







简介
基于HBse的开源引擎,可以使用标准的JDBC API来代替HBase客户端API来创建表,插入数据,查询你的HBase数据,
Phoenix的性能:
phoenix是编译sql查询为原生的HBase的scan语句。
检测scan语句最佳的开始和结束的key。
精心编排你的scan语句让他们并行执行。
推送你的where子句的谓词到服务端过滤器处理。
执行聚合查询通过服务端的钩子。
实现了二级索引来提升非主键字段查询的性能。
安装
phoenix 映射一些表到hbase

命令练习
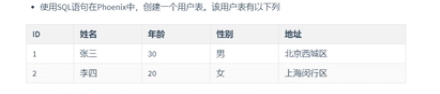
注意是upsert 而不是insert into 例如 upsert into name (id,int) select * from qitabiao
//创建表
create table if not exists "user_info"(
'id' varchar primary key,
'cf'.'name' varchar,
'cf'.'age' integer,
'cf'.'sex' varchar,
'cf'.'address' varchar
);
//插入操作
upsert into "user_info" values('1','张三',30,'男',‘shanghai’)
//更新操作
upsert into "user_info"('id','name') values('1','王五')
//删除操作
delete from "user_info" where "id"=2;
//查询语句
select * from "user_info" //注意表明需要带引号
//查询所有表
!tables;
与HBase表映射
首先在Hbase中建立一张表
create 'employee','company','family'
put 'employee','row1','company:name','zhenghaozhe'
put 'employee','row1','company:position','xuetu'
put 'employee','row1','family:phone','19837912345'
put 'employee','row2','company:name','nannan'
put 'employee','row2','company:position','teacher'
put 'employee','row2','family:phone','12345678910'
scan 'employee'
在phoenix
1 如果要与Hbase建立映射关系,必须create view
2 区分大小写和HBASE一样
3 所有的命令都是大写
4 建表时,如果不用双引号括起来,不论输入大小写,建立的表明都是大写
CREATE VIEW IF NOT EXISTS "employee"(
"rowid" VARCHAR NOT NULL PRIMARY KEY, //作为rowkey的字段用PRIMARY key标定,
"company"."name" VARCHAR,
"company"."position" VARCHAR,
"family"."phone" VARCHAR
);
//干完之后直接在phoenix中执行
select * from "employee" //即可看到Hbase表中村的数据
!tables //查看表结构
二级索引
在Hbase-site.xml中加入以下属性
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadooop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
重启Hbase集群,使配置生效
在Phoenix创建二级索引
//创建索引
create local index "index_phone" on "employee" ("family"."phone");
//查看执行计划,检查是否查询二级索引
explain select * from "employee" where "name"="zhenghaozhe" //进行全局扫描
explain select * from "employee" where "phone"="19837912345" //进行局部扫描
//删除索引
drop index "index_phone" on "employee"
//查看表上的所有索引
!indexes "employee"
DBeaver

这里 idea连接phoenix和图形化连接都报这个错误,我在API的properties中放入了hbase-site.xml,idea可以连接到了phoenix
批处理存入数据
phoenix有两种方式供批量写数据。一种是单线程psql方式,另一种是mr分布式。单线程适合一次写入十来兆的文件,mr方式更加适合写大批量数据。
create table xs(
number char(6) not null primary key,
name varchar(50),
gender tinyint(1) default 1
);
数据csv数据
111111,郑,1
222222,连磊,1
333333,马愉,1
444444,的,0
555555,侯老师,1
执行命令 psql.py -t XS node001:2181 XS.csv 即可 select * from XS;注意XS.csv的文件名字要和对应的数据库表名一样。

创建视图
第一种
1.首先phoenix中不能有这张表
2.在HBase中创建表后,在Phoenix中CREATE view "和HBase"中表名一模一样的就可以了,他们会自动关联
第二种
create view ‘student’ as select * form student
HBase中的表与phoenix建立链接

phoenix的数据类型
参考 https://www.cnblogs.com/codeOfLife/p/7404293.html
SPARK连接phoenix的API操作
官网代码
官网地址:https://phoenix.apache.org/phoenix_spark.html#
import org.apache.spark.SparkContext
import org.apache.spark.sql.{SQLContext, SparkSession, SaveMode}
import org.apache.phoenix.spark.datasource.v2.PhoenixDataSource //这个包我导入不了,pom不知道该导入哪个
val spark = SparkSession
.builder()
.appName("phoenix-test")
.master("local")
.getOrCreate()
// Load INPUT_TABLE
val df = spark.sqlContext
.read
.format("phoenix") //要写完整,只写个phoenix会报phoenix找不到的错误
.options(Map("table" -> "INPUT_TABLE", PhoenixDataSource.ZOOKEEPER_URL -> "phoenix-server:2181"))
.load
// Save to OUTPUT_TABLE
df.write
.format("phoenix")
.mode(SaveMode.Overwrite)
.options(Map("table" -> "OUTPUT_TABLE", PhoenixDataSource.ZOOKEEPER_URL -> "phoenix-server:2181"))
.save()
更改后的代码
package com.spark
import org.apache.spark.SparkContext
import org.apache.spark.sql.{SQLContext, SparkSession}
//import org.apache.phoenix.spark.datasource.v2.PhoenixDataSource
object PhoenixTest extends App {
val spark = SparkSession
.builder()
.appName("phoenix-test")
.master("local")
.getOrCreate()
// Load data from TABLE1
val df = spark.sqlContext
.read
.format("org.apache.phoenix.spark")
.options(Map("table" -> "TABLE1", "zkUrl"-> "node001,node002,node003:2181"))
.load()
df.show
df.filter(df("COL1") === "test_row_1" && df("ID") === 1L)
.select(df("ID"))
.show
//把自定义的数据放入表中
val dataSet=List(Row(1L,"1",1),Row(2L,"2",2),Row(3L,"3",3))
val schema =StructType(
Seq(StructField("ID", LongType, nullable = false),
StructField("COL1", StringType),
StructField("COL2", IntegerType)))
val rowRDD=spark.sparkContext.parallelize(dataSet)
val df1=spark.sqlContext.createDataFrame(rowRDD,schema)
df1.write
.format("")
.format("org.apache.phoenix.spark")
.options(Map("table" -> "OUTPUT_TABLE", "zkUrl"-> "node001,node002,node003:2181"))
.mode(SaveMode.Overwrite)
.save()
df1.show()
}
奇怪的东西
参考
本人写这个只是为了个人学习,如果有侵权行为,请及时联系我。
https://www.bilibili.com/video/BV1HD4y1R77p?p=6&spm_id_from=pageDriver















 1483
1483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









