通过put()向HashMap中添加元素;put()是通过addEntry()新增Entry的。
在这种情况下,我们不知道何时“HashMap的实际容量”会超过“阈值”;
因此,需要调用addEntry()
(02) createEntry()一般用在 新增Entry不会导致“HashMap的实际容量”超过“阈值”的情况下。
例如,我们调用HashMap“带有Map”的构造函数,它绘将Map的全部元素添加到HashMap中;
但在添加之前,我们已经计算好“HashMap的容量和阈值”。也就是,可以确定“即使将Map中的全部元素添加到HashMap中,都不会超过HashMap的阈值”。
此时,调用createEntry()即可。
3.3.7 putAll()
putAll() 的作用是将"m"的全部元素都添加到HashMap中
3.3.8 remove()
remove() 的作用是删除“键为key”元素
第3.4部分 HashMap实现的Cloneable接口
HashMap实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个HashMap对象并返回。
第3.5部分 HashMap实现的Serializable接口
HashMap实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数是writeObject(),它的作用是将HashMap的“总的容量,实际容量,所有的Entry”都写入到输出流中。
而串行读取函数是readObject(),它的作用是将HashMap的“总的容量,实际容量,所有的Entry”依次读出
5) HashMap遍历方式
4.1 遍历HashMap的键值对
第一步:根据entrySet()获取HashMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
Integer integ =null;
Iterator iter =map.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}
4.2 遍历HashMap的键
第一步:根据keySet()获取HashMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ =null;
Iterator iter =map.keySet().iterator();
while(iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)map.get(key);
}
4.3 遍历HashMap的值
第一步:根据value()获取HashMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
Integer value =null;
Collection c =map.values();
Iterator iter=c.iterator();
while(iter.hasNext()) {
value = (Integer)iter.next();
}
6) HashMap示例
importjava.util.Map;
importjava.util.Random;
importjava.util.Iterator;
importjava.util.HashMap;
importjava.util.HashSet;
importjava.util.Map.Entry;
importjava.util.Collection;
/*
* @desc HashMap测试程序
*
* @author skywang
*/
public classHashMapTest {
public static void main(String[] args) {
testHashMapAPIs();
}
private static void testHashMapAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建HashMap
HashMap map = new HashMap();
// 添加操作
map.put("one",r.nextInt(10));
map.put("two",r.nextInt(10));
map.put("three",r.nextInt(10));
// 打印出map
System.out.println("map:"+map);
// 通过Iterator遍历key-value
Iterator iter =map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry =(Map.Entry)iter.next();
System.out.println("next :"+ entry.getKey() +" - "+entry.getValue());
}
// HashMap的键值对个数
System.out.println("size:"+map.size());
// containsKey(Object key) :是否包含键key
System.out.println("contains keytwo : "+map.containsKey("two"));
System.out.println("contains keyfive : "+map.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.println("contains value0 : "+map.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
map.remove("three");
System.out.println("map:"+map);
// clear() : 清空HashMap
map.clear();
// isEmpty() : HashMap是否为空
System.out.println((map.isEmpty()?"map is empty":"map isnot empty") );
}
}
三、 Hashtable类
1) 概要
前一章,我们学习了HashMap。这一章,我们对Hashtable进行学习。
我们先对Hashtable有个整体认识,然后再学习它的源码,最后再通过实例来学会使用Hashtable。
第1部分 Hashtable介绍
第2部分 Hashtable数据结构
第3部分 Hashtable源码解析(基于JDK1.6.0_45)
第4部分 Hashtable遍历方式
第5部分 Hashtable示例
2) Hashtable介绍
Hashtable 简介
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
Hashtable的构造函数
// 默认构造函数。
public Hashtable()
// 指定“容量大小”的构造函数
publicHashtable(int initialCapacity)
// 指定“容量大小”和“加载因子”的构造函数
publicHashtable(int initialCapacity, float loadFactor)
// 包含“子Map”的构造函数
publicHashtable(Map<? extends K, ? extends V> t)
Hashtable的API
synchronizedvoid clear()
synchronized Object clone()
boolean contains(Object value)
synchronizedboolean containsKey(Objectkey)
synchronizedboolean containsValue(Objectvalue)
synchronizedEnumeration<V> elements()
synchronizedSet<Entry<K, V>> entrySet()
synchronizedboolean equals(Object object)
synchronizedV get(Object key)
synchronizedint hashCode()
synchronizedboolean isEmpty()
synchronizedSet<K> keySet()
synchronizedEnumeration<K> keys()
synchronizedV put(K key, V value)
synchronizedvoid putAll(Map<?extends K, ? extends V> map)
synchronizedV remove(Object key)
synchronizedint size()
synchronizedString toString()
synchronizedCollection<V> values()
3) Hashtable数据结构
Hashtable的继承关系
java.lang.Object
java.util.Dictionary<K, V>
java.util.Hashtable<K, V>
public classHashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable,java.io.Serializable { }
从图中可以看出:
(01) Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽象类。
(02) Hashtable是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
count是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
4) Hashtable源码解析
为了更了解Hashtable的原理,下面对Hashtable源码代码作出分析。
在阅读源码时,建议参考后面的说明来建立对Hashtable的整体认识,这样更容易理解Hashtable。
说明: 在详细介绍Hashtable的代码之前,我们需要了解:和Hashmap一样,Hashtable也是一个散列表,它也是通过“拉链法”解决哈希冲突的。
第3.1部分 Hashtable的“拉链法”相关内容
3.1.1 Hashtable数据存储数组
private transientEntry[] table;
Hashtable中的key-value都是存储在table数组中的。
3.1.2 数据节点Entry的数据结构
从中,我们可以看出 Entry 实际上就是一个单向链表。这也是为什么我们说Hashtable是通过拉链法解决哈希冲突的。
Entry 实现了Map.Entry 接口,即实现getKey(),getValue(), setValue(V value), equals(Object o), hashCode()这些函数。这些都是基本的读取/修改key、value值的函数。
第3.2部分 Hashtable的构造函数
Hashtable共包括4个构造函数
第3.3部分 Hashtable的主要对外接口
3.3.1 clear()
clear() 的作用是清空Hashtable。它是将Hashtable的table数组的值全部设为null
3.3.2 contains() 和 containsValue()
contains() 和 containsValue() 的作用都是判断Hashtable是否包含“值(value)”
3.3.3containsKey()
containsKey() 的作用是判断Hashtable是否包含key
3.3.4 elements()
elements() 的作用是返回“所有value”的枚举对象
从中,我们可以看出:
(01) 若Hashtable的实际大小为0,则返回“空枚举类”对象emptyEnumerator;
(02) 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
我们先看看emptyEnumerator对象是如何实现的
我们在来看看Enumeration类
Enumerator的作用是提供了“通过elements()遍历Hashtable的接口”和 “通过entrySet()遍历Hashtable的接口”。因为,它同时实现了“Enumerator接口”和“Iterator接口”。
entrySet(),keySet(), keys(), values()的实现方法和elements()差不多,而且源码中已经明确的给出了注释。这里就不再做过多说明了。
3.3.5 get()
get() 的作用就是获取key对应的value,没有的话返回null
3.3.6 put()
put() 的作用是对外提供接口,让Hashtable对象可以通过put()将“key-value”添加到Hashtable中。
3.3.7 putAll()
putAll() 的作用是将“Map(t)”的中全部元素逐一添加到Hashtable中
3.3.8 remove()
remove() 的作用就是删除Hashtable中键为key的元素
第3.4部分 Hashtable实现的Cloneable接口
Hashtable实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个Hashtable对象并返回。
第3.5部分 Hashtable实现的Serializable接口
Hashtable实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数就是将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中
串行读取函数:根据写入方式读出将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
5) Hashtable遍历方式
4.1 遍历Hashtable的键值对
第一步:根据entrySet()获取Hashtable的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
Integer integ =null;
Iterator iter =table.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}
4.2 通过Iterator遍历Hashtable的键
第一步:根据keySet()获取Hashtable的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
String key = null;
Integer integ =null;
Iterator iter =table.keySet().iterator();
while(iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)table.get(key);
}
4.3 通过Iterator遍历Hashtable的值
第一步:根据value()获取Hashtable的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设table是Hashtable对象
// table中的key是String类型,value是Integer类型
Integer value =null;
Collection c =table.values();
Iterator iter=c.iterator();
