







一、 冒泡排序
1) 概要
本章介绍排序算法中的冒泡排序,重点讲解冒泡排序的思想。
目录
1. 冒泡排序介绍
2. 冒泡排序图文说明
3. 冒泡排序的时间复杂度和稳定性
4. 冒泡排序实现
4.1 冒泡排序C实现
4.2 冒泡排序C++实现
4.3 冒泡排序Java实现
2) 冒泡排序介绍
冒泡排序(Bubble Sort),又被称为气泡排序或泡沫排序。
它是一种较简单的排序算法。它会遍历若干次要排序的数列,每次遍历时,它都会从前往后依次的比较相邻两个数的大小;如果前者比后者大,则交换它们的位置。这样,一次遍历之后,最大的元素就在数列的末尾!采用相同的方法再次遍历时,第二大的元素就被排列在最大元素之前。重复此操作,直到整个数列都有序为止!
3) 冒泡排序图文说明
冒泡排序C实现一
void bubble_sort1(int a[], int n)
{
int i,j;
for (i=n-1; i>0; i--)
{
// 将a[0...i]中最大的数据放在末尾
for (j=0; j<i; j++)
{
if (a[j] > a[j+1])
swap(a[j], a[j+1]);
}
}
}
下面以数列{20,40,30,10,60,50}为例,演示它的冒泡排序过程(如下图)。
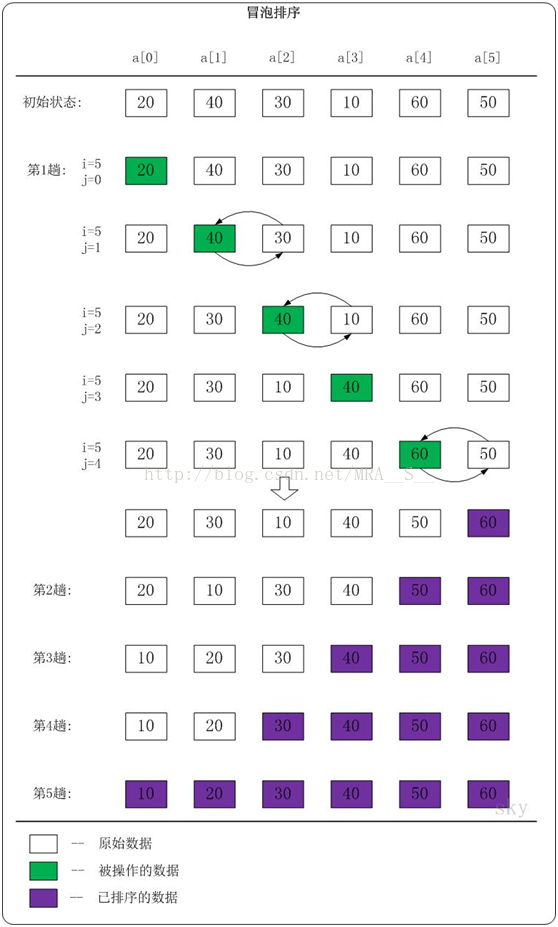
我们先分析第1趟排序
当i=5,j=0时,a[0]<a[1]。此时,不做任何处理!
当i=5,j=1时,a[1]>a[2]。此时,交换a[1]和a[2]的值;交换之后,a[1]=30,a[2]=40。
当i=5,j=2时,a[2]>a[3]。此时,交换a[2]和a[3]的值;交换之后,a[2]=10,a[3]=40。
当i=5,j=3时,a[3]<a[4]。此时,不做任何处理!
当i=5,j=4时,a[4]>a[5]。此时,交换a[4]和a[5]的值;交换之后,a[4]=50,a[3]=60。
于是,第1趟排序完之后,数列{20,40,30,10,60,50}变成了{20,30,10,40,50,60}。此时,数列末尾的值最大。
根据这种方法:
第2趟排序完之后,数列中a[5...6]是有序的。
第3趟排序完之后,数列中a[4...6]是有序的。
第4趟排序完之后,数列中a[3...6]是有序的。
第5趟排序完之后,数列中a[1...6]是有序的。
第5趟排序之后,整个数列也就是有序的了。
冒泡排序C实现二
观察上面冒泡排序的流程图,第3趟排序之后,数据已经是有序的了;第4趟和第5趟并没有进行数据交换。
下面我们对冒泡排序进行优化,使它效率更高一些:添加一个标记,如果一趟遍历中发生了交换,则标记为true,否则为false。如果某一趟没有发生交换,说明排序已经完成!
void bubble_sort2(int a[], int n)
{
int i,j;
int flag; // 标记
for (i=n-1; i>0; i--)
{
flag = 0; // 初始化标记为0
// 将a[0...i]中最大的数据放在末尾
for (j=0; j<i; j++)
{
if (a[j] > a[j+1])
{
swap(a[j], a[j+1]);
flag = 1; // 若发生交换,则设标记为1
}
}
if (flag==0)
break; // 若没发生交换,则说明数列已有序。
}
}
4) 冒泡排序的时间复杂度和稳定性
冒泡排序时间复杂度
冒泡排序的时间复杂度是O(N2)。
假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢?N-1次!因此,冒泡排序的时间复杂度是O(N2)。
冒泡排序稳定性
冒泡排序是稳定的算法,它满足稳定算法的定义。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
5) 冒泡排序实现
实现代码(BubbleSort.java)
/**
* 冒泡排序:Java
*
*@author skywang
*@date 2014/03/11
*/
public class BubbleSort {
/*
* 冒泡排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void bubbleSort1(int[] a, int n) {
int i,j;
for (i=n-1; i>0; i--) {
// 将a[0...i]中最大的数据放在末尾
for (j=0; j<i; j++) {
if (a[j] > a[j+1]) {
// 交换a[j]和a[j+1]
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
}
}
}
}
/*
* 冒泡排序(改进版)
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void bubbleSort2(int[] a, int n) {
int i,j;
int flag; // 标记
for (i=n-1; i>0; i--) {
flag = 0; // 初始化标记为0
// 将a[0...i]中最大的数据放在末尾
for (j=0; j<i; j++) {
if (a[j] > a[j+1]) {
// 交换a[j]和a[j+1]
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
flag = 1; // 若发生交换,则设标记为1
}
}
if (flag==0)
break; // 若没发生交换,则说明数列已有序。
}
}
public static void main(String[] args) {
int i;
int[] a = {20,40,30,10,60,50};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
bubbleSort1(a, a.length);
//bubbleSort2(a, a.length);
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
上面3种实现的原理和输出结果都是一样的。下面是它们的输出结果:
before sort:20 40 30 10 60 50
after sort:10 20 30 40 50 60
二、 快速排序
1) 概要
本章介绍排序算法中的快速排序。
目录
1. 快速排序介绍
2. 快速排序图文说明
3. 快速排序的时间复杂度和稳定性
4. 快速排序实现
4.1 快速排序C实现
4.2 快速排序C++实现
4.3 快速排序Java实现
2) 快速排序介绍
快速排序(Quick Sort)使用分治法策略。
它的基本思想是:选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序流程:
(1) 从数列中挑出一个基准值。
(2) 将所有比基准值小的摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边);在这个分区退出之后,该基准就处于数列的中间位置。
(3) 递归地把"基准值前面的子数列"和"基准值后面的子数列"进行排序。
3) 快速排序图文说明
快速排序代码
/*
* 快速排序
*
* 参数说明:
* a-- 待排序的数组
* l-- 数组的左边界(例如,从起始位置开始排序,则l=0)
* r-- 数组的右边界(例如,排序截至到数组末尾,则r=a.length-1)
*/
void quick_sort(int a[], int l, int r)
{
if (l < r)
{
int i,j,x;
i = l;
j = r;
x = a[i];
while (i < j)
{
while(i < j && a[j] > x)
j--; // 从右向左找第一个小于x的数
if(i < j)
a[i++] = a[j];
while(i < j && a[i] < x)
i++; // 从左向右找第一个大于x的数
if(i < j)
a[j--] = a[i];
}
a[i] = x;
quick_sort(a, l, i-1); /* 递归调用 */
