






 本文详细介绍了ApacheHive的功能概述、元数据管理、基础架构、部署模式、客户端使用以及Hive的数据库和数据表操作,包括创建、插入、查询等,重点讲解了Hive与Hadoop、MySQL等的关系和不同部署选项的适用场景。
本文详细介绍了ApacheHive的功能概述、元数据管理、基础架构、部署模式、客户端使用以及Hive的数据库和数据表操作,包括创建、插入、查询等,重点讲解了Hive与Hadoop、MySQL等的关系和不同部署选项的适用场景。
一、Apache Hive 概述
Hive是一个SQL转化转化工具,将SQL的计算转为MapReduce的计算,让开发人员更加方便进行大数据开发
二、 模拟实现Hive功能(理解)
hive如何将hdfs上的数据转为结构化的表数据?
一张表的数据构成
1-表的元数据 描述表的基本信息
表名字,字段名,字段类型,字段约束
2-表的行数据
表中每一行的数据内容
表名:tb_stu
| id int | name varchar(20) | gander varchar(20) |
|---|---|---|
| 1 | 张三 | 男 |
| 2 | 李四 | 男 |
| 3 | 王五 | 男 |
在mysql,oracle等数据库中,表的元数据和行数是数据库统一管理
在hive中表的元数据和行数据由metastore和hdfs共同管理
表的元数据由metastore管理存储
行数据由hdfs管理存储
三、 Hive基础架构(重要)
三种客户端模式:
命令行模式 hive
第三方服务(要遵循jdbc协议) : java database connection datagrip beeline
web页面: 几乎不用
帮助我们查询元数据
HiveDriver hive驱动
解析sql语句
制定执行任务
提交mr任务
优化执行方案
执行计算任务
向yarn申请资源
从hdfs中提取数据
注意: hivedriver支持多种计算引擎, 例如 MapReduce Tez Spark
四、Hive部署(了解)
前提 : hadoop 服务 和 mysql 服务可以正常使用.
Hive的三种安装模式
-
==内嵌模式==(体验)
1、元数据存储在内置的derby 2、不需要单独配置metastore 也不需要单独启动metastore服务 安装包解压即可使用。 适合测试体验。实际生产中没人用。适合单机单人使用。
-
==本地模式==(测试)
1、元数据使用外置的RDBMS,常见使用最多的是MySQL。 2、不需要单独配置metastore 也不需要单独启动metastore服务 缺点: 如果使用多个客户端进行访问,就需要有多个Hiveserver服务,此时会启动多个Metastore 有可能出现资源竞争现象
-
==远程模式==(开发) 知道这种模式就可以了
1、元数据使用外置的RDBMS,常见使用最多的是MySQL。 2、metastore服务单独配置 单独手动启动 全局唯一。 这样的话各个客户端只能通过这一个metastore服务访问Hive. 企业生产环境中使用的模式,支持多客户端远程并发操作访问Hive. 也是我们课程中使用的模式。
-
对比
metadata存储在哪 metastore服务如何 内嵌模式 Derby 不需要配置启动 本地模式 MySQL 不需要配置启动 ==远程模式== ==MySQL== ==单独配置、单独启动==
在公共服务中已经将hive部署完成
Hive服务是单机服务,但是,可以进行分布式存储和分布式计算 (基于hdfs和MapReduce)
hive部署完成后,只有node1可以启动服务,但是node2,node3....都可以使用hive服务,因为其可以使用客户端远程链接node1上的服务.
五、 Hive初体验(了解)
先将统一大数据环境读取快照到07位置
hive依赖于hadoop的功能才能正常使用,所以启动hive前必须先启动hadoop.
start-all.sh
检查mysql服务是否可以使用
systemctl status mysqld
六、Hive客户端(重要)
6-1 本地使用
使用一代客户端在本地服务器上连接hive完成sql操作
需要先把metastore的元数据管理服务启动起来
-
启动metastore服务
hive --service metastore
实际开发中让服务后台运行
nohup hive --service metastore &
hive使用java开发,服务运行后可以jps查看java运行的程序
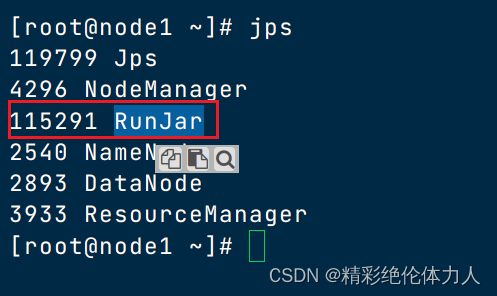
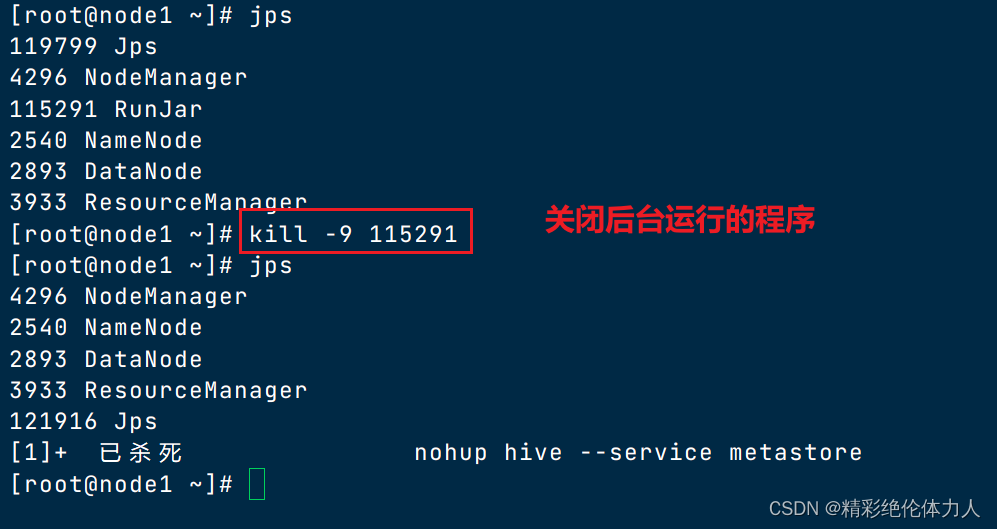
使用一代客户端连接,不需要输入账号密码
hive
6-2 远程使用
可以在其他服务器中连接hive进行相关操作
可以使用二代客户端进行连接,二代客户端支持jdbc,并且需要使用账号进行登录
-
1-启动metastore服务
-
管理元数据
-
-
2-启动hiveserver2服务
-
底层调用thriftserver
-
运行服务支持jdbc连接
-
nohup hive --service hiveserver2 &
注意不要重复启动

