







- 存储引擎是基于表的,而不是数据库。
InnoDB 简介
- InnoDB 存储引擎支持事务,面向在线事务处理,特点是行锁设计、支持外键以及非锁定读,即默认读取操作不会产生锁。
- InnoDB 通过使用 MVCC 多版本并发控制来获取高并发性,并实现了 SQL 标准的四种隔离级别:
未提交读(READ UNCOMMITTED):事务中的修改,即使没有提交,对其它事务也是可见的。
提交读(READ COMMITTED):一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
可重复读(REPEATABLE READ):保证在同一个事务中多次读取同样数据的结果是一样的。
可串行化(SERIALIZABLE):强制事务串行执行。
默认为 REPEATABLE 级别。 - 使用一种被称为 next-key locking 的策略来避免幻读现象,此外还有插入缓冲、二次写、自适应哈希索引、预读等高性能和高可用功能。
- 对于数据存储,InnoDB 采用聚集的方式,因此每张表都是按主键的顺序存放。没有显式定义主键,InnoDB会为每一行生成一个6字节的 ROWID 作为主键。
MyISAM 简介
- MyISAM 存储引擎不支持事务、表锁设计,支持全文索引。它不支持事务,事实上像数据仓库简单的查询就不需要事务。
- MyISAM 引擎表由 MYD(数据文件) 和 MYI (索引文件)组成。对于缓存问题,MyISAM 的缓冲池只缓存索引文件,不缓存数据文件,数据文件的缓存交由操作系统本身完成。
其他存储引擎
- NDB 引擎: 集群存储引擎,数据存放于内存中,主键查找数据极快,Join 操作在数据库层完成,而不是存储引擎层,跨集群网络开销极大,因此查询也很慢。
- Memory 存储引擎:数据存储在内存中,但是发生故障就会造成数据消失,因此适合作为存放临时表中间结果的存储引擎。
- MySQL 存储引擎还有:Archive / Federated / Maria / 其他
InnoDB 详细介绍
- InnoDB 1.2.x (MySQL 5.6)之后增加了全文索引支持、在线索引添加
- InnoDB 架构:
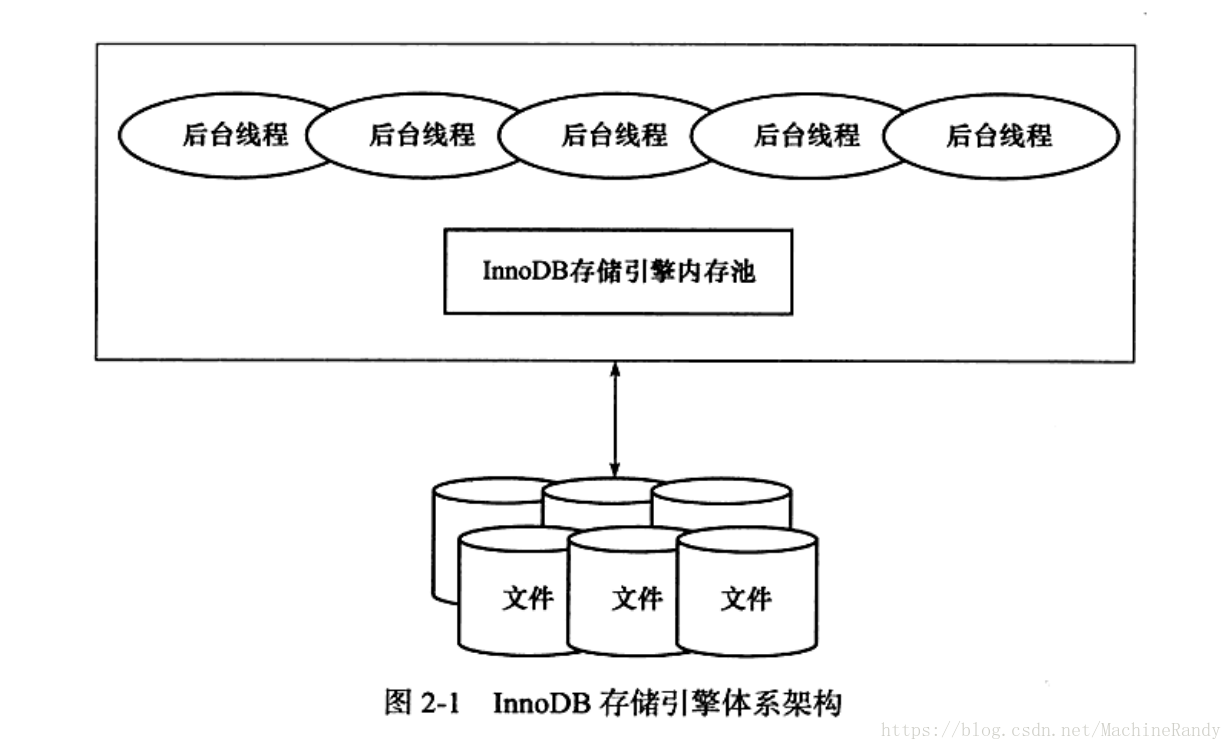
InnoDB 有很多个内存块,构成内存池。它们负责维护所有线程/进程需要访问的多个内部数据结构。同时缓存磁盘数据、重做日志缓冲。 - 通常数据库的缓冲池是通过LRU(最近最少使用)算法来管理的,InnoDB 也是使用 LRU, 并在LRU 的基础上做了优化,设置midpoint,默认情况下是在 5/8 处,格式为 new 列表 + midpoint + old 列表,新读取到的页虽然是新访问的页,但并不是直接放在LRU列表的首部而是放在midpoint 处。