quick_sort(a, i+1, r); /* 递归调用 */
}
}
下面以数列a={30,40,60,10,20,50}为例,演示它的快速排序过程(如下图)。
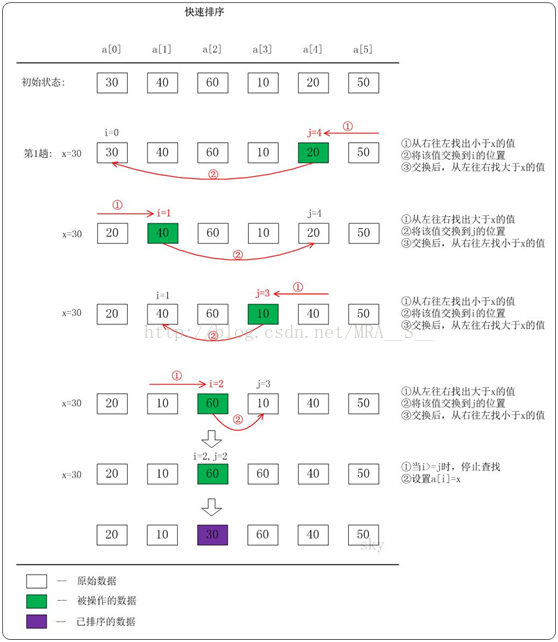
上图只是给出了第1趟快速排序的流程。在第1趟中,设置x=a[i],即x=30。
(01) 从"右 --> 左"查找小于x的数:找到满足条件的数a[j]=20,此时j=4;然后将a[j]赋值a[i],此时i=0;接着从左往右遍历。
(02) 从"左 --> 右"查找大于x的数:找到满足条件的数a[i]=40,此时i=1;然后将a[i]赋值a[j],此时j=4;接着从右往左遍历。
(03) 从"右 --> 左"查找小于x的数:找到满足条件的数a[j]=10,此时j=3;然后将a[j]赋值a[i],此时i=1;接着从左往右遍历。
(04) 从"左 --> 右"查找大于x的数:找到满足条件的数a[i]=60,此时i=2;然后将a[i]赋值a[j],此时j=3;接着从右往左遍历。
(05) 从"右 --> 左"查找小于x的数:没有找到满足条件的数。当i>=j时,停止查找;然后将x赋值给a[i]。此趟遍历结束!
按照同样的方法,对子数列进行递归遍历。最后得到有序数组!
4) 快速排序的时间复杂度和稳定性
快速排序稳定性
快速排序是不稳定的算法,它不满足稳定算法的定义。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
快速排序时间复杂度
快速排序的时间复杂度在最坏情况下是O(N2),平均的时间复杂度是O(N*lgN)。
这句话很好理解:假设被排序的数列中有N个数。遍历一次的时间复杂度是O(N),需要遍历多少次呢?至少lg(N+1)次,最多N次。
(01) 为什么最少是lg(N+1)次?快速排序是采用的分治法进行遍历的,我们将它看作一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的定义,它的深度至少是lg(N+1)。因此,快速排序的遍历次数最少是lg(N+1)次。
(02) 为什么最多是N次?这个应该非常简单,还是将快速排序看作一棵二叉树,它的深度最大是N。因此,快读排序的遍历次数最多是N次。
5) 快速排序实现
实现代码(QuickSort.java)
/**
* 快速排序:Java
*
*@author skywang
*@date 2014/03/11
*/
public class QuickSort {
/*
* 快速排序
*
* 参数说明:
* a -- 待排序的数组
* l -- 数组的左边界(例如,从起始位置开始排序,则l=0)
* r -- 数组的右边界(例如,排序截至到数组末尾,则r=a.length-1)
*/
public static void quickSort(int[] a, int l, int r) {
if (l < r) {
int i,j,x;
i = l;
j = r;
x = a[i];
while (i < j) {
while(i < j && a[j]> x)
j--; // 从右向左找第一个小于x的数
if(i < j)
a[i++] = a[j];
while(i < j && a[i]< x)
i++; // 从左向右找第一个大于x的数
if(i < j)
a[j--] = a[i];
}
a[i] = x;
quickSort(a, l, i-1); /* 递归调用 */
quickSort(a, i+1, r); /* 递归调用 */
}
}
public static void main(String[] args) {
int i;
int a[] = {30,40,60,10,20,50};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
quickSort(a, 0, a.length-1);
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
上面实现原理和输出结果都是一样的。下面是它们的输出结果:
before sort:30 40 60 10 20 50
after sort:10 20 30 40 50 60
三、 直接插入排序
1) 概要
本章介绍排序算法中的直接插入排序。内容包括:
1. 直接插入排序介绍
2. 直接插入排序图文说明
3. 直接插入排序的时间复杂度和稳定性
4. 直接插入排序实现
4.1 直接插入排序C实现
4.2 直接插入排序C++实现
4.3 直接插入排序Java实现
2) 直接插入排序介绍
直接插入排序(Straight Insertion Sort)的基本思想是:把n个待排序的元素看成为一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
3) 直接插入排序图文说明
直接插入排序代码
/*
* 直接插入排序
*
* 参数说明:
* a-- 待排序的数组
* n-- 数组的长度
*/
void insert_sort(int a[], int n)
{
int i, j, k;
for (i = 1; i < n; i++)
{
//为a[i]在前面的a[0...i-1]有序区间中找一个合适的位置
for (j = i - 1; j >= 0; j--)
if (a[j] < a[i])
break;
//如找到了一个合适的位置
if (j != i - 1)
{
//将比a[i]大的数据向后移
int temp = a[i];
for (k = i - 1; k > j; k--)
a[k + 1] = a[k];
//将a[i]放到正确位置上
a[k + 1] = temp;
}
}
}
下面选取直接插入排序的一个中间过程对其进行说明。假设{20,30,40,10,60,50}中的前3个数已经排列过,是有序的了;接下来对10进行排列。示意图如下:
图中将数列分为有序区和无序区。我们需要做的工作只有两个:(1)取出无序区中的第1个数,并找出它在有序区对应的位置。(2)将无序区的数据插入到有序区;若有必要的话,则对有序区中的相关数据进行移位。
4) 直接插入排序的时间复杂度和稳定性
直接插入排序时间复杂度
直接插入排序的时间复杂度是O(N2)。
假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢?N-1!因此,直接插入排序的时间复杂度是O(N2)。
直接插入排序稳定性
直接插入排序是稳定的算法,它满足稳定算法的定义。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
5) 直接插入排序实现
实现代码(InsertSort.java)
/**
* 直接插入排序:Java
*
*@author skywang
*@date 2014/03/11
*/
public class InsertSort {
/*
* 直接插入排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void insertSort(int[] a, int n) {
int i, j, k;
for (i = 1; i < n; i++) {
//为a[i]在前面的a[0...i-1]有序区间中找一个合适的位置
for (j = i - 1; j >= 0; j--)
if (a[j] < a[i])
break;
//如找到了一个合适的位置
if (j != i - 1) {
//将比a[i]大的数据向后移
int temp = a[i];
for (k = i - 1; k > j; k--)
a[k + 1] = a[k];
//将a[i]放到正确位置上
a[k + 1] = temp;
}
}
}
public static void main(String[] args) {
int i;
int[] a = {20,40,30,10,60,50};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ",a[i]);