while(iter.hasNext()) {
value = (Integer)iter.next();
}
4.4 通过Enumeration遍历Hashtable的键
第一步:根据keys()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
Enumeration enu =table.keys();
while(enu.hasMoreElements()){
System.out.println(enu.nextElement());
}
4.5 通过Enumeration遍历Hashtable的值
第一步:根据elements()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
Enumeration enu =table.elements();
while(enu.hasMoreElements()){
System.out.println(enu.nextElement());
}
6) Hashtable示例
importjava.util.*;
/*
* @desc Hashtable的测试程序。
*
* @author skywang
*/
public classHashtableTest {
public static void main(String[] args) {
testHashtableAPIs();
}
private static void testHashtableAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建Hashtable
Hashtable table = new Hashtable();
// 添加操作
table.put("one",r.nextInt(10));
table.put("two",r.nextInt(10));
table.put("three",r.nextInt(10));
// 打印出table
System.out.println("table:"+table);
// 通过Iterator遍历key-value
Iterator iter =table.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry =(Map.Entry)iter.next();
System.out.println("next :"+ entry.getKey() +" - "+entry.getValue());
}
// Hashtable的键值对个数
System.out.println("size:"+table.size());
// containsKey(Object key) :是否包含键key
System.out.println("contains keytwo : "+table.containsKey("two"));
System.out.println("contains keyfive : "+table.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.println("contains value0 : "+table.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
table.remove("three");
System.out.println("table:"+table );
// clear() : 清空Hashtable
table.clear();
// isEmpty() : Hashtable是否为空
System.out.println((table.isEmpty()?"table isempty":"table is not empty") );
}}
四、 TreeMap类
1) 概要
这一章,我们对TreeMap进行学习。
我们先对TreeMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用TreeMap。内容包括:
第1部分 TreeMap介绍
第2部分 TreeMap数据结构
第3部分 TreeMap源码解析(基于JDK1.6.0_45)
第4部分 TreeMap遍历方式
第5部分 TreeMap示例
2) TreeMap介绍
TreeMap 简介
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Blacktree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator方法返回的迭代器是fail-fastl的。
TreeMap的构造函数
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。
TreeMap()
// 创建的TreeMap包含Map
TreeMap(Map<?extends K, ? extends V> copyFrom)
// 指定Tree的比较器
TreeMap(Comparator<?super K> comparator)
// 创建的TreeSet包含copyFrom
TreeMap(SortedMap<K,? extends V> copyFrom)
TreeMap的API
Entry<K,V> ceilingEntry(K key)
K ceilingKey(K key)
void clear()
Object clone()
Comparator<?super K> comparator()
boolean containsKey(Object key)
NavigableSet<K> descendingKeySet()
NavigableMap<K,V> descendingMap()
Set<Entry<K,V>> entrySet()
Entry<K,V> firstEntry()
K firstKey()
Entry<K,V> floorEntry(K key)
K floorKey(K key)
V get(Object key)
NavigableMap<K,V> headMap(K to, booleaninclusive)
SortedMap<K,V> headMap(K toExclusive)
Entry<K,V> higherEntry(K key)
K higherKey(K key)
boolean isEmpty()
Set<K> keySet()
Entry<K,V> lastEntry()
K lastKey()
Entry<K,V> lowerEntry(K key)
K lowerKey(K key)
NavigableSet<K> navigableKeySet()
Entry<K,V> pollFirstEntry()
Entry<K,V> pollLastEntry()
V put(K key, V value)
V remove(Object key)
int size()
SortedMap<K,V> subMap(K fromInclusive,K toExclusive)
NavigableMap<K,V> subMap(K from, boolean fromInclusive,K to, boolean toInclusive)
NavigableMap<K,V> tailMap(K from, booleaninclusive)
SortedMap<K,V> tailMap(K fromInclusive)
3) TreeMap数据结构
TreeMap的继承关系
java.lang.Object
java.util.AbstractMap<K, V>
java.util.TreeMap<K, V>
public classTreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>,Cloneable, java.io.Serializable {}
TreeMap与Map关系可以看出:
(01) TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
(02) TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量:root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
关于红黑数的具体算法,请参考"红黑树原理和算法详细介绍"。
4) TreeMap源码解析
为了更了解TreeMap的原理,下面对TreeMap源码代码作出分析。我们先给出源码内容,后面再对源码进行详细说明,当然,源码内容中也包含了详细的代码注释。读者阅读的时候,建议先看后面的说明,先建立一个整体印象;之后再阅读源码。
说明:
在详细介绍TreeMap的代码之前,我们先建立一个整体概念。
TreeMap是通过红黑树实现的,TreeMap存储的是key-value键值对,TreeMap的排序是基于对key的排序。
TreeMap提供了操作“key”、“key-value”、“value”等方法,也提供了对TreeMap这颗树进行整体操作的方法,如获取子树、反向树。
后面的解说内容分为几部分,
首先,介绍TreeMap的核心,即红黑树相关部分;
然后,介绍TreeMap的主要函数;
再次,介绍TreeMap实现的几个接口;
最后,补充介绍TreeMap的其它内容。
TreeMap本质上是一颗红黑树。要彻底理解TreeMap,建议读者先理解红黑树。关于红黑树的原理,可以参考:红黑树(一) 原理和算法详细介绍
第3.1部分 TreeMap的红黑树相关内容
TreeMap中于红黑树相关的主要函数有:
1 数据结构
1.1 红黑树的节点颜色--红色
private staticfinal boolean RED = false;
1.2 红黑树的节点颜色--黑色
private staticfinal boolean BLACK = true;
1.3 “红黑树的节点”对应的类。
static final classEntry<K,V> implements Map.Entry<K,V> { ... }
Entry包含了6个部分内容:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)
Entry节点根据key进行排序,Entry节点包含的内容为value。
2 相关操作
2.1 左旋
private voidrotateLeft(Entry<K,V> p) { ... }
2.2 右旋
private voidrotateRight(Entry<K,V> p) { ... }
2.3 插入操作
public V put(Kkey, V value) { ... }
2.4 插入修正操作
红黑树执行插入操作之后,要执行“插入修正操作”。
目的是:保红黑树在进行插入节点之后,仍然是一颗红黑树
private voidfixAfterInsertion(Entry<K,V> x) { ... }
2.5 删除操作
private voiddeleteEntry(Entry<K,V> p) { ... }
2.6 删除修正操作
红黑树执行删除之后,要执行“删除修正操作”。
目的是保证:红黑树删除节点之后,仍然是一颗红黑树
private voidfixAfterDeletion(Entry<K,V> x) { ... }
关于红黑树部分,这里主要是指出了TreeMap中那些是红黑树的主要相关内容。具体的红黑树相关操作API,这里没有详细说明,因为它们仅仅只是将算法翻译成代码。读者可以参考“红黑树(一) 原理和算法详细介绍”进行了解。
第3.2部分 TreeMap的构造函数
1 默认构造函数
使用默认构造函数构造TreeMap时,使用java的默认的比较器比较Key的大小,从而对TreeMap进行排序。
public TreeMap() {
comparator = null;
}
2 带比较器的构造函数
publicTreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
3 带Map的构造函数,Map会成为TreeMap的子集
publicTreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
该构造函数会调用putAll()将m中的所有元素添加到TreeMap中。putAll()源码如下:
public voidputAll(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extendsV> e : m.entrySet())
put(e.getKey(), e.getValue());
}
从中,我们可以看出putAll()就是将m中的key-value逐个的添加到TreeMap中。
4 带SortedMap的构造函数,SortedMap会成为TreeMap的子集
publicTreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(),m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen){
} catch (ClassNotFoundExceptioncannotHappen) {
}
}
该构造函数不同于上一个构造函数,在上一个构造函数中传入的参数是Map,Map不是有序的,所以要逐个添加。
而该构造函数的参数是SortedMap是一个有序的Map,我们通过buildFromSorted()来创建对应的Map。
buildFromSorted涉及到的代码如下:
要理解buildFromSorted,重点说明以下几点:
第一,buildFromSorted是通过递归将SortedMap中的元素逐个关联。
第二,buildFromSorted返回middle节点(中间节点)作为root。
第三,buildFromSorted添加到红黑树中时,只将level == redLevel的节点设为红色。第level级节点,实际上是buildFromSorted转换成红黑树后的最底端(假设根节点在最上方)的节点;只将红黑树最底端的阶段着色为红色,其余都是黑色。
第3.3部分 TreeMap的Entry相关函数
TreeMap的 firstEntry()、lastEntry()、 lowerEntry()、higherEntry()、 floorEntry()、ceilingEntry()、 pollFirstEntry() 、 pollLastEntry() 原理都是类似的;下面以firstEntry()来进行详细说明
我们先看看firstEntry()和getFirstEntry()的代码:
publicMap.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}
finalEntry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
从中,我们可以看出 firstEntry() 和 getFirstEntry() 都是用于获取第一个节点。
但是,firstEntry() 是对外接口; getFirstEntry() 是内部接口。而且,firstEntry() 是通过 getFirstEntry() 来实现的。那为什么外界不能直接调用getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?