- 为什么放在midpoint 而不是列表首部,若直接将读取到的页放在首部,某些SQL操作可能会使缓冲池的页被刷新出,通常来说对于索引或数据的扫描操作的数据并不是数据的热点数据,如果放在首部很可能将热点数据从LRU列表中移除,影响缓冲池效率,所以做一个折中。
- 在LRU 列表中的页被修改后,称为该页的脏页(dirty page)即缓冲池中的页和磁盘上的页的数据产生了不一致。
- LRU列表用来管理缓冲池中页的可用性,Flush 列表管理将页刷新回磁盘,互不影响。脏页会通过CHECKPOINT 机制将脏读数据刷新回磁盘,而FLUSH 列表中即为脏页列表,脏页同时存在 LRU 列表和 FLUSH 列表之中。
- 为了避免数据丢失问题,数据库普遍采用 Write Ahead Log 策略,即当事务提交时,先写重做日志,再修改页。当发生宕机导致数据丢失时,通过重做日志来完成数据的恢复。一般重做日志先缓存在缓冲池,一般每秒刷新一次到日志文件中。
- Checkpoint 技术,将缓冲池中的脏页刷回到磁盘,缩短数据库恢复时间。
- InnoDB 关键特性之 插入缓冲: B+树的特性决定了非聚集索引插入的离散性,数据的插入是根据主键顺序存放的,但是对于非主键的索引来说,这个插入就不是顺序性的了,这时就需要离散地访问非聚集索引页,因此性能回受到很大影响。所以,当索引是辅助索引(非主键索引)并且索引不是唯一的时候,InnoDB 引擎会使用 Insert Buffer(数据结构为 B+ 树) 来提高插入操作的性能,具体是过程为对于非聚集索引的插入或者更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在则插入,若不在则放入 Insert Buffer 对象中,之后再合并为一次插入,提高插入性能。
- InnoDB 关键特性之 两次写:采用创建页的副本,当写入失效发生时,先通过页的副本还原该页,再配合重做日志进行重做,提高数据页的可靠性。
- InnoDB 关键特性之 自适应哈希索引:InnoDB 会监控对表上各索引页的查询,如果观察到建立索引可以带来速度上的提升,则为其创建哈希索引,称为自适应索引。
- InnoDB 关键特性之 异步IO:通过异步而不是同步(阻塞)的方式进行 IO (AIO)操作,提高磁盘操作性能。