System.out.printf("\n");
insertSort(a, a.length);
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
上面3种实现的原理和输出结果都是一样的。下面是它们的输出结果:
before sort:20 40 30 10 60 50
after sort:10 20 30 40 50 60
四、 希尔排序
1) 概要
本章介绍排序算法中的希尔排序。内容包括:
1. 希尔排序介绍
2. 希尔排序图文说明
3. 希尔排序的时间复杂度和稳定性
4. 希尔排序实现
4.1 希尔排序C实现
4.2 希尔排序C++实现
4.3 希尔排序Java实现
2) 希尔排序介绍
希尔排序(Shell Sort)是插入排序的一种,它是针对直接插入排序算法的改进。该方法又称缩小增量排序,因DL.Shell于1959年提出而得名。
希尔排序实质上是一种分组插入方法。它的基本思想是:对于n个待排序的数列,取一个小于n的整数gap(gap被称为步长)将待排序元素分成若干个组子序列,所有距离为gap的倍数的记录放在同一个组中;然后,对各组内的元素进行直接插入排序。 这一趟排序完成之后,每一个组的元素都是有序的。然后减小gap的值,并重复执行上述的分组和排序。重复这样的操作,当gap=1时,整个数列就是有序的。
3) 希尔排序图文说明
希尔排序代码(一)
/*
* 希尔排序
*
* 参数说明:
* a-- 待排序的数组
* n-- 数组的长度
*/
void shell_sort1(int a[], int n)
{
int i,j,gap;
// gap为步长,每次减为原来的一半。
for (gap = n / 2; gap > 0; gap /= 2)
{
// 共gap个组,对每一组都执行直接插入排序
for (i = 0 ;i < gap; i++)
{
for (j = i + gap; j < n; j += gap)
{
// 如果a[j]< a[j-gap],则寻找a[j]位置,并将后面数据的位置都后移。
if (a[j] < a[j - gap])
{
int tmp = a[j];
int k = j - gap;
while (k >= 0 &&a[k] > tmp)
{
a[k + gap] = a[k];
k -= gap;
}
a[k + gap] = tmp;
}
}
}
}
}
在上面的希尔排序中,首先要选取步长gap的值。选取了gap之后,就将数列分成了gap个组,对于每一个组都执行直接插入排序。在排序完所有的组之后,将gap的值减半;继续对数列进行分组,然后进行排序。重复这样的操作,直到gap<0为止。此时,数列也就是有序的了。
为了便于观察,我们将希尔排序中的直接插入排序独立出来,得到代码(二)。
希尔排序代码(二)
/*
* 对希尔排序中的单个组进行排序
*
* 参数说明:
* a-- 待排序的数组
* n-- 数组总的长度
* i-- 组的起始位置
* gap -- 组的步长
*
* 组是"从i开始,将相隔gap长度的数都取出"所组成的!
*/
void group_sort(int a[], int n, int i,intgap)
{
int j;
for (j = i + gap; j < n; j += gap)
{
// 如果a[j] < a[j-gap],则寻找a[j]位置,并将后面数据的位置都后移。
if (a[j] < a[j - gap])
{
int tmp = a[j];
int k = j - gap;
while (k >= 0 && a[k] > tmp)
{
a[k + gap] = a[k];
k -= gap;
}
a[k + gap] = tmp;
}
}
}
/*
* 希尔排序
*
* 参数说明:
* a-- 待排序的数组
* n-- 数组的长度
*/
void shell_sort2(int a[], int n)
{
int i,gap;
// gap为步长,每次减为原来的一半。
for (gap = n / 2; gap > 0; gap /= 2)
{
// 共gap个组,对每一组都执行直接插入排序
for (i = 0 ;i < gap; i++)
group_sort(a, n, i, gap);
}
}
4) 演示希尔排序过程
下面以数列{80,30,60,40,20,10,50,70}为例,演示它的希尔排序过程。
第1趟:(gap=4)
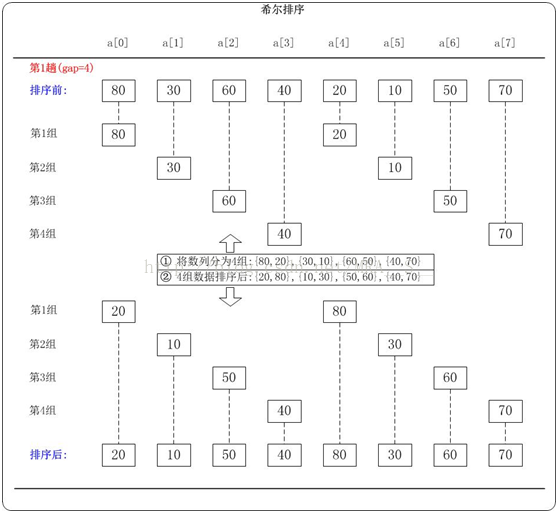
当gap=4时,意味着将数列分为4个组: {80,20},{30,10},{60,50},{40,70}。对应数列: {80,30,60,40,20,10,50,70}
对这4个组分别进行排序,排序结果:{20,80},{10,30},{50,60},{40,70}。 对应数列:{20,10,50,40,80,30,60,70}
第2趟:(gap=2)

当gap=2时,意味着将数列分为2个组:{20,50,80,60}, {10,40,30,70}。 对应数列: {20,10,50,40,80,30,60,70}
注意:{20,50,80,60}实际上有两个有序的数列{20,80}和{50,60}组成。
{10,40,30,70}实际上有两个有序的数列{10,30}和{40,70}组成。
对这2个组分别进行排序,排序结果:{20,50,60,80},{10,30,40,70}。 对应数列: {20,10,50,30,60,40,80,70}
第3趟:(gap=1)
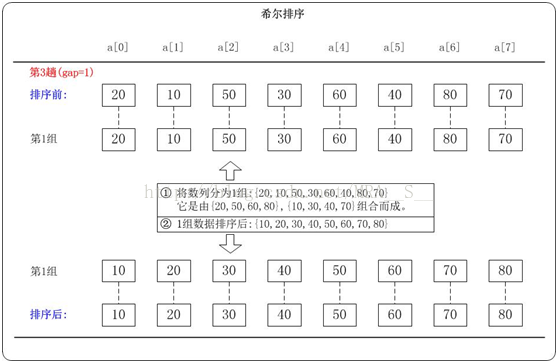
当gap=1时,意味着将数列分为1个组:{20,10,50,30,60,40,80,70}
注意:{20,10,50,30,60,40,80,70}实际上有两个有序的数列{20,50,60,80}和{10,30,40,70}组成。
对这1个组分别进行排序,排序结果:{10,20,30,40,50,60,70,80}
5) 希尔排序的时间复杂度和稳定性
希尔排序时间复杂度
希尔排序的时间复杂度与增量(即,步长gap)的选取有关。例如,当增量为1时,希尔排序退化成了直接插入排序,此时的时间复杂度为O(N2),而Hibbard增量的希尔排序的时间复杂度为O(N3/2)。
希尔排序稳定性
希尔排序是不稳定的算法,它满足稳定算法的定义。对于相同的两个数,可能由于分在不同的组中而导致它们的顺序发生变化。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
6) 希尔排序实现
实现代码(ShellSort.java)
/**
* 希尔排序:Java
*
*@author skywang
*@date 2014/03/11
*/
public class ShellSort {
/**
* 希尔排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void shellSort1(int[] a, int n) {
// gap为步长,每次减为原来的一半。
for (int gap = n / 2; gap > 0; gap /= 2) {
// 共gap个组,对每一组都执行直接插入排序
for (int i = 0 ;i < gap; i++) {
for (int j = i + gap; j < n;j += gap) {
// 如果a[j] < a[j-gap],则寻找a[j]位置,并将后面数据的位置都后移。
if (a[j] < a[j - gap]) {
int tmp = a[j];
int k = j - gap;
while (k >= 0&& a[k] > tmp) {
a[k + gap] = a[k];
k -= gap;
}
a[k + gap] = tmp;
}
}
}
}
}
/**
* 对希尔排序中的单个组进行排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组总的长度
* i -- 组的起始位置
* gap -- 组的步长
*
* 组是"从i开始,将相隔gap长度的数都取出"所组成的!