hiveserver2的启动时间
会比较长,可以通过端口查看确认hiveserver2是否真的启动hiveserver2运行时会绑定10000端口
lsof -i:10000
使用hive自带的二代客户端,通过jdbc方式连接hive
beeline

七、 Datagrip使用(掌握)
使用Datagrip连接Hive
-
创建工程(起一个工程名称即可)
-
绑定一个文件路径,用来存放我们书写的sql语句


-
连接hive服务
前提: 启动metastore 和hiveserver2服务
Datagrip连接hive服务,本质上链接的是hiveserver2
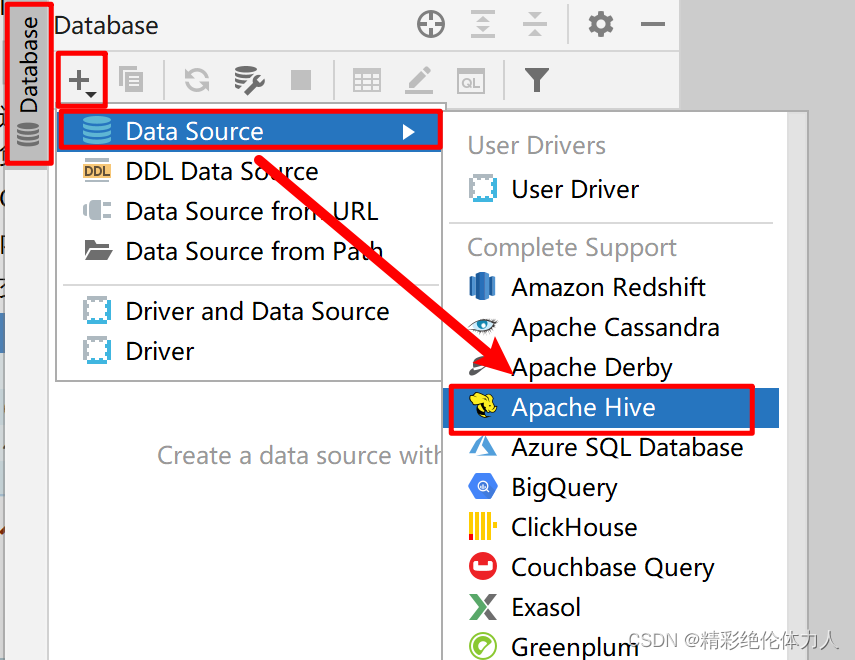
填写信息
直接点击链接界面左下方的download driver.

点解test connection验证连接,当连接成功时,点击ok就可以使用了
八、hive的数据库操作
数据库创建
CREATE DATABASE [IF NOT EXISTS] database_name -- 指定数据库在hdfs上路径位置 [LOCATION hdfs_path] [] 括起来内容是可选的关键字语法
按照默认路径创建数据库
-- 在hive中不需要指定charset create database itcast; -- 一但创建成功会在hdfs的默认路径下出现一个数据库目录 在hdfs的/user/hive/warehousw create database if not exists itcast;

