







记录influxdb的应用过程,包括数据库搭建、数据库操作、数据库调用;api使用的是git大佬简单封装的代码,官网也有提供一些源码,如UDP、UnixSocket等接口方式,但依赖太多,在这儿就不做说明了。
一、搭建influxDB数据库
Ubuntu & Debian (64-bit)
wget https://dl.influxdata.com/influxdb/releases/influxdb_0.13.0_amd64.deb
![]()
sudo dpkg -i influxdb_0.13.0_amd64.deb
![]()
自动添加到系统自启服务
二、influx DB数据库启动
sudo service influxdb start
![]()
输入influx直接进入数据库
http://服务器IP:8083 即可进入web管理页面
到这一步你已经可以使用InfluxDB数据库啦,端口是8086,刚安装的InfluxDB是免密登录的,
如果开启身份验证就在配置文件下把auto-enabled选项设置为true :
[http]
auth-enable = true
最后使用 -config 选项将进程指向配置文件:
influxd -config /etc/influxdb/influxdb.conf
启停服务:service influxdb start/stop
端口:
8086 数据保存、查询端口,单机
8083 influxdb的web查询界面,单机
8088 集群使用 //0.12版不再开源
配置文件
• /etc/influxdb/influxdb.conf 默认的配置文件 修改连接参数,重启即可
• /var/log/influxdb/influxd.log 日志文件
• /var/lib/influxdb/data 数据文件
• /usr/lib/influxdb/scripts 初始化脚本文件夹
• /usr/bin/influx 启动数据库
• /var/run/influxdb/influxd.pid 服务启动的进程id
• /var/cache/yum/influxdb 缓存处理数据
三、数据库操作
1、创建数据库
Create database “testDB”
2、查询数据库
Show databases
3、使用数据库
Use testDB
4、插入数据(插入数据时自动建立表和当前时间戳)
Insert cpu,host=serverA,region=us_west value=6 //cpu表

5、查询数据
Select * from cpu order by time desc limit 3 //查询最近的三条数据
Select * from /.*/ limit 1 //正则表达式查询
6、删除数据
Delete from cpu where time=………//不能以value为条件
7、删除表
Drop measurement “cpu”
update更新语句没有,不过有alter命令,在influxdb中,删除和更新基本用不到 。在针对数据保存策略方面,有一个特殊的删除方式
8、数据保存策略
一般情况下基于时间序列的point数据不会进行直接删除操作,一般我们平时只关心当前数据,历史数据不需要一直保存,不然会占用太多空间。这里可以配置数据保存策略(Retention Policies),当数据超过了指定的时间之后,就会被删除。
Show retention policies on “testDB”
8.1、创建策略
Create retention policy “rc” on “testDB” duration 30d replication 1 default #注释如下:
rp_name:策略名
db_name:具体的数据库名
30d:保存30天,30天之前的数据将被删除
它具有各种时间参数,比如:h(小时),w(星期)
REPLICATION 1:副本个数,这里填1就可以了
DEFAULT 设为默认的策略
Alter retention policy “rc” on “testDB” duration 15d default//修改策略
Drop retention policy “rc” on “testDB”
9、连续查询
当数据超过保存策略里指定的时间之后,就会被删除。如果我们不想完全删除掉,比如做一个数据统计采样:把原先每秒的数据,存为每小时的数据,让数据占用的空间大大减少(以降低精度为代价)。这就需要InfluxDB提供的:连续查询(Continuous Queries)。采用时间聚合,只能是统计数据采样,不能去某条数据。
9.1、查看当前的查询策略
SHOW CONTINUOUS QUERIES
9.2、创建新的Continuous Queries
CREATE CONTINUOUS QUERY cq_30m ON testDB BEGIN SELECT mean(temperature) INTO weather30m FROM weather GROUP BY time(30m) END 注释如下:
cq_30m:连续查询的名字
testDB:具体的数据库名
mean(temperature): 算平均温度//或其他统计函数
weather: 当前表名
weather30m: 存新数据的表名
30m:时间间隔为30分钟
当我们插入新数据之后,通过SHOW MEASUREMENTS查询发现。可以发现数据库中多了一张名为weather30m(里面已经存着计算好的数据了)。这一切都是通过Continuous Queries自动完成的。
9.3、删除Continuous Queries
DROP CONTINUOUS QUERY <cq_name> ON <database_name>
四、用户管理
Show users //显示用户
CREATE USER "username" WITH PASSWORD 'password' WITH ALL PRIVILEGES //创建管理员权限的用户
DROP USER "username" //删除用户
五、其他操作
-- 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式
precision rfc3339; -- 之后再查询,时间就是rfc3339标准格式
-- 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339
-- 查看一个measurement中所有的tag key
show tag keys
-- 查看一个measurement中所有的field key
show field keys
-- 查看一个measurement中所有的保存策略(可以有多个,一个标识为default)
show retention policies;
三、程序调用
1、git上下载封装好的压缩包: https://codeload.github.com/mike-zhang/influxdbCApi/zip/master
2、将压缩包解压后,在test文件夹下,进行 sudo make编译,出现缺少头文件错误,如下

解决方法:安装 libcurl4-openssl-dev
![]()
若上述安装时出现以下错误
![]()
解决方法,删除两个文件,如下
![]()
再进行上述libcurl的安装,安装完成后再次sudo make;
3、再次编译出现未定义的引用问题,如下
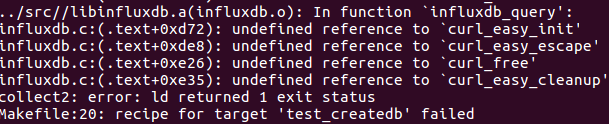
解决方法:编辑Makefile文件,将gcc编译命令中的LIBS放置末端,如下所示:gcc链接对顺序敏感,并且链接的库必须遵循所依赖的事物;

修改好,保存退出再次编译即可成功;
4、查看对应的增删改查等操作代码,运行编译生成的可执行文件,可看到对influx数据库的操作;若需要其他操作,可在src下的influxdb代码中添加方法。
5、我的运行结果
















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