先告诉大家原因,再进行详细说明。这么做的目的是:防止用户修改返回的Entry。getFirstEntry()返回的Entry是可以被修改的,但是经过firstEntry()返回的Entry不能被修改,只可以读取Entry的key值和value值。下面我们看看到底是如何实现的。
(01)getFirstEntry()返回的是Entry节点,而Entry是红黑树的节点,它的源码如下:
// 返回“红黑树的第一个节点”
finalEntry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
从中,我们可以调用Entry的getKey()、getValue()来获取key和value值,以及调用setValue()来修改value的值。
(02) firstEntry()返回的是exportEntry(getFirstEntry())。下面我们看看exportEntry()干了些什么?
static <K,V>Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) {
return e == null? null :
newAbstractMap.SimpleImmutableEntry<K,V>(e);
}
实际上,exportEntry() 是新建一个AbstractMap.SimpleImmutableEntry类型的对象,并返回。
SimpleImmutableEntry的实现在AbstractMap.java中,下面我们看看AbstractMap.SimpleImmutableEntry是如何实现的,代码如下:
从中,我们可以看出SimpleImmutableEntry实际上是简化的key-value节点。
它只提供了getKey()、getValue()方法类获取节点的值;但不能修改value的值,因为调用 setValue() 会抛出异常UnsupportedOperationException();
再回到我们之前的问题:那为什么外界不能直接调用getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?
现在我们清晰的了解到:
(01) firstEntry()是对外接口,而getFirstEntry()是内部接口。
(02) 对firstEntry()返回的Entry对象只能进行getKey()、getValue()等读取操作;而对getFirstEntry()返回的对象除了可以进行读取操作之后,还可以通过setValue()修改值。
第3.4部分 TreeMap的key相关函数
TreeMap的firstKey()、lastKey()、lowerKey()、higherKey()、floorKey()、ceilingKey()原理都是类似的;下面以ceilingKey()来进行详细说明
ceilingKey(K key)的作用是“返回大于/等于key的最小的键值对所对应的KEY,没有的话返回null”,它的代码如下:
public KceilingKey(K key) {
return keyOrNull(getCeilingEntry(key));
}
ceilingKey()是通过getCeilingEntry()实现的。keyOrNull()的代码很简单,它是获取节点的key,没有的话,返回null。
static <K,V>K keyOrNull(TreeMap.Entry<K,V> e) {
return e == null? null : e.key;
}
getCeilingEntry(Kkey)的作用是“获取TreeMap中大于/等于key的最小的节点,若不存在(即TreeMap中所有节点的键都比key大),就返回null”。它的实现代码如下:
第3.5部分 TreeMap的values()函数
values() 返回“TreeMap中值的集合”
values()的实现代码如下:
publicCollection<V> values() {
Collection<V> vs = values;
return (vs != null) ? vs : (values = newValues());
}
说明:从中,我们可以发现values()是通过new Values() 来实现 “返回TreeMap中值的集合”。
那么Values()是如何实现的呢?没错!由于返回的是值的集合,那么Values()肯定返回一个集合;而Values()正好是集合类Value的构造函数。Values继承于AbstractCollection,它的代码如下:
说明:从中,我们可以知道Values类就是一个集合。而 AbstractCollection 实现了除 size() 和 iterator() 之外的其它函数,因此只需要在Values类中实现这两个函数即可。
size() 的实现非常简单,Values集合中元素的个数=该TreeMap的元素个数。(TreeMap每一个元素都有一个值嘛!)
iterator() 则返回一个迭代器,用于遍历Values。下面,我们一起可以看看iterator()的实现:
publicIterator<V> iterator() {
return new ValueIterator(getFirstEntry());
}
说明: iterator() 是通过ValueIterator() 返回迭代器的,ValueIterator是一个类。代码如下:
final classValueIterator extends PrivateEntryIterator<V> {
ValueIterator(Entry<K,V> first) {
super(first);
}
public V next() {
return nextEntry().value;
}
}
说明:ValueIterator的代码很简单,它的主要实现应该在它的父类PrivateEntryIterator中。下面我们一起看看PrivateEntryIterator的代码:
说明:PrivateEntryIterator是一个抽象类,它的实现很简单,只只实现了Iterator的remove()和hasNext()接口,没有实现next()接口。
而我们在ValueIterator中已经实现的next()接口。
至此,我们就了解了iterator()的完整实现了。
第3.6部分 TreeMap的entrySet()函数
entrySet() 返回“键值对集合”。顾名思义,它返回的是一个集合,集合的元素是“键值对”。
下面,我们看看它是如何实现的?entrySet()的实现代码如下:
publicSet<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = newEntrySet());
}
说明:entrySet()返回的是一个EntrySet对象。
下面我们看看EntrySet的代码:
说明:
EntrySet是“TreeMap的所有键值对组成的集合”,而且它单位是单个“键值对”。
EntrySet是一个集合,它继承于AbstractSet。而AbstractSet实现了除size() 和 iterator() 之外的其它函数,因此,我们重点了解一下EntrySet的size() 和iterator() 函数
size() 的实现非常简单,AbstractSet集合中元素的个数=该TreeMap的元素个数。
iterator() 则返回一个迭代器,用于遍历AbstractSet。从上面的源码中,我们可以发现iterator() 是通过EntryIterator实现的;下面我们看看EntryIterator的源码:
final classEntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> {
EntryIterator(Entry<K,V> first) {
super(first);
}
public Map.Entry<K,V> next() {
return nextEntry();
}
}
说明:和Values类一样,EntryIterator也继承于PrivateEntryIterator类。
第3.7部分 TreeMap实现的Cloneable接口
TreeMap实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个TreeMap对象并返回。
第3.8部分 TreeMap实现的Serializable接口
TreeMap实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数是writeObject(),它的作用是将TreeMap的“容量,所有的Entry”都写入到输出流中。
而串行读取函数是readObject(),它的作用是将TreeMap的“容量、所有的Entry”依次读出。
readObject() 和 writeObject() 正好是一对,通过它们,我能实现TreeMap的串行传输。
说到这里,就顺便说一下“关键字transient”的作用
transient是Java语言的关键字,它被用来表示一个域不是该对象串行化的一部分。
Java的serialization提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,我们不想用serialization机制来保存它。为了在一个特定对象的一个域上关闭serialization,可以在这个域前加上关键字transient。
当一个对象被串行化的时候,transient型变量的值不包括在串行化的表示中,然而非transient型的变量是被包括进去的。
第3.9部分 TreeMap实现的NavigableMap接口
firstKey()、lastKey()、lowerKey()、higherKey()、ceilingKey()、floorKey();
firstEntry()、 lastEntry()、lowerEntry()、 higherEntry()、floorEntry()、 ceilingEntry()、pollFirstEntry() 、 pollLastEntry();
上面已经讲解过这些API了,下面对其它的API进行说明。
1 反向TreeMap
descendingMap() 的作用是返回当前TreeMap的反向的TreeMap。所谓反向,就是排序顺序和原始的顺序相反。
我们已经知道TreeMap是一颗红黑树,而红黑树是有序的。
TreeMap的排序方式是通过比较器,在创建TreeMap的时候,若指定了比较器,则使用该比较器;否则,就使用Java的默认比较器。
而获取TreeMap的反向TreeMap的原理就是将比较器反向即可!
理解了descendingMap()的反向原理之后,再讲解一下descendingMap()的代码。
// 获取TreeMap的降序Map
publicNavigableMap<K, V> descendingMap() {
NavigableMap<K, V> km =descendingMap;
return (km != null) ? km :
(descendingMap = newDescendingSubMap(this,
true, null, true,
true,null, true));
}
从中,我们看出descendingMap()实际上是返回DescendingSubMap类的对象。下面,看看DescendingSubMap的源码:
从中,我们看出DescendingSubMap是降序的SubMap,它的实现机制是将“SubMap的比较器反转”。
它继承于NavigableSubMap。而NavigableSubMap是一个继承于AbstractMap的抽象类;它包括2个子类——"(升序)AscendingSubMap"和"(降序)DescendingSubMap"。NavigableSubMap为它的两个子类实现了许多公共API。
下面看看NavigableSubMap的源码。
NavigableSubMap源码很多,但不难理解;读者可以通过源码和注释进行理解。
其实,读完NavigableSubMap的源码后,我们可以得出它的核心思想是:它是一个抽象集合类,为2个子类——"(升序)AscendingSubMap"和"(降序)DescendingSubMap"而服务;因为NavigableSubMap实现了许多公共API。它的最终目的是实现下面的一系列函数:
headMap(K toKey,boolean inclusive)
headMap(K toKey)
subMap(K fromKey,K toKey)
subMap(K fromKey,boolean fromInclusive, K toKey, boolean toInclusive)
tailMap(K fromKey)
tailMap(K fromKey,boolean inclusive)
navigableKeySet()
descendingKeySet()
第3.10部分 TreeMap其它函数
1 顺序遍历和逆序遍历
TreeMap的顺序遍历和逆序遍历原理非常简单。
由于TreeMap中的元素是从小到大的顺序排列的。因此,顺序遍历,就是从第一个元素开始,逐个向后遍历;而倒序遍历则恰恰相反,它是从最后一个元素开始,逐个往前遍历。
我们可以通过 keyIterator() 和 descendingKeyIterator()来说明!