*/
public static void groupSort(int[] a, int n, int i,int gap) {
for (int j = i + gap; j < n; j += gap) {
// 如果a[j] < a[j-gap],则寻找a[j]位置,并将后面数据的位置都后移。
if (a[j] < a[j - gap]) {
int tmp = a[j];
int k = j - gap;
while (k >= 0 &&a[k] > tmp) {
a[k + gap] = a[k];
k -= gap;
}
a[k + gap] = tmp;
}
}
}
/**
* 希尔排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void shellSort2(int[] a, int n) {
// gap为步长,每次减为原来的一半。
for (int gap = n / 2; gap > 0; gap /= 2) {
// 共gap个组,对每一组都执行直接插入排序
for (int i = 0 ;i < gap; i++)
groupSort(a, n, i, gap);
}
}
public static void main(String[] args) {
int i;
int a[] = {80,30,60,40,20,10,50,70};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
shellSort1(a, a.length);
//shellSort2(a, a.length);
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
上面实现的原理和输出结果都是一样的。下面是它们的输出结果:
before sort:80 30 60 40 20 10 50 70
after sort:10 20 30 40 50 60 70 80
五、 选择排序
1) 概要
本章介绍排序算法中的选择排序。
目录
1. 选择排序介绍
2. 选择排序图文说明
3. 选择排序的时间复杂度和稳定性
4. 选择排序实现
4.1 选择排序C实现
4.2 选择排序C++实现
4.3 选择排序Java实现
2) 选择排序介绍
选择排序(Selection sort)是一种简单直观的排序算法。
它的基本思想是:首先在未排序的数列中找到最小(or最大)元素,然后将其存放到数列的起始位置;接着,再从剩余未排序的元素中继续寻找最小(or最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
3) 选择排序图文说明
选择排序代码
/*
* 选择排序
*
* 参数说明:
* a-- 待排序的数组
* n-- 数组的长度
*/
void select_sort(int a[], int n)
{
int i; // 有序区的末尾位置
intj; // 无序区的起始位置
int min; // 无序区中最小元素位置
for(i=0; i<n; i++)
{
min=i;
// 找出"a[i+1] ... a[n]"之间的最小元素,并赋值给min。
for(j=i+1; j<n; j++)
{
if(a[j] < a[min])
min=j;
}
// 若min!=i,则交换 a[i] 和 a[min]。
// 交换之后,保证了a[0] ... a[i] 之间的元素是有序的。
if(min != i)
swap(a[i], a[min]);
}
}
下面以数列{20,40,30,10,60,50}为例,演示它的选择排序过程(如下图)。

排序流程
第1趟:i=0。找出a[1...5]中的最小值a[3]=10,然后将a[0]和a[3]互换。 数列变化:20,40,30,10,60,50-- > 10,40,30,20,60,50
第2趟:i=1。找出a[2...5]中的最小值a[3]=20,然后将a[1]和a[3]互换。 数列变化:10,40,30,20,60,50-- > 10,20,30,40,60,50
第3趟:i=2。找出a[3...5]中的最小值,由于该最小值大于a[2],该趟不做任何处理。
第4趟:i=3。找出a[4...5]中的最小值,由于该最小值大于a[3],该趟不做任何处理。
第5趟:i=4。交换a[4]和a[5]的数据。 数列变化:10,20,30,40,60,50-- > 10,20,30,40,50,60
4) 选择排序的时间复杂度和稳定性
选择排序时间复杂度
选择排序的时间复杂度是O(N2)。
假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢?N-1!因此,选择排序的时间复杂度是O(N2)。
选择排序稳定性
选择排序是稳定的算法,它满足稳定算法的定义。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
5) 选择排序实现
实现代码(SelectSort.java)
/**
* 选择排序:Java
*
*@author skywang
*@date 2014/03/11
*/
public class SelectSort {
/*
* 选择排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void selectSort(int[] a, int n) {
int i; // 有序区的末尾位置
int j; // 无序区的起始位置
int min; // 无序区中最小元素位置
for(i=0; i<n; i++) {
min=i;
// 找出"a[i+1] ... a[n]"之间的最小元素,并赋值给min。
for(j=i+1; j<n; j++) {
if(a[j] < a[min])
min=j;
}
// 若min!=i,则交换 a[i] 和 a[min]。
// 交换之后,保证了a[0] ... a[i] 之间的元素是有序的。
if(min != i) {
int tmp = a[i];
a[i] = a[min];
a[min] = tmp;
}
}
}
public static void main(String[] args) {
int i;
int[] a = {20,40,30,10,60,50};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
selectSort(a, a.length);
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
上面3种实现的原理和输出结果都是一样的。下面是它们的输出结果:
before sort:20 40 30 10 60 50
after sort:10 20 30 40 50 60
六、 堆排序
1) 概要
本章介绍排序算法中的堆排序。
目录
1. 堆排序介绍
2. 堆排序图文说明
3. 堆排序的时间复杂度和稳定性
4. 堆排序实现
4.1 堆排序C实现
4.2 堆排序C++实现
4.3 堆排序Java实现
2) 堆排序介绍
堆排序(Heap Sort)是指利用堆这种数据结构所设计的一种排序算法。
因此,学习堆排序之前,有必要了解堆!若读者不熟悉堆,建议先了解堆(建议可以通过二叉堆,左倾堆,斜堆,二项堆或斐波那契堆等文章进行了解),然后再来学习本章。
我们知道,堆分为"最大堆"和"最小堆"。最大堆通常被用来进行"升序"排序,而最小堆通常被用来进行"降序"排序。