- InnoDB 关键特性之 刷新邻接页:当刷新一个脏页时,检测该页所有区的所有页,如果是脏页则一起进行刷新。
索引与算法
- InnoDB 索引支持:
B+ 树索引
全文索引
哈希索引 (自适应哈希索引,自动生成不能人为干预) - B+ 树索引并不能找到一个给定键的具体行,只能找到被查询数据所在的页,然后数据库通过把页读入内存,再在内存中进行查找,最后得到要查找的数据。
- B+ 树由 B 树和索引顺序访问方法(ISAM)演化而来,B/B+树相对于其他查找树拥有更矮的树高。B+ 树是为磁盘或其他直接存取辅助设备设计的平衡查找树,所有记录都存放在叶子节点并且是顺序存放
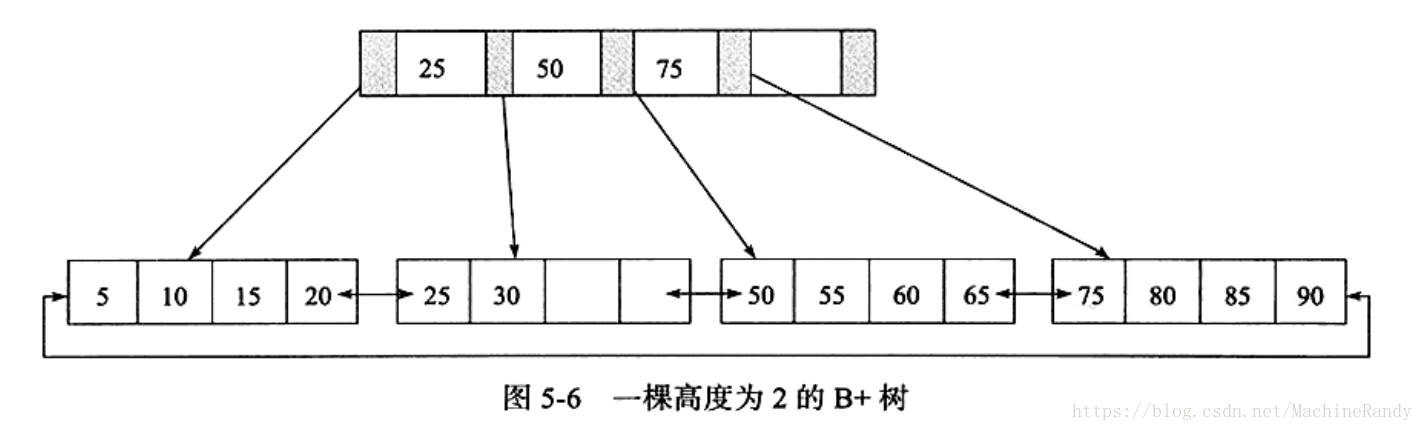
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。相对于内存存取,磁盘I/O存取的速度非常慢,磁盘读取以块为单位,B+ 树数据聚集在叶节点上,减少磁头寻道次数和预读功能减少了磁盘IO消耗。 - B+ 树索引在叶节点上的数据页之间通过双向链表进行链接。
- InnoDB 散列函数是除法散列方式。
- 全文检索,InnoDB 1.2.x 之后支持 MyISAM 全文索引的全部功能,全文索引通常是使用 倒排索引 实现的。倒排索引在辅助表中存储了单词和单词本身在一个或多个文档中所在的位置之间的映射。通常利用关联数组实现,InnoDB 采用 full inverted index 形式 { 单词,(单词所在文档ID,具体位置)} 实现关联数组,并且InnoDB 使用了6张辅助表。
- MySQL 全文检索查询语法:

事务
- InnoDB 默认的事务隔离级别为 READ REPEATABLE 完全遵循和满足事务的 ACID 特性。
- A(Atomicity)原子性,指数据库事务是不可分割的工作单位,只有使事务中所有的数据库操作都执行成功,才算整个事务成功,事务中任何动作失败,已经执行的工作都要撤销,数据库状态应该回滚到执行事务之前的状态。
- C(consistency)一致性,指事务将数据库从一种状态转变成下一种一致的状态,在执行事务前后,数据库的完整性约束没有被破坏。
- I(isolation)隔离性,也叫并发控制、可串行化、锁等,要求每个读写事务的对象对其他事务的操作能相互分离,通常使用锁来实现。
- D(durability)持久性,指事务一旦提交执行成功,其结果就是永久性的,即使发生宕机故障,数据库也能将数据恢复。