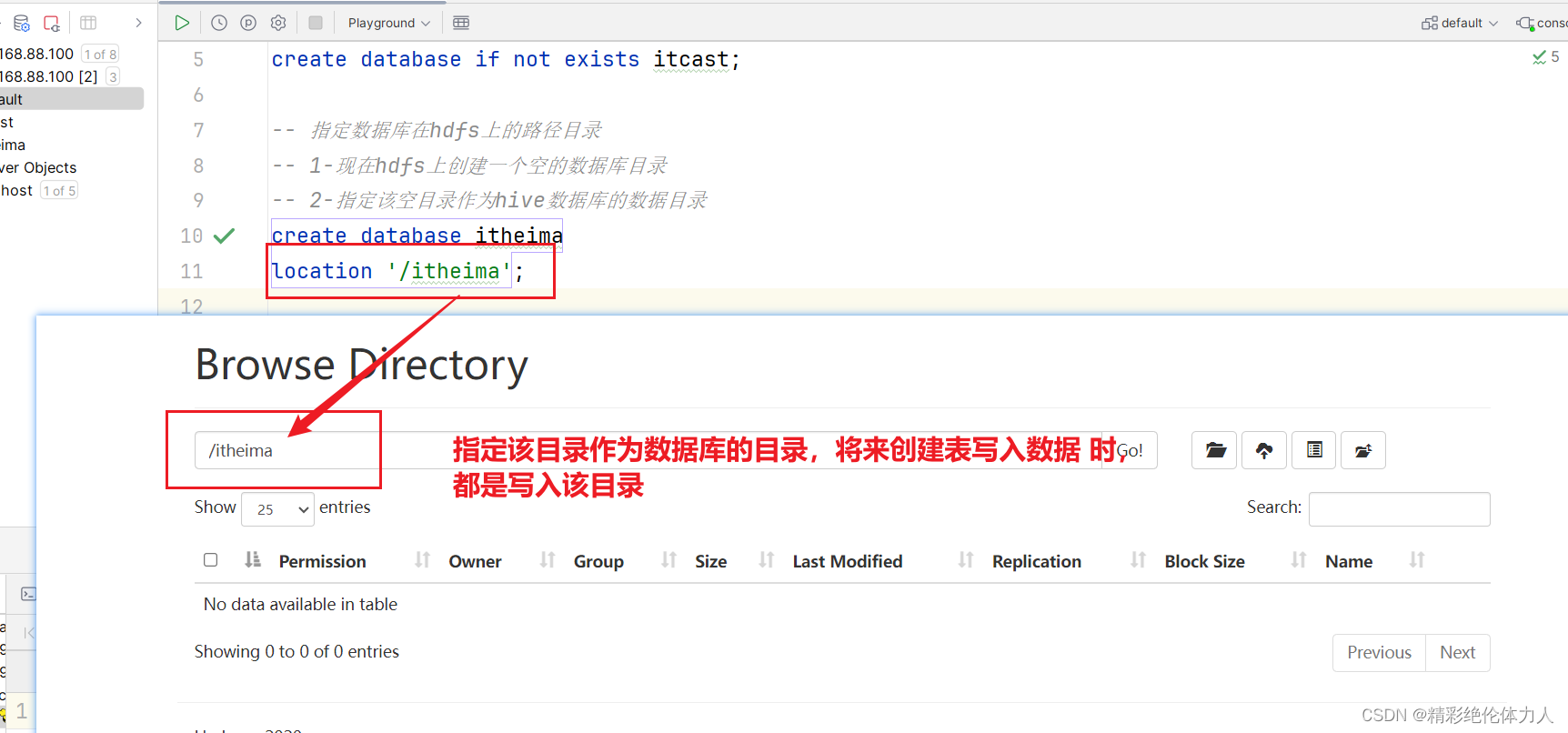
指定hdfs的路径目录作为数据库目录
-- 指定数据库在hdfs上的路径目录 -- 1-现在hdfs上创建一个空的数据库目录 -- 2-指定该空目录作为hive数据库的数据目录 create database itheima location '/itheima';
数据库的其他操作
-- use 切换数据库 use itcast; use itheima; -- 删除数据库 将 hdfs上的数据库目录一并删除 -- drop database itcast; -- drop database itheima; -- 如果数据库已经存在表数据,则需要强制删除 在有数据的情况下不要删库 -- drop database itcast cascade ; -- 查看数据库信息 desc database itheima; -- 查看建库语句 show create database itcast;
九、hive的数据表操作
9-1 建表语句
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note:
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
基本语法
create table [库名].表名(
字段 字段类型
);
-- 表的基本创建 -- 表创建成功后会在对应数据库目录下创建一个表目录 create table itcast.tb_stu( id int, -- 在hive中字符类型使用string name string, gender string, age int, create_time date, -- decimal 类型表示小数 10 整数部分的个数+小数据部分的个数 2 表示小数位数 height decimal(10,2) ); desc database itcast; create table itheima.tb_goods( id int, name string, price decimal(10,2), create_time date ); desc database itheima;
表数据写入和查询
-- 表数据写入 -- 数据是文件的方式存储在对应的表目录下 insert into itcast.tb_stu values(1,'张三','男',20,'2023-10-10',178.23),(2,'李四','男',21,'2023-10-11',175.23); -- 查看表数据 select * from itcast.tb_stu;















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









