







索引(index)
学习来源:老杜带你学MySQL
补充一个面试知识点:
为什么在MySQL的DQL语句里面使用select *会导致查询效率变低
- 不需要的列会增加数据传输时间和网络开销
- 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
- 失去MySQL优化器“覆盖索引”策略优化的可能性
SELECT * 杜绝了覆盖索引的可能性,而基于MySQL优化器的“覆盖索引”策略又是速度极快,效率极高,是业界极为推荐的查询优化方式。
索引概述
- 什么是索引
索引是在数据库表的字段上添加的,是为了提高查询效率而存在的一种机制。一张表的一个字段可以添加一个索引。当然,多个字段联合起来也可以添加索引。索引相当于一本书的目录,是为了缩小扫描范围(提高查询效率)而存在的一种机制。
mysql> select * from t_users;
+----+----------+-------+---------+
| id | name | email | address |
+----+----------+-------+---------+
| 1 | zhangsan | NULL | NULL |
| 2 | wangwu | NULL | NULL |
| 3 | Jack | NULL | NULL |
| 4 | Maddox | NULL | NULL |
| 5 | ZDZ | NULL | NULL |
+----+----------+-------+---------+
5 rows in set (0.03 sec)
select * from t_user where name = 'Jack';
以上这条SQL语句是查询t_users表里的name字段,会去name字段上扫描。
如果name字段上没有添加索引(目录),或者说没有给name字段创建索引,MySQL会进行全扫描,会将name字段上的每一个值都比对一遍(即使已经找到’Jack’还是会比对Jack后面的其他值),效率很低。
MySQL在查询方面主要就是两种方式:
第一种方式:全表扫描
第二种方式:根据索引检索
注意:在MySQL数据库当中要对索引进行排序,因为只有排序了才会有区间查找的可能,而区间查找就是在缩小扫描范围。在MySQL当中的索引排序和TreeSet数据结构相同。TreeSet(TreeMap)底层是一个自平衡的二叉树(平衡二叉树、B-Tree,B+Tree,红黑树)。所以,在MySQL当中索引是一个B-Tree数据结构。遵循左小右大原则存放,采用中序遍历方式遍历取数据。
- 索引的实现原理
提醒1:
在任何数据库当中主键上都会自动添加索引对象
在MySQL当中,一个字段上如果有unique约束的话,也会自动创建索引
提醒2:
在任何数据库当中,任何一张表的任何一条记录在硬盘存储上都有一个硬盘的物理存储编号(指向该记录在硬盘上的物理地址)。
提醒3:
在MySQL当中,索引是一个单独的对象,不同的存储引擎以不同的形式存在,再MyISAM存储引擎中,索引存储在一个.MYI文件中。在InnoDB存储引擎中,索引存储在一个逻辑名称叫做tablespace的表空间当中。在MEMORY存储引擎当中索引被存储在内存当中。不管索引存储在哪里,索引在MySQL当中都是以一个树的形式存在。(自平衡二叉树:B-Tree)
InnoDB表空间tablespace被用于存储表的内容(表空间是一个逻辑名称,表空间存储数据+索引)
建议看看视频理解下图:
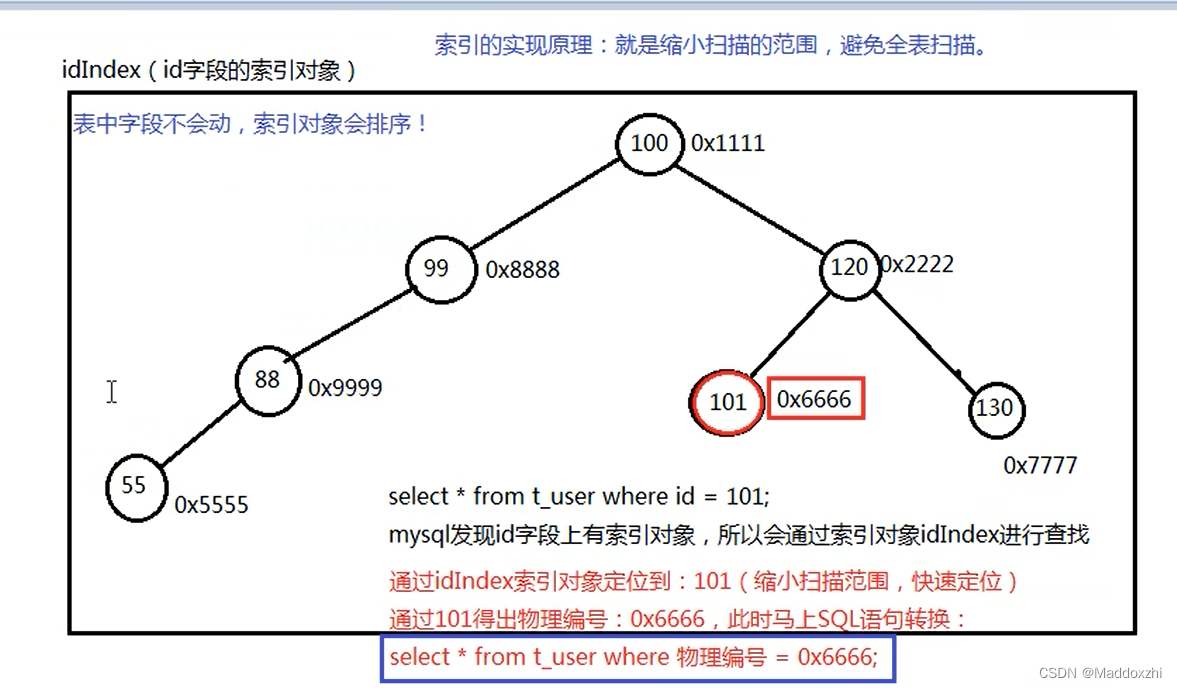
- 添加索引的应用场景
1. 数据量庞大(到底有多大算庞大,这个需要测试,因为每一个硬件环境不同)
2. 该字段经常出现在where的后面,以条件的形式存在,也就是说这个字段总是被扫描。
3. 该字段很少进行DML(insert、delete、update)操作。(因为DML之后,索引需要重新排序)
建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能。建议通过主键查询,建议通过unique约束的字段进行查询,效率是比较高的。
- 索引的创建和删除
创建索引:
create index emp_ename_index on emp(ename);//给emp表的ename字段添加索引,起名: emp_name_index
删除索引:
drop index emp_name_index on emp;//将emp表上的 emp_name_index索引对象删除
- 查看SQL语句是否使用了索引
mysql> select * from t_users;
+----+----------+-------+---------+
| id | name | email | address |
+----+----------+-------+---------+
| 1 | zhangsan | NULL | NULL |
| 2 | wangwu | NULL | NULL |
| 3 | Jack | NULL | NULL |
| 4 | Maddox | NULL | NULL |
| 5 | ZDZ | NULL | NULL |
+----+----------+-------+---------+
5 rows in set (0.03 sec)
mysql> explain select * from t_users where name = 'Jack';
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t_users | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
上图的运行结果显示rows = 5,说明没有使用索引,进行了全局检索,type = NULL
下面给name字段创建索引再看看输出结果
mysql> create index t_user_name_index on t_users(name);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from t_users where name = 'Jack';