keyIterator()的作用是返回顺序的KEY的集合,
descendingKeyIterator()的作用是返回逆序的KEY的集合。
keyIterator() 的代码如下:
Iterator<K>keyIterator() {
return new KeyIterator(getFirstEntry());
}
说明:从中我们可以看出keyIterator()是返回以“第一个节点(getFirstEntry)” 为其实元素的迭代器。
KeyIterator的代码如下:
final classKeyIterator extends PrivateEntryIterator<K> {
KeyIterator(Entry<K,V> first) {
super(first);
}
public K next() {
return nextEntry().key;
}
}
说明:KeyIterator继承于PrivateEntryIterator。当我们通过next()不断获取下一个元素的时候,就是执行的顺序遍历了。
descendingKeyIterator()的代码如下:
Iterator<K>descendingKeyIterator() {
return newDescendingKeyIterator(getLastEntry());
}
说明:从中我们可以看出descendingKeyIterator()是返回以“最后一个节点(getLastEntry)” 为其实元素的迭代器。
再看看DescendingKeyIterator的代码:
final classDescendingKeyIterator extends PrivateEntryIterator<K> {
DescendingKeyIterator(Entry<K,V>first) {
super(first);
}
public K next() {
return prevEntry().key;
}
}
说明:DescendingKeyIterator继承于PrivateEntryIterator。当我们通过next()不断获取下一个元素的时候,实际上调用的是prevEntry()获取的上一个节点,这样它实际上执行的是逆序遍历了。
至此,TreeMap的相关内容就全部介绍完毕了!
5) TreeMap遍历方式
4.1 遍历TreeMap的键值对
第一步:根据entrySet()获取TreeMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
Integer integ =null;
Iterator iter =map.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ= (Integer)entry.getValue();
}
4.2 遍历TreeMap的键
第一步:根据keySet()获取TreeMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ =null;
Iterator iter = map.keySet().iterator();
while(iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)map.get(key);
}
4.3 遍历TreeMap的值
第一步:根据value()获取TreeMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是TreeMap对象
// map中的key是String类型,value是Integer类型
Integer value =null;
Collection c =map.values();
Iterator iter=c.iterator();
while(iter.hasNext()) {
value = (Integer)iter.next();
}
6) TreeMap示例
import
/**
* @desc TreeMap测试程序
*
* @author skywang
*/
public classTreeMapTest {
public static void main(String[] args) {
// 测试常用的API
testTreeMapOridinaryAPIs();
// 测试TreeMap的导航函数
//testNavigableMapAPIs();
// 测试TreeMap的子Map函数
//testSubMapAPIs();
}
/**
* 测试常用的API
*/
private static voidtestTreeMapOridinaryAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建TreeMap
TreeMap tmap = new TreeMap();
// 添加操作
tmap.put("one",r.nextInt(10));
tmap.put("two",r.nextInt(10));
tmap.put("three",r.nextInt(10));
System.out.printf("\n ----testTreeMapOridinaryAPIs ----\n");
// 打印出TreeMap
System.out.printf("%s\n",tmap);
// 通过Iterator遍历key-value
Iterator iter =tmap.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry =(Map.Entry)iter.next();
System.out.printf("next : %s -%s\n", entry.getKey(), entry.getValue());
}
// TreeMap的键值对个数
System.out.printf("size:%s\n", tmap.size());
// containsKey(Object key) :是否包含键key
System.out.printf("contains keytwo : %s\n",tmap.containsKey("two"));
System.out.printf("contains keyfive : %s\n",tmap.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.printf("contains value0 : %s\n",tmap.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
tmap.remove("three");
System.out.printf("tmap:%s\n",tmap );
// clear() : 清空TreeMap
tmap.clear();
// isEmpty() : TreeMap是否为空
System.out.printf("%s\n",(tmap.isEmpty()?"tmap is empty":"tmap is not empty") );
}
/**
* 测试TreeMap的子Map函数
*/
public static void testSubMapAPIs() {
// 新建TreeMap
TreeMap tmap = new TreeMap();
// 添加“键值对”
tmap.put("a", 101);
tmap.put("b", 102);
tmap.put("c", 103);
tmap.put("d", 104);
tmap.put("e", 105);
System.out.printf("\n ----testSubMapAPIs ----\n");
// 打印出TreeMap
System.out.printf("tmap:\n\t%s\n", tmap);
// 测试 headMap(K toKey)
System.out.printf("tmap.headMap(\"c\"):\n\t%s\n",tmap.headMap("c"));
// 测试 headMap(K toKey, boolean inclusive)
System.out.printf("tmap.headMap(\"c\",true):\n\t%s\n", tmap.headMap("c", true));
System.out.printf("tmap.headMap(\"c\",false):\n\t%s\n", tmap.headMap("c", false));
// 测试 tailMap(K fromKey)
System.out.printf("tmap.tailMap(\"c\"):\n\t%s\n",tmap.tailMap("c"));
// 测试 tailMap(K fromKey, boolean inclusive)
System.out.printf("tmap.tailMap(\"c\",true):\n\t%s\n", tmap.tailMap("c", true));
System.out.printf("tmap.tailMap(\"c\",false):\n\t%s\n", tmap.tailMap("c", false));
// 测试 subMap(K fromKey, K toKey)
System.out.printf("tmap.subMap(\"a\",\"c\"):\n\t%s\n", tmap.subMap("a", "c"));
// 测试
System.out.printf("tmap.subMap(\"a\", true,\"c\", true):\n\t%s\n",
tmap.subMap("a",true, "c", true));
System.out.printf("tmap.subMap(\"a\", true,\"c\", false):\n\t%s\n",
tmap.subMap("a",true, "c", false));
System.out.printf("tmap.subMap(\"a\", false,\"c\", true):\n\t%s\n",
tmap.subMap("a",false, "c", true));
System.out.printf("tmap.subMap(\"a\", false,\"c\", false):\n\t%s\n",
tmap.subMap("a",false, "c", false));
// 测试 navigableKeySet()
System.out.printf("tmap.navigableKeySet():\n\t%s\n",tmap.navigableKeySet());
// 测试 descendingKeySet()
System.out.printf("tmap.descendingKeySet():\n\t%s\n",tmap.descendingKeySet());
}
/**
* 测试TreeMap的导航函数
*/
public static void testNavigableMapAPIs() {
// 新建TreeMap
NavigableMap nav = new TreeMap();
// 添加“键值对”
nav.put("aaa", 111);
nav.put("bbb", 222);
nav.put("eee", 333);
nav.put("ccc", 555);
nav.put("ddd", 444);
System.out.printf("\n ----testNavigableMapAPIs ----\n");
// 打印出TreeMap
System.out.printf("Wholelist:%s%n", nav);
// 获取第一个key、第一个Entry
System.out.printf("First key:%s\tFirst entry: %s%n",nav.firstKey(), nav.firstEntry());
// 获取最后一个key、最后一个Entry
System.out.printf("Last key:%s\tLast entry: %s%n",nav.lastKey(), nav.lastEntry());
// 获取“小于/等于bbb”的最大键值对
System.out.printf("Key floorbefore bbb: %s%n",nav.floorKey("bbb"));
// 获取“小于bbb”的最大键值对
System.out.printf("Key lowerbefore bbb: %s%n", nav.lowerKey("bbb"));
// 获取“大于/等于bbb”的最小键值对
System.out.printf("Key ceilingafter ccc: %s%n",nav.ceilingKey("ccc"));
// 获取“大于bbb”的最小键值对
System.out.printf("Key higher afterccc: %s%n\n",nav.higherKey("ccc"));
}
}
五、 WeakHashMap类
1) 概要
这一章,我们对WeakHashMap进行学习。
我们先对WeakHashMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用WeakHashMap。
第1部分 WeakHashMap介绍
第2部分 WeakHashMap数据结构
第3部分 WeakHashMap源码解析(基于JDK1.6.0_45)
第4部分 WeakHashMap遍历方式
第5部分 WeakHashMap示例
2) WeakHashMap介绍
WeakHashMap简介
WeakHashMap 继承于AbstractMap,实现了Map接口。
和HashMap一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null。
不过WeakHashMap的键是“弱键”。在 WeakHashMap 中,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个“弱键”的原理呢?大致上就是,通过WeakReference和ReferenceQueue实现的。 WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。实现步骤是:
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02) 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。
这就是“弱键”如何被自动从WeakHashMap中删除的步骤了。
和HashMap一样,WeakHashMap是不同步的。可以使用Collections.synchronizedMap 方法来构造同步的 WeakHashMap。
WeakHashMap的构造函数
WeakHashMap共有4个构造函数,如下:
// 默认构造函数。
WeakHashMap()
// 指定“容量大小”的构造函数
WeakHashMap(intcapacity)
// 指定“容量大小”和“加载因子”的构造函数
WeakHashMap(intcapacity, float loadFactor)
// 包含“子Map”的构造函数
WeakHashMap(Map<?extends K, ? extends V> map)
WeakHashMap的API
void clear()
Object clone()
boolean containsKey(Object key)
boolean containsValue(Object value)
Set<Entry<K,V>> entrySet()
V get(Object key)
boolean isEmpty()
Set<K> keySet()
V put(K key, V value)
void putAll(Map<? extends K, ?extends V> map)
V remove(Object key)
int size()
Collection<V> values()
3) WeakHashMap数据结构
WeakHashMap与Map关系可以看出:
(01) WeakHashMap继承于AbstractMap,并且实现了Map接口。
(02) WeakHashMap是哈希表,但是它的键是"弱键"。WeakHashMap中保护几个重要的成员变量:table, size,threshold, loadFactor, modCount, queue。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
queue保存的是“已被GC清除”的“弱引用的键”。
4) WeakHashMap源码解析
下面对WeakHashMap的源码进行
说明:WeakHashMap和HashMap都是通过"拉链法"实现的散列表。它们的源码绝大部分内容都一样,这里就只是对它们不同的部分就是说明。
WeakReference是“弱键”实现的哈希表。它这个“弱键”的目的就是:实现对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
“弱键”是一个“弱引用(WeakReference)”,在Java中,WeakReference和ReferenceQueue 是联合使用的。在WeakHashMap中亦是如此:如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。接着,WeakHashMap会根据“引用队列”,来删除“WeakHashMap中已被GC回收的‘弱键’对应的键值对”。
另外,理解上面思想的重点是通过 expungeStaleEntries() 函数去理解。
5) WeakHashMap遍历方式
4.1 遍历WeakHashMap的键值对
第一步:根据entrySet()获取WeakHashMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是WeakHashMap对象
// map中的key是String类型,value是Integer类型
Integer integ =null;
Iterator iter =map.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
}
4.2 遍历WeakHashMap的键
第一步:根据keySet()获取WeakHashMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是WeakHashMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ =null;
Iterator iter =map.keySet().iterator();
while(iter.hasNext()) {
// 获取key
key = (String)iter.next();
// 根据key,获取value
integ = (Integer)map.get(key);
}
4.3 遍历WeakHashMap的值
第一步:根据value()获取WeakHashMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是WeakHashMap对象
// map中的key是String类型,value是Integer类型
Integer value =null;
Collection c =map.values();
Iterator iter=c.iterator();
while(iter.hasNext()) {
value = (Integer)iter.next();
}
6) WeakHashMap示例
import java.util.Iterator;
importjava.util.Map;
importjava.util.WeakHashMap;
importjava.util.Date;
importjava.lang.ref.WeakReference;
/**
* @desc WeakHashMap测试程序
*
* @author skywang
* @email kuiwu-wang@163.com
*/
public classWeakHashMapTest {
public static void main(String[] args)throws Exception {
testWeakHashMapAPIs();
}
private static void testWeakHashMapAPIs() {
// 初始化3个“弱键”
String w1 = newString("one");
String w2 = newString("two");
String w3 = newString("three");
// 新建WeakHashMap
Map wmap = new WeakHashMap();
// 添加键值对
wmap.put(w1, "w1");
wmap.put(w2, "w2");
wmap.put(w3, "w3");
// 打印出wmap
System.out.printf("\nwmap:%s\n",wmap );
// containsKey(Object key) :是否包含键key
System.out.printf("contains keytwo : %s\n",wmap.containsKey("two"));
System.out.printf("contains keyfive : %s\n",wmap.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.printf("contains value0 : %s\n",wmap.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
wmap.remove("three");
System.out.printf("wmap:%s\n",wmap );
// ---- 测试 WeakHashMap 的自动回收特性 ----
// 将w1设置null。
// 这意味着“弱键”w1再没有被其它对象引用,调用gc时会回收WeakHashMap中与“w1”对应的键值对
w1 = null;
// 内存回收。这里,会回收WeakHashMap中与“w1”对应的键值对
System.gc();
// 遍历WeakHashMap
Iterator iter =wmap.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry en =(Map.Entry)iter.next();
System.out.printf("next : %s -%s\n",en.getKey(),en.getValue());
}
// 打印WeakHashMap的实际大小
System.out.printf(" after gcWeakHashMap size:%s\n", wmap.size());
}
}
六、 Map总结
1) 概要
本章内容包括:
第1部分 Map概括
第2部分 HashMap和Hashtable异同
第3部分 HashMap和WeakHashMap异同
2) Map概括
(01) Map 是“键值对”映射的抽象接口。
(02) AbstractMap 实现了Map中的绝大部分函数接口。它减少了“Map的实现类”的重复编码。
(03) SortedMap 有序的“键值对”映射接口。
(04) NavigableMap 是继承于SortedMap的,支持导航函数的接口。
(05) HashMap,Hashtable, TreeMap, WeakHashMap这4个类是“键值对”映射的实现类。它们各有区别!
HashMap 是基于“拉链法”实现的散列表。一般用于单线程程序中。
Hashtable 也是基于“拉链法”实现的散列表。它一般用于多线程程序中。
WeakHashMap 也是基于“拉链法”实现的散列表,它一般也用于单线程程序中。相比HashMap,WeakHashMap中的键是“弱键”,当“弱键”被GC回收时,它对应的键值对也会被从WeakHashMap中删除;而HashMap中的键是强键。
TreeMap 是有序的散列表,它是通过红黑树实现的。它一般用于单线程中存储有序的映射。
3) HashMap和Hashtable异同
第2.1部分 HashMap和Hashtable的相同点
HashMap和Hashtable都是存储“键值对(key-value)”的散列表,而且都是采用拉链法实现的。
存储的思想都是:通过table数组存储,数组的每一个元素都是一个Entry;而一个Entry就是一个单向链表,Entry链表中的每一个节点就保存了key-value键值对数据。
添加key-value键值对:首先,根据key值计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据数组索引找到Entry(即,单向链表),再遍历单向链表,将key和链表中的每一个节点的key进行对比。若key已经存在Entry链表中,则用该value值取代旧的value值;若key不存在Entry链表中,则新建一个key-value节点,并将该节点插入Entry链表的表头位置。
删除key-value键值对:删除键值对,相比于“添加键值对”来说,简单很多。首先,还是根据key计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据索引找出Entry(即,单向链表)。若节点key-value存在与链表Entry中,则删除链表中的节点即可。
上面介绍了HashMap和Hashtable的相同点。正是由于它们都是散列表,我们关注更多的是“它们的区别,以及它们分别适合在什么情况下使用”。那接下来,我们先看看它们的区别。
第2.2部分 HashMap和Hashtable的不同点
1 继承和实现方式不同
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
HashMap的定义:
public classHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable,Serializable { ... }
Hashtable的定义:
public classHashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable,java.io.Serializable { ... }
从中,我们可以看出:
1.1 HashMap和Hashtable都实现了Map、Cloneable、java.io.Serializable接口。
实现了Map接口,意味着它们都支持key-value键值对操作。支持“添加key-value键值对”、“获取key”、“获取value”、“获取map大小”、“清空map”等基本的key-value键值对操作。
实现了Cloneable接口,意味着它能被克隆。
实现了java.io.Serializable接口,意味着它们支持序列化,能通过序列化去传输。
1.2 HashMap继承于AbstractMap,而Hashtable继承于Dictionary
Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。Dictionary类是JDK 1.0的引入的。虽然Dictionary也支持“添加key-value键值对”、“获取value”、“获取大小”等基本操作,但它的API函数比Map少;而且 Dictionary一般是通过Enumeration(枚举类)去遍历,Map则是通过Iterator(迭代器)去遍历。 然而‘由于Hashtable也实现了Map接口,所以,它即支持Enumeration遍历,也支持Iterator遍历。关于这点,后面还会进一步说明。
AbstractMap是一个抽象类,它实现了Map接口的绝大部分API函数;为Map的具体实现类提供了极大的便利。它是JDK 1.2新增的类。
2 线程安全不同
Hashtable的几乎所有函数都是同步的,即它是线程安全的,支持多线程。