鉴于最大堆和最小堆是对称关系,理解其中一种即可。本文将对最大堆实现的升序排序进行详细说明。
最大堆进行升序排序的基本思想:
① 初始化堆:将数列a[1...n]构造成最大堆。
② 交换数据:将a[1]和a[n]交换,使a[n]是a[1...n]中的最大值;然后将a[1...n-1]重新调整为最大堆。 接着,将a[1]和a[n-1]交换,使a[n-1]是a[1...n-1]中的最大值;然后将a[1...n-2]重新调整为最大值。 依次类推,直到整个数列都是有序的。
下面,通过图文来解析堆排序的实现过程。注意实现中用到了"数组实现的二叉堆的性质"。
在第一个元素的索引为 0 的情形中:
性质一:索引为i的左孩子的索引是(2*i+1);
性质二:索引为i的左孩子的索引是(2*i+2);
性质三:索引为i的父结点的索引是floor((i-1)/2);
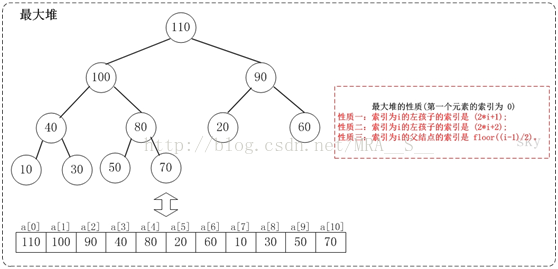
例如,对于最大堆{110,100,90,40,80,20,60,10,30,50,70}而言:索引为0的左孩子的所有是1;索引为0的右孩子是2;索引为8的父节点是3。
3) 堆排序图文说明
堆排序(升序)代码
/*
* (最大)堆的向下调整算法
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
* 其中,N为数组下标索引值,如数组中第1个数对应的N为0。
*
* 参数说明:
* a-- 待排序的数组
* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)
* end -- 截至范围(一般为数组中最后一个元素的索引)
*/
void maxheap_down(int a[], int start, intend)
{
int c = start; // 当前(current)节点的位置
int l = 2*c + 1; // 左(left)孩子的位置
int tmp = a[c]; // 当前(current)节点的大小
for (; l <= end; c=l,l=2*l+1)
{
// "l"是左孩子,"l+1"是右孩子
if ( l < end && a[l] < a[l+1])
l++; // 左右两孩子中选择较大者,即m_heap[l+1]
if (tmp >= a[l])
break; // 调整结束
else // 交换值
{
a[c] = a[l];
a[l]= tmp;
}
}
}
/*
* 堆排序(从小到大)
*
* 参数说明:
* a-- 待排序的数组
* n-- 数组的长度
*/
void heap_sort_asc(int a[], int n)
{
int i;
// 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆。
for (i = n / 2 - 1; i >= 0; i--)
maxheap_down(a, i, n-1);
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for (i = n - 1; i > 0; i--)
{
// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最大的。
swap(a[0], a[i]);
// 调整a[0...i-1],使得a[0...i-1]仍然是一个最大堆。
// 即,保证a[i-1]是a[0...i-1]中的最大值。
maxheap_down(a, 0, i-1);
}
}
heap_sort_asc(a, n)的作用是:对数组a进行升序排序;其中,a是数组,n是数组长度。
heap_sort_asc(a, n)的操作分为两部分:初始化堆 和 交换数据。
maxheap_down(a, start, end)是最大堆的向下调整算法。
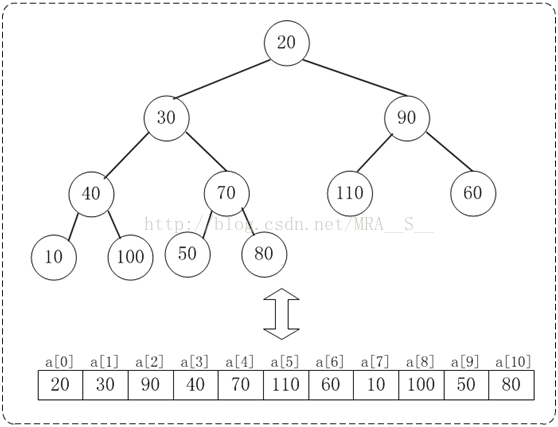
下面演示heap_sort_asc(a, n)对a={20,30,90,40,70,110,60,10,100,50,80}, n=11进行堆排序过程。下面是数组a对应的初始化结构:
1 初始化堆
在堆排序算法中,首先要将待排序的数组转化成二叉堆。
下面演示将数组{20,30,90,40,70,110,60,10,100,50,80}转换为最大堆{110,100,90,40,80,20,60,10,30,50,70}的步骤。
1.1 i=11/2-1,即i=4
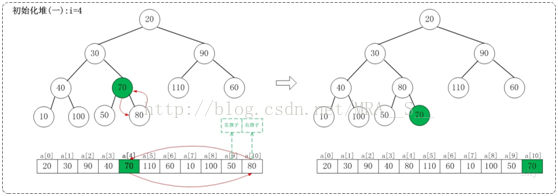
上面是maxheap_down(a, 4, 9)调整过程。maxheap_down(a, 4, 9)的作用是将a[4...9]进行下调;a[4]的左孩子是a[9],右孩子是a[10]。调整时,选择左右孩子中较大的一个(即a[10])和a[4]交换。
1.2 i=3
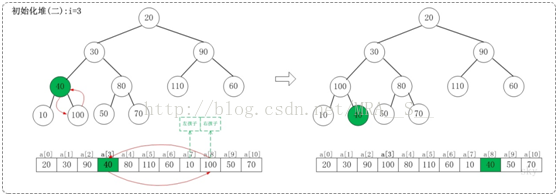
上面是maxheap_down(a, 3, 9)调整过程。maxheap_down(a, 3, 9)的作用是将a[3...9]进行下调;a[3]的左孩子是a[7],右孩子是a[8]。调整时,选择左右孩子中较大的一个(即a[8])和a[4]交换。
1.3 i=2
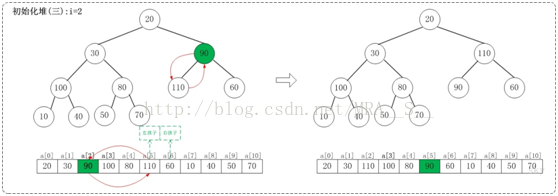
上面是maxheap_down(a, 2, 9)调整过程。maxheap_down(a, 2, 9)的作用是将a[2...9]进行下调;a[2]的左孩子是a[5],右孩子是a[6]。调整时,选择左右孩子中较大的一个(即a[5])和a[2]交换。
1.4 i=1
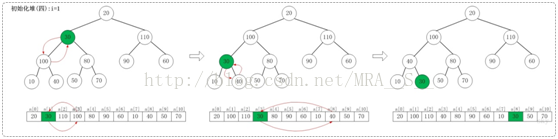
上面是maxheap_down(a, 1, 9)调整过程。maxheap_down(a, 1, 9)的作用是将a[1...9]进行下调;a[1]的左孩子是a[3],右孩子是a[4]。调整时,选择左右孩子中较大的一个(即a[3])和a[1]交换。交换之后,a[3]为30,它比它的右孩子a[8]要大,接着,再将它们交换。
1.5 i=0
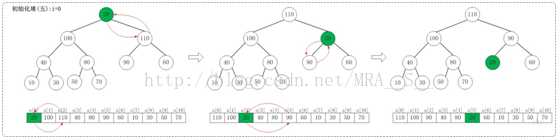
上面是maxheap_down(a, 0, 9)调整过程。maxheap_down(a, 0, 9)的作用是将a[0...9]进行下调;a[0]的左孩子是a[1],右孩子是a[2]。调整时,选择左右孩子中较大的一个(即a[2])和a[0]交换。交换之后,a[2]为20,它比它的左右孩子要大,选择较大的孩子(即左孩子)和a[2]交换。
调整完毕,就得到了最大堆。此时,数组{20,30,90,40,70,110,60,10,100,50,80}也就变成了{110,100,90,40,80,20,60,10,30,50,70}。
第2部分 交换数据
在将数组转换成最大堆之后,接着要进行交换数据,从而使数组成为一个真正的有序数组。
交换数据部分相对比较简单,下面仅仅给出将最大值放在数组末尾的示意图。
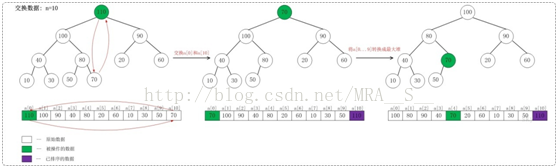
上面是当n=10时,交换数据的示意图。
当n=10时,首先交换a[0]和a[10],使得a[10]是a[0...10]之间的最大值;然后,调整a[0...9]使它称为最大堆。交换之后:a[10]是有序的!