- 隔离性是由锁来实现的,原子性、一致性、持久性是通过数据库的 redo log 和 undo log 来完成的。redo log 称为重做日志,用来保证事务的原子性和持久性,undo log 用来保证事务的一致性。redo 和 undo 都是一种恢复操作,redo 恢复提交事务修改的页操作也就是记录事务的行为,而 undo 回滚行记录到某个特定的版本,redo 是物理日志,undo 是逻辑日志。
- 数据丢失:T1 和 T2 两个事务都对一个数据进行修改,T1 先修改,T2 随后修改,T2 的修改覆盖了 T1 的修改。
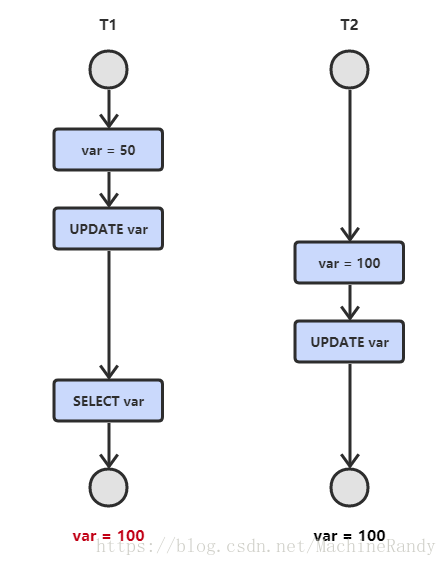
- 读脏数据:T1 修改一个数据,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2 读取的数据是脏数据。
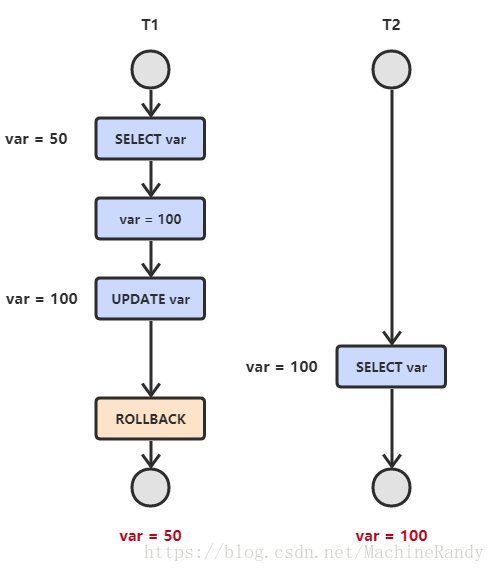
- 不可重复读:T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
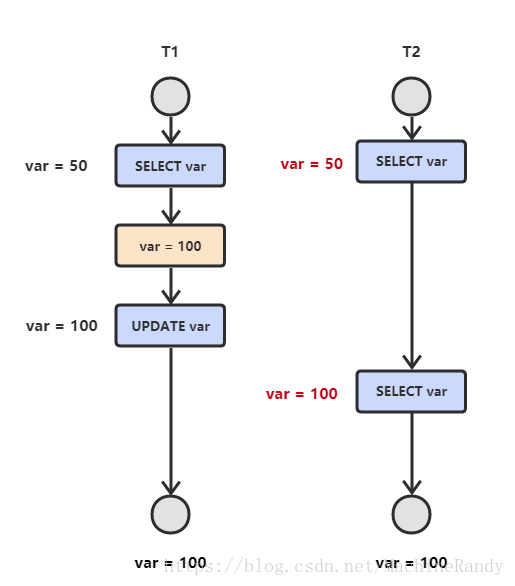
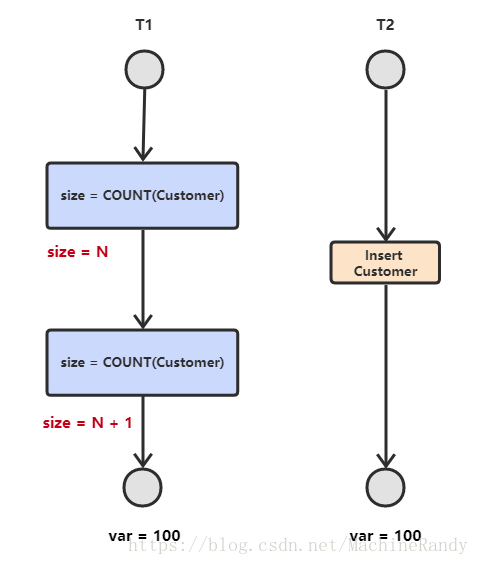
- 幻影读:T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
- 事务的隔离级别:
- READ UNCOMMITTED 未提交读:事务中的修改,即使没有提交,对其它事务也是可见的。
- READ COMMITTED 提交读:一个事务只能读取已经提交的事务所做的修改。
换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。 - REPEATABLE READ 可重复读:保证在同一个事务中多次读取同样数据的结果是一样的。InnoDB 中使用
Next-key Lock 避免幻读现象。 - SERIALIZABLE 可串行化:强制事务串行执行。
- 多版本并发控制
多版本并发控制(Multi-Version Concurrency Control, MVCC)是 MySQL 的 InnoDB 存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。 - Next-Key Locks
Next-Key Locks 是 MySQL 的 InnoDB 存储引擎的一种锁实现。