+----+-------------+---------+------------+------+-------------------+-------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-------------------+-------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t_users | NULL | ref | t_user_name_index | t_user_name_index | 1023 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+-------------------+-------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
由上面可以看到rows = 1 ,说明只进行了一次查询
- 索引失效
1. 失效的第1种情况:
select * from emp where ename like '%T';
上述语句即使给ename字段添加了索引,也不会走索引查询,因为模糊查询匹配当中以“%”开头,这个时候根本不能确定具体的值是哪个,也就不能找到值所携带的索引。所以,尽量避免模糊查询的时候以“%”开头。 这是一种优化的手段/策略。
-----------------------------------------------------------------------------------------------------------------------------------------------------------
2. 失效的第2种情况:
使用“or”的时候会失效,如果使用or那么要求两边的条件字段都要有索引,才会走索引,如果其中一边有一个字段没有索引,那么另一个字段上的索引也会失效,所以不建议使用or。
-----------------------------------------------------------------------------------------------------------------------------------------------------------
3. 失效的第3种情况
使用复合索引的时候,没有使用左侧的列查找,索引失效
复合索引
两个字段或者更多的字段联合起来添加一个索引,叫做复合索引
create index emp_job_sal_index on emp(job,sal);//给emp表的job和sal字段添加索引,起名: emp_job_sal_indexmysql> select * from t_user; +------+------+------+ | id | name | sex | +------+------+------+ | 2 | abc | m | | 1 | aaa | m | | 3 | bbb | m | +------+------+------+ 3 rows in set (0.00 sec) mysql> create index t_user_name_sex_index on t_user(name,sex); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from t_user where name = 'aaa'; +----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+-------->--+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | >filtered | Extra | +----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+-------->--+-------+ | 1 | SIMPLE | t_user | NULL | ref | t_user_name_sex_index | t_user_name_sex_index | 131 | >const | 1 | 100.00 | NULL | +----+-------------+--------+------------+------+-----------------------+-----------------------+---------+-------+------+-------->--+-------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from t_user where sex = 'm'; +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra >| +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t_user | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using >where | +----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
两个字段联合查询(name,sex)左侧的列即name,右侧的列即sex,你可以只使用name列单独查询但不能使用sex列单独查询 (最左原则)
-
失效的第4种情况
在where当中索引列参加了运算,索引失效
explain select * from emp where sal + 1 = 800; -
失效的第5种情况
在where当中索引列使用了函数
explain select * from emp where lower(ename) = 'smith';
索引失效的情况还有许多,慢慢了解
- 索引在数据库当中的分类
索引是各种数据库进行优化的重要手段,优化的时候优先考虑的因素就是索引
单一索引:一个字段上添加索引
复合索引:两个字段或者更多的字段上添加索引
主键索引:主键上添加索引
唯一性索引:具有unique约束的字段上添加索引
注意:唯一性比较弱的字段上添加索引用处不大















 2137
2137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