当n=9时, 首先交换a[0]和a[9],使得a[9]是a[0...9]之间的最大值;然后,调整a[0...8]使它称为最大堆。交换之后:a[9...10]是有序的!
...
依此类推,直到a[0...10]是有序的。
4) 堆排序的时间复杂度和稳定性
堆排序时间复杂度
堆排序的时间复杂度是O(N*lgN)。
假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢?
堆排序是采用的二叉堆进行排序的,二叉堆就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的定义,它的深度至少是lg(N+1)。最多是多少呢?由于二叉堆是完全二叉树,因此,它的深度最多也不会超过lg(2N)。因此,遍历一趟的时间复杂度是O(N),而遍历次数介于lg(N+1)和lg(2N)之间;因此得出它的时间复杂度是O(N*lgN)。
堆排序稳定性
堆排序是不稳定的算法,它不满足稳定算法的定义。它在交换数据的时候,是比较父结点和子节点之间的数据,所以,即便是存在两个数值相等的兄弟节点,它们的相对顺序在排序也可能发生变化。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
堆排序实现
这实现的原理和输出结果都是一样的,每一种实现中都包括了"最大堆对应的升序排列"和"最小堆对应的降序排序"。
5) 实现代码(HeapSort.java)
/**
* 堆排序:Java
*
*@author skywang
*@date 2014/03/11
*/
public class HeapSort {
/*
* (最大)堆的向下调整算法
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
* 其中,N为数组下标索引值,如数组中第1个数对应的N为0。
*
* 参数说明:
* a -- 待排序的数组
* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)
* end -- 截至范围(一般为数组中最后一个元素的索引)
*/
public static void maxHeapDown(int[] a, int start, int end) {
int c = start; // 当前(current)节点的位置
int l = 2*c + 1; // 左(left)孩子的位置
int tmp = a[c]; // 当前(current)节点的大小
for (; l <= end; c=l,l=2*l+1) {
// "l"是左孩子,"l+1"是右孩子
if ( l < end && a[l] < a[l+1])
l++; // 左右两孩子中选择较大者,即m_heap[l+1]
if (tmp >= a[l])
break; // 调整结束
else { // 交换值
a[c] = a[l];
a[l]= tmp;
}
}
}
/*
* 堆排序(从小到大)
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void heapSortAsc(int[] a, int n) {
int i,tmp;
// 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆。
for (i = n / 2 - 1; i >= 0; i--)
maxHeapDown(a, i, n-1);
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for (i = n - 1; i > 0; i--) {
// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最大的。
tmp = a[0];
a[0] = a[i];
a[i] = tmp;
// 调整a[0...i-1],使得a[0...i-1]仍然是一个最大堆。
// 即,保证a[i-1]是a[0...i-1]中的最大值。
maxHeapDown(a, 0, i-1);
}
}
/*
* (最小)堆的向下调整算法
*
* 注:数组实现的堆中,第N个节点的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
* 其中,N为数组下标索引值,如数组中第1个数对应的N为0。
*
* 参数说明:
* a -- 待排序的数组
* start -- 被下调节点的起始位置(一般为0,表示从第1个开始)
* end -- 截至范围(一般为数组中最后一个元素的索引)
*/
public static void minHeapDown(int[] a, int start, int end) {
int c = start; // 当前(current)节点的位置
int l = 2*c + 1; // 左(left)孩子的位置
int tmp = a[c]; // 当前(current)节点的大小
for (; l <= end; c=l,l=2*l+1) {
// "l"是左孩子,"l+1"是右孩子
if ( l < end && a[l] > a[l+1])
l++; // 左右两孩子中选择较小者
if (tmp <= a[l])
break; // 调整结束
else { // 交换值
a[c] = a[l];
a[l]= tmp;
}
}
}
/*
* 堆排序(从大到小)
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void heapSortDesc(int[] a, int n) {
int i,tmp;
// 从(n/2-1) --> 0逐次遍历每。遍历之后,得到的数组实际上是一个最小堆。
for (i = n / 2 - 1; i >= 0; i--)
minHeapDown(a, i, n-1);
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for (i = n - 1; i > 0; i--) {
// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最小的。
tmp = a[0];
a[0] = a[i];
a[i] = tmp;
// 调整a[0...i-1],使得a[0...i-1]仍然是一个最小堆。
// 即,保证a[i-1]是a[0...i-1]中的最小值。
minHeapDown(a, 0, i-1);
}
}
public static void main(String[] args) {
int i;
int a[] = {20,30,90,40,70,110,60,10,100,50,80};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
heapSortAsc(a, a.length); // 升序排列
//heapSortDesc(a, a.length); // 降序排列
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
它们的输出结果:
before sort:20 30 90 40 70 110 60 10 100 5080
after sort:10 20 30 40 50 60 70 80 90 100 110
七、 归并排序
1) 概要
本章介绍排序算法中的归并排序。内容包括:
1. 归并排序介绍
2. 归并排序图文说明
3. 归并排序的时间复杂度和稳定性
4. 归并排序实现
归并排序介绍
将两个的有序数列合并成一个有序数列,我们称之为"归并"。
归并排序(Merge Sort)就是利用归并思想对数列进行排序。根据具体的实现,归并排序包括"从上往下"和"从下往上"2种方式。
1. 从下往上的归并排序:将待排序的数列分成若干个长度为1的子数列,然后将这些数列两两合并;得到若干个长度为2的有序数列,再将这些数列两两合并;得到若干个长度为4的有序数列,再将它们两两合并;直接合并成一个数列为止。这样就得到了我们想要的排序结果。(参考下面的图片)
2. 从上往下的归并排序:它与"从下往上"在排序上是反方向的。它基本包括3步:
① 分解 -- 将当前区间一分为二,即求分裂点 mid = (low + high)/2;
② 求解 -- 递归地对两个子区间a[low...mid]和 a[mid+1...high]进行归并排序。递归的终结条件是子区间长度为1。
③ 合并 -- 将已排序的两个子区间a[low...mid]和 a[mid+1...high]归并为一个有序的区间a[low...high]。
下面的图片很清晰的反映了"从下往上"和"从上往下"的归并排序的区别。
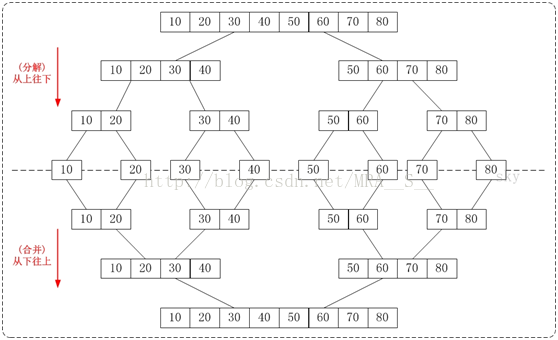
2) 归并排序图文说明
归并排序(从上往下)代码
/*
* 将一个数组中的两个相邻有序区间合并成一个
*
* 参数说明:
* a-- 包含两个有序区间的数组
* start -- 第1个有序区间的起始地址。
* mid -- 第1个有序区间的结束地址。也是第2个有序区间的起始地址。
* end -- 第2个有序区间的结束地址。
*/
void merge(int a[], int start, int mid, intend)
{