而HashMap的函数则是非同步的,它不是线程安全的。若要在多线程中使用HashMap,需要我们额外的进行同步处理。 对HashMap的同步处理可以使用Collections类提供的synchronizedMap静态方法,或者直接使用JDK 5.0之后提供的java.util.concurrent包里的ConcurrentHashMap类。
3 对null值的处理不同
HashMap的key、value都可以为null。
Hashtable的key、value都不可以为null。
我们先看看HashMap和Hashtable “添加key-value”的方法
HashMap的添加key-value的方法
Hashtable的添加key-value的方法
根据上面的代码,我们可以看出:
Hashtable的key或value,都不能为null!否则,会抛出异常NullPointerException。
HashMap的key、value都可以为null。 当HashMap的key为null时,HashMap会将其固定的插入table[0]位置(即HashMap散列表的第一个位置);而且table[0]处只会容纳一个key为null的值,当有多个key为null的值插入的时候,table[0]会保留最后插入的value。
4 支持的遍历种类不同
HashMap只支持Iterator(迭代器)遍历。
而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
Enumeration 是JDK 1.0添加的接口,只有hasMoreElements(),nextElement() 两个API接口,不能通过Enumeration()对元素进行修改。
而Iterator 是JDK 1.2才添加的接口,支持hasNext(), next(), remove() 三个API接口。HashMap也是JDK1.2版本才添加的,所以用Iterator取代Enumeration,HashMap只支持Iterator遍历。
5 通过Iterator迭代器遍历时,遍历的顺序不同
HashMap是“从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
Hashtabl是“从后往前”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
HashMap和Hashtable都实现Map接口,所以支持获取它们“key的集合”、“value的集合”、“key-value的集合”,然后通过Iterator对这些集合进行遍历。
由于“key的集合”、“value的集合”、“key-value的集合”的遍历原理都是一样的;下面,我以遍历“key-value的集合”来进行说明。
HashMap 和Hashtable 遍历"key-value集合"的方式是:(01) 通过entrySet()获取“Map.Entry集合”。 (02) 通过iterator()获取“Map.Entry集合”的迭代器,再进行遍历。
HashMap的实现方式:先“从前向后”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
Hashtable的实现方式:先从“后向往前”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
6 容量的初始值 和 增加方式都不一样
HashMap默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
HashMap默认的“加载因子”是0.75, 默认的容量大小是16。
当HashMap的 “实际容量” >= “阈值”时,(阈值 = 总的容量 * 加载因子),就将HashMap的容量翻倍。
Hashtable默认的“加载因子”是0.75, 默认的容量大小是11。
当Hashtable的 “实际容量” >= “阈值”时,(阈值 = 总的容量 x 加载因子),就将变为“原始容量x2+ 1”。
7 添加key-value时的hash值算法不同
HashMap添加元素时,是使用自定义的哈希算法。
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
HashMap添加元素时,是使用自定义的哈希算法。
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
8 部分API不同
Hashtable支持contains(Object value)方法,而且重写了toString()方法;
而HashMap不支持contains(Object value)方法,没有重写toString()方法。
最后,再说说“HashMap和Hashtable”使用的情景。
其实,若了解它们之间的不同之处后,可以很容易的区分根据情况进行取舍。例如:(01) 若在单线程中,我们往往会选择HashMap;而在多线程中,则会选择Hashtable。(02),若不能插入null元素,则选择Hashtable;否则,可以选择HashMap。
但这个不是绝对的标准。例如,在多线程中,我们可以自己对HashMap进行同步,也可以选择ConcurrentHashMap。当HashMap和Hashtable都不能满足自己的需求时,还可以考虑新定义一个类,继承或重新实现散列表;当然,一般情况下是不需要的了。
4) HashMap和WeakHashMap异同
3.1 HashMap和WeakHashMap的相同点
1 它们都是散列表,存储的是“键值对”映射。
2 它们都继承于AbstractMap,并且实现Map基础。
3 它们的构造函数都一样。
它们都包括4个构造函数,而且函数的参数都一样。
4 默认的容量大小是16,默认的加载因子是0.75。
5 它们的“键”和“值”都允许为null。
6 它们都是“非同步的”。
3.2 HashMap和WeakHashMap的不同点
1 HashMap实现了Cloneable和Serializable接口,而WeakHashMap没有。
HashMap实现Cloneable,意味着它能通过clone()克隆自己。
HashMap实现Serializable,意味着它支持序列化,能通过序列化去传输。
2 HashMap的“键”是“强引用(StrongReference)”,而WeakHashMap的键是“弱引用(WeakReference)”。
WeakReference的“弱键”能实现WeakReference对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
这个“弱键”实现的动态回收“键值对”的原理呢?其实,通过WeakReference(弱引用)和ReferenceQueue(引用队列)实现的。 首先,我们需要了解WeakHashMap中:
第一,“键”是WeakReference,即key是弱键。
第二,ReferenceQueue是一个引用队列,它是和WeakHashMap联合使用的。当弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 WeakHashMap中的ReferenceQueue是queue。
第三,WeakHashMap是通过数组实现的,我们假设这个数组是table。
接下来,说说“动态回收”的步骤。
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
将“键值对”添加到WeakHashMap中时,添加的键都是弱键。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02) 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到queue队列中。
例如,当我们在将“弱键”key添加到WeakHashMap之后;后来将key设为null。这时,便没有外部外部对象再引用该了key。
接着,当Java虚拟机的GC回收内存时,会回收key的相关内存;同时,将key添加到queue队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的“弱键”;同步它们,就是删除table中被GC回收的“弱键”对应的键值对。
例如,当我们“读取WeakHashMap中的元素或获取WeakReference的大小时”,它会先同步table和queue,目的是“删除table中被GC回收的‘弱键’对应的键值对”。删除的方法就是逐个比较“table中元素的‘键’和queue中的‘键’”,若它们相当,则删除“table中的该键值对”。
3.3 HashMap和WeakHashMap的比较测试程序
importjava.util.HashMap;
importjava.util.Iterator;
importjava.util.Map;
importjava.util.WeakHashMap;
importjava.util.Date;
importjava.lang.ref.WeakReference;
/**
* @desc HashMap 和 WeakHashMap比较程序
*
* @author skywang
* @email kuiwu-wang@163.com
*/
public classCompareHashmapAndWeakhashmap {
public static void main(String[] args)throws Exception {
// 当“弱键”是String时,比较HashMap和WeakHashMap
compareWithString();
// 当“弱键”是自定义类型时,比较HashMap和WeakHashMap
compareWithSelfClass();
}
/**
* 遍历map,并打印map的大小
*/
private static void iteratorAndCountMap(Mapmap) {
// 遍历map
for (Iterator iter =map.entrySet().iterator();
iter.hasNext(); ) {
Map.Entry en =(Map.Entry)iter.next();
System.out.printf("map entry :%s - %s\n ",en.getKey(), en.getValue());
}
// 打印HashMap的实际大小
System.out.printf(" mapsize:%s\n\n", map.size());
}
/**
* 通过String对象测试HashMap和WeakHashMap
*/
private static void compareWithString() {
// 新建4个String字符串
String w1 = new String("W1");
String w2 = new String("W2");
String h1 = new String("H1");
String h2 = new String("H2");
// 新建 WeakHashMap对象,并将w1,w2添加到 WeakHashMap中
Map wmap = new WeakHashMap();
wmap.put(w1, "w1");
wmap.put(w2, "w2");
// 新建 HashMap对象,并将h1,h2添加到 WeakHashMap中
Map hmap = new HashMap();
hmap.put(h1, "h1");
hmap.put(h2, "h2");
// 删除HashMap中的“h1”。
// 结果:删除“h1”之后,HashMap中只有 h2 !
hmap.remove(h1);
// 将WeakHashMap中的w1设置null,并执行gc()。系统会回收w1
// 结果:w1是“弱键”,被GC回收后,WeakHashMap中w1对应的键值对,也会被从WeakHashMap中删除。
// w2是“弱键”,但它不是null,不会被GC回收;也就不会被从WeakHashMap中删除。
// 因此,WeakHashMap中只有 w2
// 注意:若去掉“w1=null” 或者“System.gc()”,结果都会不一样!
w1 = null;
System.gc();
// 遍历并打印HashMap的大小
System.out.printf(" -- HashMap--\n");
iteratorAndCountMap(hmap);
// 遍历并打印WeakHashMap的大小
System.out.printf(" -- WeakHashMap--\n");
iteratorAndCountMap(wmap);
}
/**
* 通过自定义类测试HashMap和WeakHashMap
*/
private static void compareWithSelfClass(){
// 新建4个自定义对象
Self s1 = new Self(10);
Self s2 = new Self(20);
Self s3 = new Self(30);
Self s4 = new Self(40);
// 新建 WeakHashMap对象,并将s1,s2添加到 WeakHashMap中
Map wmap = new WeakHashMap();
wmap.put(s1, "s1");
wmap.put(s2, "s2");
// 新建 HashMap对象,并将s3,s4添加到 WeakHashMap中
Map hmap = new HashMap();
hmap.put(s3, "s3");
hmap.put(s4, "s4");
// 删除HashMap中的s3。
// 结果:删除s3之后,HashMap中只有 s4 !
hmap.remove(s3);
// 将WeakHashMap中的s1设置null,并执行gc()。系统会回收w1
// 结果:s1是“弱键”,被GC回收后,WeakHashMap中s1对应的键值对,也会被从WeakHashMap中删除。
// w2是“弱键”,但它不是null,不会被GC回收;也就不会被从WeakHashMap中删除。
// 因此,WeakHashMap中只有 s2
// 注意:若去掉“s1=null” 或者“System.gc()”,结果都会不一样!
