






一、Ceph 简介
Ceph 是一个开源分布式存储系统。它为大量数据提供可扩展的容错存储。Ceph 使用分布式架构,使其能够提供高性能和可靠性。它通常用于云计算环境,可用于存储各种类型的数据,包括对象、块和文件存储。

-
Ceph 是可扩展的
Ceph 能够快速扩展,无需其他解决方案所需的典型停机时间。Ceph 采用先进的 CRUSH 算法,克服了所有可扩展性挑战,引领了实现真正灵活、难以置信的大规模弹性存储的道路。停止依赖昂贵的、特定于供应商的硬件和锁定合同。摆脱传统限制。随着业务的扩展,存储集群呈指数级增长。Ceph 是一种可扩展、经济高效的解决方案,可应对企业市场、学术机构及其他领域的快速、不可预测的数据增长。
-
Ceph 是可靠的
数据是不可替代的,因此存储系统的可靠性和微调管理至关重要。与 Ceph 一起实现安心;自我管理和自我修复,Ceph 会在您意识到问题之前发现并纠正问题。在存储集群中,Ceph Monitor 和 Manager 守护程序进行协调,以提高互连系统的可靠性和数据可用性。CRUSH 算法可降低单点故障风险、性能瓶颈和可扩展性限制,从而创建可靠且高性能的存储解决方案,适合不断增长的企业市场。
-
Ceph 是高性能的
Ceph 的配置和部署可以完全根据您的需求进行定制,而不会影响性能。将 Ceph 应用到您现有的存储设置中,或使用广泛可用的商用硬件创建新集群,以实现行业领先的可靠性和可扩展性,而无需花费传统的专有 ICT 基础架构。
传统存储系统在延迟、复杂的重复数据重复过程以及需要特定、不灵活的物理基础架构方面苦苦挣扎,而 Ceph 仍能保持高性能和可扩展性。
作为软件定义的存储系统,Ceph 旨在最大限度地提高效率和性能,无论它运行在何种基础架构上。
二、Ceph的架构原理
2.1 Ceph存储功能架构
Ceph的架构原理基于分布式存储和对象存储的概念。它由多个组件组成,包括监视器(Monitors)、对象存储守护进程(Object Storage Daemons,简称OSDs)和元数据服务器(Metadata Servers)。
监视器(Monitors)是Ceph集群的控制节点,负责存储集群的状态信息和元数据。它们通过选举机制来保证高可用性,并在集群中提供一致的视图。
对象存储守护进程(OSDs)是Ceph集群中的存储节点。它们负责存储实际的数据,并处理读写请求。每个OSD都会负责一部分数据,并通过数据复制和纠删码等机制来提供数据的冗余和容错性。
元数据服务器(Metadata Servers)负责管理文件系统的元数据,包括目录结构、文件属性等。它们提供了高度可扩展的元数据服务,以支持大规模的文件系统操作。 Ceph的数据存储和访问是基于RADOS(可靠自主分布式对象存储)的。RADOS将数据划分为对象,并将其分布在多个OSD上。这种分布式存储方式使得Ceph具有高度的可伸缩性和容错性。

1、基础存储系统RADOS
Reliable, Autonomic, Distributed Object Store,即可靠的、自动化的、分布式的对象存储。所有存储在Ceph系统中的用户数据事实上最终都是由这一层来存储的。Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也是由这一层所提供的。
2、基础库librados
这一层的功能是对RADOS进行抽象和封装,并向上层提供API,以便直接基于RADOS进行应用开发。由于RADOS是一个对象存储系统,因此,librados实现的API也只是针对对象存储功能的。
RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
3、高层应用接口
- radosgw: 对象网关接口(对象存储)
- rbd: 块存储
- cephfs:文件系统存储
其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。
2.2 Ceph物理组件架构
Ceph主要有三个基本进程
- Osd
OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。用于集群中所有数据与对象的存储。处理集群数据的复制、恢复、回填、再均衡。并向其他osd守护进程发送心跳,然后向Mon提供一些监控信息。
当Ceph存储集群设定数据有两个副本时(一共存两份),则至少需要两个OSD守护进程即两个OSD节点,集群才能达到active+clean状态.
- MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。为Ceph文件系统提供元数据计算、缓存与同步(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。在ceph中,元数据也是存储在osd节点中的,mds类似于元数据的代理缓存服务器。只有需要使用CEPHFS时,才需要配置MDS节点。
- Monitor
监控整个集群的状态,保证集群数据的一致性。
- Manager(ceph-mgr)
用于收集ceph集群状态、运行指标,比如存储利用率、当前性能指标和系统负载展示出来。对外提供 ceph dashboard(ceph ui)。
Ceph 结构包含两个部分
- ceph client:访问 ceph 底层服务或组件,对外提供各种接口。比如:对象存储接口、块存储接口、文件级存储接口。
- ceph node:ceph 底层服务提供端,也就是 ceph 存储集群。

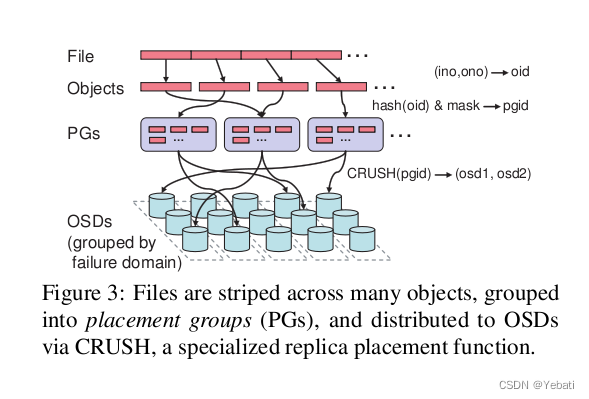
- Object
Ceph最底层的存储最小单位是Object--对象,每个Object包含元数据和原始数据。
- PG
PG全称Placement Groups,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
- CRUSH
CRUSH是Ceph底层使用的数据分布算法,让数据分配到预期的地方。
- RBD
RBD全称RADOS block device,是Ceph对外提供的块设备服务。
- RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
- CephFS 文件存储
CephFS全称Ceph File System,是Ceph对外提供的分布式文件存储服务。
三、Ceph的读写原理
1. 写入(Write):当客户端要写入数据时,它会将数据分割成对象,并将它们发送给Ceph存储集群中的监视器。监视器会确定数据应该存储在哪些OSD上,并将数据分发给相应的OSDs。OSDs接收到数据后,会将其存储在本地磁盘上,并复制到其他OSDs以提供冗余和容错性。一旦数据写入完成并得到确认,写操作就完成了。
2. 读取(Read):当客户端要读取数据时,它会向监视器发送读取请求,并提供所需数据的位置信息。监视器会返回数据所在的OSDs的信息。客户端直接与这些OSDs通信,请求所需的数据。如果某个OSD无法提供数据,客户端可以与其他副本进行通信以获取数据。一旦数据被读取并传输到客户端,读操作就完成了。















 7277
7277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