int *tmp = (int *)malloc((end-start+1)*sizeof(int)); // tmp是汇总2个有序区的临时区域
int i = start; // 第1个有序区的索引
int j = mid + 1; // 第2个有序区的索引
int k = 0; // 临时区域的索引
while(i <= mid && j <= end)
{
if (a[i] <= a[j])
tmp[k++] = a[i++];
else
tmp[k++] = a[j++];
}
while(i <= mid)
tmp[k++] = a[i++];
while(j <= end)
tmp[k++] = a[j++];
// 将排序后的元素,全部都整合到数组a中。
for (i = 0; i < k; i++)
a[start + i] = tmp[i];
free(tmp);
}
/*
* 归并排序(从上往下)
*
* 参数说明:
* a-- 待排序的数组
* start -- 数组的起始地址
* endi -- 数组的结束地址
*/
void merge_sort_up2down(int a[], int start,int end)
{
if(a==NULL || start >= end)
return ;
int mid = (end + start)/2;
merge_sort_up2down(a, start, mid); // 递归排序a[start...mid]
merge_sort_up2down(a, mid+1, end); // 递归排序a[mid+1...end]
// a[start...mid] 和 a[mid...end]是两个有序空间,
// 将它们排序成一个有序空间a[start...end]
merge(a, start, mid, end);
}
从上往下的归并排序采用了递归的方式实现。它的原理非常简单,如下图:
通过"从上往下的归并排序"来对数组{80,30,60,40,20,10,50,70}进行排序时:
1. 将数组{80,30,60,40,20,10,50,70}看作由两个有序的子数组{80,30,60,40}和{20,10,50,70}组成。对两个有序子树组进行排序即可。
2. 将子数组{80,30,60,40}看作由两个有序的子数组{80,30}和{60,40}组成。
将子数组{20,10,50,70}看作由两个有序的子数组{20,10}和{50,70}组成。
3. 将子数组{80,30}看作由两个有序的子数组{80}和{30}组成。
将子数组{60,40}看作由两个有序的子数组{60}和{40}组成。
将子数组{20,10}看作由两个有序的子数组{20}和{10}组成。
将子数组{50,70}看作由两个有序的子数组{50}和{70}组成。
归并排序(从下往上)代码
/*
* 对数组a做若干次合并:数组a的总长度为len,将它分为若干个长度为gap的子数组;
* 将"每2个相邻的子数组" 进行合并排序。
*
* 参数说明:
* a-- 待排序的数组
* len -- 数组的长度
* gap -- 子数组的长度
*/
void merge_groups(int a[], int len, intgap)
{
int i;
int twolen = 2 * gap; // 两个相邻的子数组的长度
// 将"每2个相邻的子数组" 进行合并排序。
for(i = 0; i+2*gap-1 < len; i+=(2*gap))
{
merge(a, i, i+gap-1, i+2*gap-1);
}
// 若 i+gap-1 < len-1,则剩余一个子数组没有配对。
// 将该子数组合并到已排序的数组中。
if ( i+gap-1 < len-1)
{
merge(a, i, i + gap - 1, len - 1);
}
}
/*
* 归并排序(从下往上)
*
* 参数说明:
* a-- 待排序的数组
* len -- 数组的长度
*/
void merge_sort_down2up(int a[], int len)
{
int n;
if (a==NULL || len<=0)
return ;
for(n = 1; n < len; n*=2)
merge_groups(a, len, n);
}
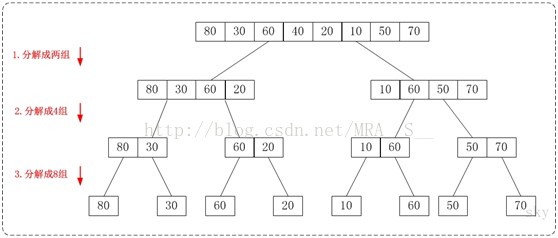
从下往上的归并排序的思想正好与"从下往上的归并排序"相反。如下图:
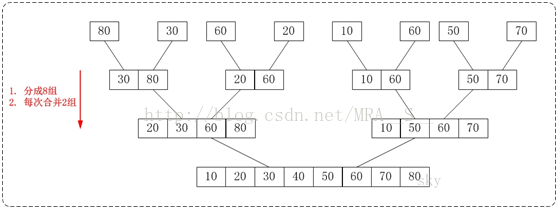
通过"从下往上的归并排序"来对数组{80,30,60,40,20,10,50,70}进行排序时:
1. 将数组{80,30,60,40,20,10,50,70}看作由8个有序的子数组{80},{30},{60},{40},{20},{10},{50}和{70}组成。
2. 将这8个有序的子数列两两合并。得到4个有序的子树列{30,80},{40,60},{10,20}和{50,70}。
3. 将这4个有序的子数列两两合并。得到2个有序的子树列{30,40,60,80}和{10,20,50,70}。
4. 将这2个有序的子数列两两合并。得到1个有序的子树列{10,20,30,40,50,60,70,80}。
3) 归并排序的时间复杂度和稳定性
归并排序时间复杂度
归并排序的时间复杂度是O(N*lgN)。
假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢?
归并排序的形式就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的可以得出它的时间复杂度是O(N*lgN)。
归并排序稳定性
归并排序是稳定的算法,它满足稳定算法的定义。
算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
4) 归并排序实现
实现的原理和输出结果都是一样的,每一种实现中都包括了"从上往下的归并排序"和"从下往上的归并排序"这2种形式。
实现代码(MergeSort.java)
上面3种实现的原理和输出结果都是一样的。下面是它们的输出结果:
before sort:80 30 60 40 20 10 50 70
after sort:10 20 30 40 50 60 70 80
八、 桶排序
1) 概要
本章介绍排序算法中的桶排序。内容包括:
1. 桶排序介绍
2. 桶排序图文说明
3. 桶排序实现
2) 桶排序介绍
桶排序(Bucket Sort)的原理很简单,它是将数组分到有限数量的桶子里。
假设待排序的数组a中共有N个整数,并且已知数组a中数据的范围[0, MAX)。在桶排序时,创建容量为MAX的桶数组r,并将桶数组元素都初始化为0;将容量为MAX的桶数组中的每一个单元都看作一个"桶"。
在排序时,逐个遍历数组a,将数组a的值,作为"桶数组r"的下标。当a中数据被读取时,就将桶的值加1。例如,读取到数组a[3]=5,则将r[5]的值+1。
3) 桶排序图文说明
桶排序代码
/*
* 桶排序
*
* 参数说明:
* a-- 待排序数组
* n-- 数组a的长度
* max -- 数组a中最大值的范围
*/
void bucketSort(int a[], int n, int max)
{
int i,j;
int buckets[max];
// 将buckets中的所有数据都初始化为0。
memset(buckets, 0, max*sizeof(int));
// 1. 计数
for(i = 0; i < n; i++)
buckets[a[i]]++;
// 2. 排序
for (i = 0, j = 0; i < max; i++)
{
while( (buckets[i]--) >0 )
a[j++] = i;
}
}
bucketSort(a, n, max)是作用是对数组a进行桶排序,n是数组a的长度,max是数组中最大元素所属的范围[0,max)。
假设a={8,2,3,4,3,6,6,3,9}, max=10。此时,将数组a的所有数据都放到需要为0-9的桶中。如下图:

在将数据放到桶中之后,再通过一定的算法,将桶中的数据提出出来并转换成有序数组。就得到我们想要的结果了。
4) 桶排序实现
实现代码(BucketSort.java)
/**
* 桶排序:Java
*
*@author skywang
*@date 2014/03/13
*/
public class BucketSort {
/*
* 桶排序
*
* 参数说明:
* a -- 待排序数组
* max -- 数组a中最大值的范围
*/
public static void bucketSort(int[] a, int max) {
int[] buckets;
if (a==null || max<1)
return ;
// 创建一个容量为max的数组buckets,并且将buckets中的所有数据都初始化为0。
buckets = new int[max];
// 1. 计数
for(int i = 0; i < a.length; i++)
buckets[a[i]]++;
// 2. 排序
for (int i = 0, j = 0; i < max; i++) {
while( (buckets[i]--) >0 ) {
a[j++] = i;
}
}
buckets = null;
}
public static void main(String[] args) {
