







首先说明一下,我这里讲的是Windows64/32位操作系统下的安装教程。其他linux、Ubuntu环境下的安装暂时还未整理。请自行寻找教程。
安装Scrapy主要分为一下九个步骤:
1. 安装python。(相信大家都已经安装好了)
2. 配置python环境变量。(怕大家没有配置,所以这里啰嗦一下)
3. 下载安装pywin32。
4. 下载安装pip和setuptools。(为方便后续使用pip安装scrapy)
5. 安装Twisted。
6. 安装Zope.Interface和pyOpenSSL。
7. 安装lxml。
8. 下载 Microsoft Visual C++库:VCForPython27.msi。
9. 安装scrapy.
接下来我们就来详细讲解每一步。
1.安装python。
- 官网上选择你想要下载的python版本。
- 官网地址:https://www.python.org/downloads/
- 或者我这里有python2.7版本的安装包:
http://download.csdn.net/download/mtbaby/9898753直接下载即可。 - 下载后直接双击进行安装,建议安装到系统目录下,其余默认。
- 比如我安装到C盘,那我安装完后会在C盘下看到C:\python27.
2.配置环境变量
- 将python的安装目录复制到环境变量。右击“我的电脑”-“属性”-“高级系统设置”-“高级”-“环境变量”,找到“系统变量”里的path,然后将
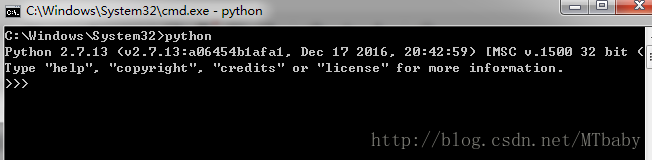
C:\Python27\;C:\Python27\Scripts;这两个路径添加到后面。 - 验证python是否安装成功。打开cmd,输入python,
若没
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









