









分类模型的评价指标–混淆矩阵,ROC,AUC
1. 混淆矩阵 – 就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵
假设训练之初以及预测后,一个样本是正例还是反例是已经确定的,这个时候,样本应该有两个类别值,一个是真实的0/1,一个是预测的0/1
true positives (TP): 实际为正预测为正。
true negatives (TN): 实际为负预测为负。
false positives (FP): 实际为负但预测为正。(也称为“第一类错误”。)
false negatives (FN): 实际为正但预测为负。(也称为“第二类错误”。)

通过混淆矩阵我们可以给出各指标的值:
查全率(召回率#灵敏度#真阳性率,recall#Sensitivity#TPR):
样本中的正例有多少被预测准确了
查全率=预测对的正例数 / 真正的正例数 = TP / (TP+FN)
++++++++++++++++++++++++++++++++++++++++++++++++
查准率(精确率,Precision):
针对预测结果而言,预测为正的样本有多少是真正的正样本
查准率=预测对的正例数 / 所有预测为正例的数 = TP / (TP+FP)
++++++++++++++++++++++++++++++++++++++++++++++++
特异度(特异度#真阴性率,Specificity#TNR):
样本中的负例有多少被预测准确了
Specificity/TNR = 预测对的负例数/真正的负例数 = TN / (TN+FP)
++++++++++++++++++++++++++++++++++++++++++++++++
准确率(Accuracy):针对整个模型
分类器统对整个样本的判定能力,能将正的判定为正,负的判定为负的能力,
Accuracy=(TP+TN) / (TP+FP+TN+FN)
++++++++++++++++++++++++++++++++++++++++++++++++
误分类率(误分类率#错误率,Misclassification Rate#Error Rate):总的来说,错分类的频率是多少?
Misclassification Rate=(FP+FN)/(TP+FP+TN+FN) = 1- 准确率
++++++++++++++++++++++++++++++++++++++++++++++++
假阳性率(False Positive Rate):当它实际上是“负的样本”的时候,它预测为“正的样本”的频率是多少?
FRP = FP/(FP+TF) = 1 - 真阴性率
++++++++++++++++++++++++++++++++++++++++++++++++
F1-Score:综合了Precision(查准率)与Recall(查全率)的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
F1-Score = 2 * Precision * Recall / (Precision+Recall)
# sklearn相关代码
import numpy as np
from scipy import interp
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import StratifiedKFold
import sklearn.metrics as sm
iris = datasets.load_iris()
X = iris.data
y = iris.target
X, y = X[y != 2], y[y != 2]
n_samples, n_features = X.shape
# Add noisy features
random_state = np.random.RandomState(0)
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# #############################################################################
# Classification and ROC analysis
# Run classifier with cross-validation and plot ROC curves
classifier = svm.SVC(kernel='linear', probability=True,
random_state=random_state)
# 使用混淆矩阵评估分类模型的分类效果
for train, test in cv.split(X, y):
probas_ = classifier.fit(X[train], y[train]).predict_proba(X[test])
pre = classifier.fit(X[train], y[train]).predict(X[test])
m=sm.confusion_matrix(y[test], pre)
# metrics提供了分类报告相关API,不仅可以得到混淆矩阵,还可以得到交叉验证查准率、召回率、f1得分的结果。
cr = sm.classification_report(y[test], pre)
print(cr)
print('###################')