int i;
int a[] = {8,2,3,4,3,6,6,3,9};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
bucketSort(a, 10); // 桶排序
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
上面3种实现的原理和输出结果都是一样的。下面是它们的输出结果:
before sort:8 2 3 4 3 6 6 3 9
after sort:2 3 3 3 4 6 6 8 9
九、 基数排序
1) 概要
本章介绍排序算法中的基数排序。内容包括:
1. 基数排序介绍
2. 基数排序图文说明
3. 基数排序实现
2) 基数排序介绍
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
3) 基数排序图文说明
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154,63, 616},它的示意图如下:

在上图中,首先将所有待比较树脂统一为统一位数长度,接着从最低位开始,依次进行排序。
1. 按照个位数进行排序。
2. 按照十位数进行排序。
3. 按照百位数进行排序。
排序后,数列就变成了一个有序序列。
基数排序代码
/*
* 获取数组a中最大值
*
* 参数说明:
* a-- 数组
* n-- 数组长度
*/
int get_max(int a[], int n)
{
int i, max;
max = a[0];
for (i = 1; i < n; i++)
if (a[i] > max)
max = a[i];
return max;
}
/*
* 对数组按照"某个位数"进行排序(桶排序)
*
* 参数说明:
* a-- 数组
* n-- 数组长度
* exp -- 指数。对数组a按照该指数进行排序。
*
* 例如,对于数组a={50, 3, 542, 745, 2014, 154, 63, 616};
* (01) 当exp=1表示按照"个位"对数组a进行排序
* (02) 当exp=10表示按照"十位"对数组a进行排序
* (03) 当exp=100表示按照"百位"对数组a进行排序
* ...
*/
void count_sort(int a[], int n, int exp)
{
int output[n]; // 存储"被排序数据"的临时数组
int i, buckets[10] = {0};
// 将数据出现的次数存储在buckets[]中
for (i = 0; i < n; i++)
buckets[ (a[i]/exp)%10 ]++;
// 更改buckets[i]。目的是让更改后的buckets[i]的值,是该数据在output[]中的位置。
for (i = 1; i < 10; i++)
buckets[i] += buckets[i - 1];
// 将数据存储到临时数组output[]中
for (i = n - 1; i >= 0; i--)
{
output[buckets[ (a[i]/exp)%10 ] - 1] = a[i];
buckets[ (a[i]/exp)%10 ]--;
}
// 将排序好的数据赋值给a[]
for (i = 0; i < n; i++)
a[i] = output[i];
}
/*
* 基数排序
*
* 参数说明:
* a-- 数组
* n-- 数组长度
*/
void radix_sort(int a[], int n)
{
int exp; // 指数。当对数组按各位进行排序时,exp=1;按十位进行排序时,exp=10;...
int max = get_max(a, n); // 数组a中的最大值
// 从个位开始,对数组a按"指数"进行排序
for (exp = 1; max/exp > 0; exp *= 10)
count_sort(a, n, exp);
}
radix_sort(a, n)的作用是对数组a进行排序。
1. 首先通过get_max(a)获取数组a中的最大值。获取最大值的目的是计算出数组a的最大指数。
2. 获取到数组a中的最大指数之后,再从指数1开始,根据位数对数组a中的元素进行排序。排序的时候采用了桶排序。
3. count_sort(a, n, exp)的作用是对数组a按照指数exp进行排序。
下面简单介绍一下对数组{53, 3, 542, 748, 14, 214, 154,63, 616}按个位数进行排序的流程。
(01) 个位的数值范围是[0,10)。因此,参见桶数组buckets[],将数组按照个位数值添加到桶中。

(02) 接着是根据桶数组buckets[]来进行排序。假设将排序后的数组存在output[]中;找出output[]和buckets[]之间的联系就可以对数据进行排序了。
基数排序实现

4) 实现代码(RadixSort.java)
/**
* 基数排序:Java
*
*@author skywang
*@date 2014/03/15
*/
public class RadixSort {
/*
* 获取数组a中最大值
*
* 参数说明:
* a -- 数组
* n -- 数组长度
*/
private static int getMax(int[] a) {
int max;
max = a[0];
for (int i = 1; i < a.length; i++)
if (a[i] > max)
max = a[i];
return max;
}
/*
* 对数组按照"某个位数"进行排序(桶排序)
*
* 参数说明:
* a -- 数组
* exp -- 指数。对数组a按照该指数进行排序。
*
* 例如,对于数组a={50, 3, 542, 745, 2014, 154, 63, 616};
* (01) 当exp=1表示按照"个位"对数组a进行排序
* (02) 当exp=10表示按照"十位"对数组a进行排序
* (03) 当exp=100表示按照"百位"对数组a进行排序
* ...
*/
private static void countSort(int[] a, int exp) {
//int output[a.length]; // 存储"被排序数据"的临时数组
int[] output = new int[a.length]; // 存储"被排序数据"的临时数组
int[] buckets = new int[10];
// 将数据出现的次数存储在buckets[]中
for (int i = 0; i < a.length; i++)
buckets[ (a[i]/exp)%10 ]++;
// 更改buckets[i]。目的是让更改后的buckets[i]的值,是该数据在output[]中的位置。
for (int i = 1; i < 10; i++)
buckets[i] += buckets[i - 1];
// 将数据存储到临时数组output[]中
for (int i = a.length - 1; i >= 0; i--) {
output[buckets[ (a[i]/exp)%10 ] - 1] = a[i];
buckets[ (a[i]/exp)%10 ]--;
}
// 将排序好的数据赋值给a[]
for (int i = 0; i < a.length; i++)
a[i] = output[i];
output = null;
buckets = null;
}
/*
* 基数排序
*
* 参数说明:
* a -- 数组
*/
public static void radixSort(int[] a) {
int exp; // 指数。当对数组按各位进行排序时,exp=1;按十位进行排序时,exp=10;...
int max = getMax(a); // 数组a中的最大值
// 从个位开始,对数组a按"指数"进行排序
for (exp = 1; max/exp > 0; exp *= 10)
countSort(a, exp);
}
public static void main(String[] args) {
int i;
int a[] = {53, 3, 542, 748, 14, 214, 154, 63, 616};
System.out.printf("before sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d", a[i]);
System.out.printf("\n");
radixSort(a); // 基数排序
System.out.printf("after sort:");
for (i=0; i<a.length; i++)
System.out.printf("%d ", a[i]);
System.out.printf("\n");
}
}
上面3种实现的原理和输出结果都是一样的。下面是它们的输出结果:
before sort:53 3 542 748 14 214 154 63 616
after sort:3 14 53 63 154 214 542 616 748
仅供个人学习,如有抄袭请包容.....















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