s1 = null;
System.gc();
/*
// 休眠500ms
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
// */
// 遍历并打印HashMap的大小
System.out.printf(" -- Self-defHashMap --\n");
iteratorAndCountMap(hmap);
// 遍历并打印WeakHashMap的大小
System.out.printf(" -- Self-defWeakHashMap --\n");
iteratorAndCountMap(wmap);
}
private static class Self {
int id;
public Self(int id) {
this.id = id;
}
// 覆盖finalize()方法
// 在GC回收时会被执行
protected void finalize() throws Throwable{
super.finalize();
System.out.printf("GC Self:id=%d addr=0x%s)\n", id, this);
}
}
}
七、 Set架构
1) 概要
前面,我们已经系统的对List和Map进行了学习。接下来,我们开始可以学习Set。相信经过Map的了解之后,学习Set会容易很多。毕竟,Set的实现类都是基于Map来实现的(HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的)。
首先,我们看看Set架构。
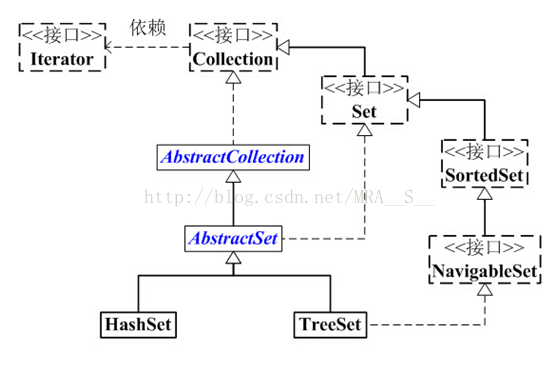
(01) Set 是继承于Collection的接口。它是一个不允许有重复元素的集合。
(02) AbstractSet 是一个抽象类,它继承于AbstractCollection,AbstractCollection实现了Set中的绝大部分函数,为Set的实现类提供了便利。
(03) HastSet 和 TreeSet 是Set的两个实现类。
HashSet依赖于HashMap,它实际上是通过HashMap实现的。HashSet中的元素是无序的。
TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。TreeSet中的元素是有序的。
八、 HashSet类
1) 概要
这一章,我们对HashSet进行学习。
我们先对HashSet有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashSet。内容包括:
第1部分 HashSet介绍
第2部分 HashSet数据结构
第3部分 HashSet源码解析(基于JDK1.6.0_45)
第4部分 HashSet遍历方式
第5部分 HashSet示例
2) HashSet介绍
HashSet 简介
HashSet 是一个没有重复元素的集合。
它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素。
HashSet是非同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s =Collections.synchronizedSet(new HashSet(...));
HashSet通过iterator()返回的迭代器是fail-fast的。
HashSet的构造函数
// 默认构造函数
public HashSet()
// 带集合的构造函数
publicHashSet(Collection<? extends E> c)
// 指定HashSet初始容量和加载因子的构造函数
public HashSet(intinitialCapacity, float loadFactor)
// 指定HashSet初始容量的构造函数
public HashSet(intinitialCapacity)
// 指定HashSet初始容量和加载因子的构造函数,dummy没有任何作用
HashSet(intinitialCapacity, float loadFactor, boolean dummy)
HashSet的主要API
boolean add(E object)
void clear()
Object clone()
boolean contains(Object object)
boolean isEmpty()
Iterator<E> iterator()
boolean remove(Object object)
int size()
3) HashSet数据结构
HashSet的继承关系如下:
java.lang.Object
java.util.AbstractCollection<E>
java.util.AbstractSet<E>
java.util.HashSet<E>
public classHashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable,java.io.Serializable { }
HashSet与Map关系可以看出:
(01) HashSet继承于AbstractSet,并且实现了Set接口。
(02) HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的。
4) HashSet源码解析
为了更了解HashSet的原理,对HashSet源码代码作出分析。
说明: HashSet的代码实际上非常简单,通过上面的注释应该很能够看懂。它是通过HashMap实现的,若对HashSet的理解有困难,建议先学习以下HashMap;学完HashMap之后,在学习HashSet就非常容易了。
5) HashSet遍历方式
4.1 通过Iterator遍历HashSet
第一步:根据iterator()获取HashSet的迭代器。
第二步:遍历迭代器获取各个元素。
// 假设set是HashSet对象
for(Iteratoriterator = set.iterator();
iterator.hasNext(); ) {
iterator.next();
}
4.2 通过for-each遍历HashSet
第一步:根据toArray()获取HashSet的元素集合对应的数组。
第二步:遍历数组,获取各个元素。
// 假设set是HashSet对象,并且set中元素是String类型
String[] arr =(String[])set.toArray(new String[0]);
for (Stringstr:arr)
System.out.printf("for each :%s\n", str);
6) HashSet示例
importjava.util.Iterator;
importjava.util.HashSet;
/*
* @desc HashSet常用API的使用。
*
* @author skywang
*/
public classHashSetTest {
public static void main(String[] args) {
// HashSet常用API
testHashSetAPIs() ;
}
/*
* HashSet除了iterator()和add()之外的其它常用API
*/
private static void testHashSetAPIs() {
// 新建HashSet
HashSet set = new HashSet();
// 将元素添加到Set中
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e");
// 打印HashSet的实际大小
System.out.printf("size :%d\n", set.size());
// 判断HashSet是否包含某个值
System.out.printf("HashSetcontains a :%s\n", set.contains("a"));
System.out.printf("HashSetcontains g :%s\n", set.contains("g"));
// 删除HashSet中的“e”
set.remove("e");
// 将Set转换为数组
String[] arr =(String[])set.toArray(new String[0]);
for (String str:arr)
System.out.printf("for each :%s\n", str);
// 新建一个包含b、c、f的HashSet
HashSet otherset = new HashSet();
otherset.add("b");
otherset.add("c");
otherset.add("f");
// 克隆一个removeset,内容和set一模一样
HashSet removeset =(HashSet)set.clone();
// 删除“removeset中,属于otherSet的元素”
removeset.removeAll(otherset);
// 打印removeset
System.out.printf("removeset :%s\n", removeset);
// 克隆一个retainset,内容和set一模一样
HashSet retainset =(HashSet)set.clone();
// 保留“retainset中,属于otherSet的元素”
retainset.retainAll(otherset);
// 打印retainset
System.out.printf("retainset :%s\n", retainset);
// 遍历HashSet
for(Iterator iterator = set.iterator();
iterator.hasNext(); )
System.out.printf("iterator :%s\n", iterator.next());
// 清空HashSet
set.clear();
// 输出HashSet是否为空
System.out.printf("%s\n",set.isEmpty()?"set is empty":"set is not empty");}}
九、 TreeSet类
1) 概要
这一章,我们对TreeSet进行学习。
我们先对TreeSet有个整体认识,然后再学习它的源码,最后再通过实例来学会使用TreeSet。内容包括:
第1部分 TreeSet介绍
第2部分 TreeSet数据结构
第3部分 TreeSet源码解析(基于JDK1.6.0_45)
第4部分 TreeSet遍历方式
第5部分 TreeSet示例
2) TreeSet介绍
TreeSet简介
TreeSet 是一个有序的集合,它的作用是提供有序的Set集合。它继承于AbstractSet抽象类,实现了NavigableSet<E>,Cloneable, java.io.Serializable接口。
TreeSet 继承于AbstractSet,所以它是一个Set集合,具有Set的属性和方法。
TreeSet 实现了NavigableSet接口,意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。
TreeSet 实现了Cloneable接口,意味着它能被克隆。
TreeSet 实现了java.io.Serializable接口,意味着它支持序列化。
TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
TreeSet为基本操作(add、remove 和 contains)提供受保证的 log(n) 时间开销。
另外,TreeSet是非同步的。它的iterator 方法返回的迭代器是fail-fast的。
TreeSet的构造函数
// 默认构造函数。使用该构造函数,TreeSet中的元素按照自然排序进行排列。
TreeSet()
// 创建的TreeSet包含collection
TreeSet(Collection<?extends E> collection)
// 指定TreeSet的比较器
TreeSet(Comparator<?super E> comparator)
// 创建的TreeSet包含set
TreeSet(SortedSet<E>set)
TreeSet的API
boolean add(E object)
boolean addAll(Collection<?extends E> collection)
void clear()
Object clone()
boolean contains(Object object)
E first()
boolean isEmpty()
E last()
E pollFirst()
E pollLast()
E lower(E e)
E floor(E e)
E ceiling(E e)
E higher(E e)
boolean remove(Object object)
int size()
Comparator<?super E> comparator()
Iterator<E> iterator()
Iterator<E> descendingIterator()
SortedSet<E> headSet(E end)
NavigableSet<E> descendingSet()
NavigableSet<E> headSet(E end, boolean endInclusive)
SortedSet<E> subSet(E start, E end)
NavigableSet<E> subSet(E start, boolean startInclusive,E end, boolean endInclusive)
NavigableSet<E> tailSet(E start, booleanstartInclusive)
SortedSet<E> tailSet(E start)
说明:
(01) TreeSet是有序的Set集合,因此支持add、remove、get等方法。
(02) 和NavigableSet一样,TreeSet的导航方法大致可以区分为两类,一类时提供元素项的导航方法,返回某个元素;另一类时提供集合的导航方法,返回某个集合。
lower、floor、ceiling 和 higher 分别返回小于、小于等于、大于等于、大于给定元素的元素,如果不存在这样的元素,则返回 null。
3) TreeSet数据结构
TreeSet的继承关系
java.lang.Object
java.util.AbstractCollection<E>
java.util.AbstractSet<E>
java.util.TreeSet<E>
public classTreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>,Cloneable, java.io.Serializable{}
TreeSet与Collection关系可以看出:
(01) TreeSet继承于AbstractSet,并且实现了NavigableSet接口。
(02) TreeSet的本质是一个"有序的,并且没有重复元素"的集合,它是通过TreeMap实现的。TreeSet中含有一个"NavigableMap类型的成员变量"m,而m实际上是"TreeMap的实例"。
4) TreeSet源码解析
为了更了解TreeSet的原理,下面对TreeSet源码代码作出分析。
总结:
(01) TreeSet实际上是TreeMap实现的。当我们构造TreeSet时;若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
(02) TreeSet是非线程安全的。
(03) TreeSet实现java.io.Serializable的方式。当写入到输出流时,依次写入“比较器、容量、全部元素”;当读出输入流时,再依次读取。
5) TreeSet遍历方式
4.1 Iterator顺序遍历
for(Iterator iter= set.iterator(); iter.hasNext(); ) {
iter.next();
}
4.2 Iterator顺序遍历
// 假设set是TreeSet对象
for(Iterator iter= set.descendingIterator(); iter.hasNext(); ) {
iter.next();
}
4.3 for-each遍历HashSet
// 假设set是TreeSet对象,并且set中元素是String类型
String[] arr = (String[])set.toArray(newString[0]);
for (Stringstr:arr)
System.out.printf("for each :%s\n", str);
TreeSet不支持快速随机遍历,只能通过迭代器进行遍历!