2、ROC简介
ROC的全名叫做Receiver Operating Characteristic,中文名字叫“受试者工作特征曲线”,其主要分析工具是一个画在二维平面上的曲线——ROC 曲线。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。
一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。因为(0, 0)和(1, 1)连线形成的ROC曲线实际上代表的是一个随机分类器。如果很不幸,你得到一个位于此直线下方的分类器的话,一个直观的补救办法就是把所有的预测结果反向,即:分类器输出结果为正类,则最终分类的结果为负类,反之,则为正类。虽然,用ROC 曲线来表示分类器的性能很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC 曲线下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的性能。AUC(Area Under roc Curve)是一种用来度量分类模型好坏的一个标准。
为什么要选择ROC?
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
在面对正负样本数量不均衡的场景下,ROC曲线(AUC的值)会是一个更加稳定能反映模型好坏的指标。
AUC作为评价标准
- AUC (Area Under Curve)
被定义为ROC曲线下的面积,取值范围一般在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
2.AUC 的计算方法
非参数法:(两种方法实际证明是一致的)
(1)梯形法则:早期由于测试样本有限,我们得到的AUC曲线呈阶梯状。曲线上的每个点向X轴做垂线,得到若干梯形,这些梯形面积之和也就是AUC 。
(2)Mann-Whitney统计量: 统计正负样本对中,有多少个组中的正样本的概率大于负样本的概率。这种估计随着样本规模的扩大而逐渐逼近真实值。
参数法:
(3)主要适用于二项分布的数据,即正反样本分布符合正态分布,可以通过均值和方差来计算。
3.从AUC判断分类器(预测模型)优劣的标准
· AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
· 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
· AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
· AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
- 不同模型AUC的比较
总的来说,AUC值越大,模型的分类效果越好,疾病检测越准确;不过两个模型AUC值相等并不代表模型效果相同,例子如下:
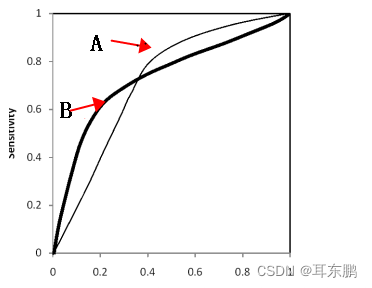
A,B两条ROC曲线相交于一点,AUC值几乎一样:当需要高Sensitivity时,模型A比B好;当需要高Speciticity时,模型B比A好。
roc_curve 函数
sklearn.metrics.roc_curve(y_true, y_score, pos_label=None, sample_weight=None, drop_intermediate=True)
Parameters :
y_true : 数组,shape = [样本数]
在范围{0,1}或{-1,1}中真正的二进制标签。如果标签不是二进制的,则应该显式地给出pos_label
y_score : 数组, shape = [样本数]
目标得分,可以是积极类的概率估计,信心值,或者是决定的非阈值度量(在某些分类器上由“decision_function”返回)。
pos_label:int or str, 标签被认为是积极的,其他的被认为是消极的。例:pos_label=2 是指在y中标签为2的是标准阳性标签,其余值是阴性
sample_weight: 顾名思义,样本的权重,可选择的
drop_intermediate: boolean, optional (default=True)
是否放弃一些不出现在绘制的ROC曲线上的次优阈值。这有助于创建更轻的ROC曲线
Returns :
fpr : array, shape = [>2] 增加假阳性率,例如,i是预测的假阳性率,得分>=临界值[i]
tpr : array, shape = [>2] 增加真阳性率,例如,i是预测的真阳性率,得分>=临界值[i]。
thresholds : array, shape = [n_thresholds] 阈值
减少了用于计算fpr和tpr的决策函数的阈值。阈值[0]表示没有被预测的实例,并且被任意设置为max(y_score) + 1
import numpy as np
from scipy import interp
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import StratifiedKFold
iris = datasets.load_iris()
X = iris.data
y = iris.target
X, y = X[y != 2], y[y != 2]
n_samples, n_features = X.shape
# Add noisy features
random_state = np.random.RandomState(0)
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# #############################################################################
# Classification and ROC analysis
# Run classifier with cross-validation and plot ROC curves
classifier = svm.SVC(kernel='linear', probability=True,
random_state=random_state)
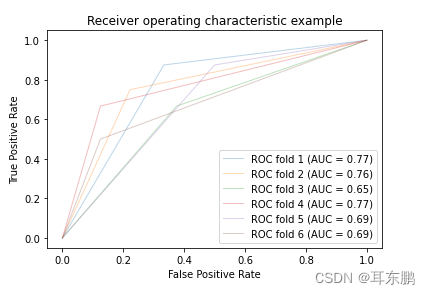
i=0
for train, test in cv.split(X, y):
pre = classifier.fit(X[train], y[train]).predict(X[test])
# Compute ROC curve and area the curve
fpr, tpr, thresholds = roc_curve(y[test], pre)
roc_auc = auc(fpr, tpr)
# print(i, roc_auc)
i+=1
plt.plot(fpr, tpr, lw=1, alpha=0.3,
label='ROC fold %d (AUC = %0.2f)' % (i, roc_auc))
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")














 2432
2432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