MVCC 不能解决幻读的问题,Next-Key Locks 就是为了解决这个问题而存在的。在可重复读(REPEATABLE READ)隔离级别下,使用 MVCC + Next-Key Locks 可以解决幻读问题。 - Record Locks 锁定一个记录上的索引,而不是记录本身。Gap Locks 锁定索引之间的间隙,但是不包含索引本身,例如当一个事务执行以下语句,其它事务就不能在 t.c 中插入 15 。
SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
Next-Key Locks 是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。
关系数据库设计理论
函数依赖
- 记 A->B 表示 A 函数决定 B,也可以说 B 函数依赖于 A。
- 如果 {A1,A2,… ,An} 是关系的一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
- 对于 A->B,如果能找到 A 的真子集 A’,使得 A’-> B,那么 A->B 就是部分函数依赖,否则就是完全函数依赖。
- 对于 A->B,B->C,则 A->C 是一个传递函数依赖。
Key 码 或称 键
- 码是数据系统中的基本概念。所谓码就是能唯一标识实体的属性,他是整个实体集的性质,而不是单个实体的性质。它包括超码,候选码,主码。
- 超码:如果K是一个超码,那么K的任意超集也是超码,也就是说如果K是超码,那么所有包含K的集合也是超码。
- 候选码是最小超码,它们的任意真子集都不能成为超码。
- 多个候选码中任意选出一个做为主码,如果候选码只有一个,那么候选码就是主码。
范式
- 第一范式(1NF):所有属性都是不可分的基本数据项。
- 第二范式(2NF):若关系模式R ∈ 1NF,表必须有一个主键并且每一个非主属性(没有包含在主键中的列)都完全依赖于主关键字。
- 第三范式(3NF):若关系模式R ∈ 2NF,非主键列必须直接依赖于主键,不能存在传递依赖。
参考:
MySQL 技术内幕 - 姜承尧
cyc 大佬的 Gitbook
https://cyc2018.gitbooks.io/interview-notebook/content/notes/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B3%BB%E7%BB%9F%E5%8E%9F%E7%90%86.html#record-locks

















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