6) TreeSet示例
importjava.util.*;
/**
* @desc TreeSet的API测试
*
* @author skywang
* @email kuiwu-wang@163.com
*/
public classTreeSetTest {
public static void main(String[] args) {
testTreeSetAPIs();
}
// 测试TreeSet的api
public static void testTreeSetAPIs() {
String val;
// 新建TreeSet
TreeSet tSet = new TreeSet();
// 将元素添加到TreeSet中
tSet.add("aaa");
// Set中不允许重复元素,所以只会保存一个“aaa”
tSet.add("aaa");
tSet.add("bbb");
tSet.add("eee");
tSet.add("ddd");
tSet.add("ccc");
System.out.println("TreeSet:"+tSet);
// 打印TreeSet的实际大小
System.out.printf("size :%d\n", tSet.size());
// 导航方法
// floor(小于、等于)
System.out.printf("floor bbb:%s\n", tSet.floor("bbb"));
// lower(小于)
System.out.printf("lower bbb:%s\n", tSet.lower("bbb"));
// ceiling(大于、等于)
System.out.printf("ceiling bbb:%s\n", tSet.ceiling("bbb"));
System.out.printf("ceiling eee:%s\n", tSet.ceiling("eee"));
// ceiling(大于)
System.out.printf("higher bbb:%s\n", tSet.higher("bbb"));
// subSet()
System.out.printf("subSet(aaa,true, ccc, true): %s\n", tSet.subSet("aaa", true,"ccc", true));
System.out.printf("subSet(aaa,true, ccc, false): %s\n", tSet.subSet("aaa", true,"ccc", false));
System.out.printf("subSet(aaa,false, ccc, true): %s\n", tSet.subSet("aaa", false,"ccc", true));
System.out.printf("subSet(aaa,false, ccc, false): %s\n", tSet.subSet("aaa", false,"ccc", false));
// headSet()
System.out.printf("headSet(ccc,true): %s\n", tSet.headSet("ccc", true));
System.out.printf("headSet(ccc,false): %s\n", tSet.headSet("ccc", false));
// tailSet()
System.out.printf("tailSet(ccc,true): %s\n", tSet.tailSet("ccc", true));
System.out.printf("tailSet(ccc,false): %s\n", tSet.tailSet("ccc", false));
// 删除“ccc”
tSet.remove("ccc");
// 将Set转换为数组
String[] arr =(String[])tSet.toArray(new String[0]);
for (String str:arr)
System.out.printf("for each :%s\n", str);
// 打印TreeSet
System.out.printf("TreeSet:%s\n", tSet);
// 遍历TreeSet
for(Iterator iter = tSet.iterator();iter.hasNext(); ) {
System.out.printf("iter :%s\n", iter.next());
}
// 删除并返回第一个元素
val = (String)tSet.pollFirst();
System.out.printf("pollFirst=%s,set=%s\n", val, tSet);
// 删除并返回最后一个元素
val = (String)tSet.pollLast();
System.out.printf("pollLast=%s,set=%s\n", val, tSet);
// 清空HashSet
tSet.clear();
// 输出HashSet是否为空
System.out.printf("%s\n",tSet.isEmpty()?"set is empty":"set is not empty");
}
}
十、 Iterator和Enumeration进行比较
1) 概要
这一章,我们对Iterator和Enumeration进行比较学习。内容包括:
第2部分 Iterator和Enumeration实例
2) Iterator和Enumeration区别
在Java集合中,我们通常都通过“Iterator(迭代器)” 或 “Enumeration(枚举类)” 去遍历集合。今天,我们就一起学习一下它们之间到底有什么区别。
我们先看看 Enumeration.java 和 Iterator.java的源码,再说它们的区别。
Enumeration是一个接口,它的源码如下:
package java.util;
public interfaceEnumeration<E> {
boolean hasMoreElements();
E nextElement();
}
Iterator也是一个接口,它的源码如下:
package java.util;
public interfaceIterator<E> {
boolean hasNext();
E next();
void remove();
}
看完代码了,我们再来说说它们之间的区别。
(01) 函数接口不同
Enumeration只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。
Iterator只有3个函数接口。Iterator除了能读取集合的数据之外,也能数据进行删除操作。
(02) Iterator支持fail-fast机制,而Enumeration不支持。
Enumeration 是JDK 1.0添加的接口。使用到它的函数包括Vector、Hashtable等类,这些类都是JDK 1.0中加入的,Enumeration存在的目的就是为它们提供遍历接口。Enumeration本身并没有支持同步,而在Vector、Hashtable实现Enumeration时,添加了同步。
而Iterator 是JDK 1.2才添加的接口,它也是为了HashMap、ArrayList等集合提供遍历接口。Iterator是支持fail-fast机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
3) Iterator和Enumeration实例
下面,我们编写一个Hashtable,然后分别通过 Iterator 和 Enumeration 去遍历它,比较它们的效率。代码如下:
importjava.util.Enumeration;
importjava.util.Hashtable;
importjava.util.Iterator;
importjava.util.Map.Entry;
import java.util.Random;
/*
* 测试分别通过 Iterator 和 Enumeration 去遍历Hashtable
* @author skywang
*/
public classIteratorEnumeration {
public static void main(String[] args) {
int val;
Random r = new Random();
Hashtable table = new Hashtable();
for (int i=0; i<100000; i++) {
// 随机获取一个[0,100)之间的数字
val = r.nextInt(100);
table.put(String.valueOf(i), val);
}
// 通过Iterator遍历Hashtable
iterateHashtable(table) ;
// 通过Enumeration遍历Hashtable
enumHashtable(table);
}
/*
* 通过Iterator遍历Hashtable
*/
private static voiditerateHashtable(Hashtable table) {
long startTime =System.currentTimeMillis();
Iterator iter =table.entrySet().iterator();
while(iter.hasNext()) {
//System.out.println("iter:"+iter.next());
iter.next();
}
long endTime =System.currentTimeMillis();
countTime(startTime, endTime);
}
/*
* 通过Enumeration遍历Hashtable
*/
private static void enumHashtable(Hashtabletable) {
long startTime =System.currentTimeMillis();
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
//System.out.println("enu:"+enu.nextElement());
enu.nextElement();
}
long endTime =System.currentTimeMillis();
countTime(startTime, endTime);
}
private static void countTime(long start,long end) {
System.out.println("time:"+(end-start)+"ms");
}
}
运行结果如下:
time: 9ms
time: 5ms
从中,我们可以看出。Enumeration 比 Iterator 的遍历速度更快。为什么呢?
这是因为,Hashtable中Iterator是通过Enumeration去实现的,而且Iterator添加了对fail-fast机制的支持;所以,执行的操作自然要多一些。















 4851
4851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









