










想一想在繁忙的工作学习之余,如果能够定时收听到感兴趣的实时微博,实乃打工人的福音,提升工作效率之必备摸鱼神器。
为此,本文将介绍如何开发微博语音播报器,当前已实现的功能:在微博实时查询中查询某个关键字主题,并对搜索结果进行语音播报。
让我们git clone项目到本地,运行,戴上耳机,释放你的双手,开始微博沉浸之旅吧!做一只欢快的牛马,肆意驰骋,You deserve better.
关注公众号:仰望天空的蜗牛
欢迎关注作者公众号,追踪更多更新更有价值的内容。
一、前言
1.1 项目存放仓库
项目已经存放在gitee仓库,
项目gitee地址:https://gitee.com/shawn_chen_rtz/weibo_speaker.git
1.2 项目依赖的Python模块
clone项目到本地后,安装依赖模块,详见项目下的requirements.txt文件。
pip install -r requirements.txt1.3 项目实现思路
项目实现的主要思路如下,
- 对微博实时搜索结果页面进行解析,提取出不同用户所发布博文的必要信息——用户名、微博内容、微博博文id、发布时间等;
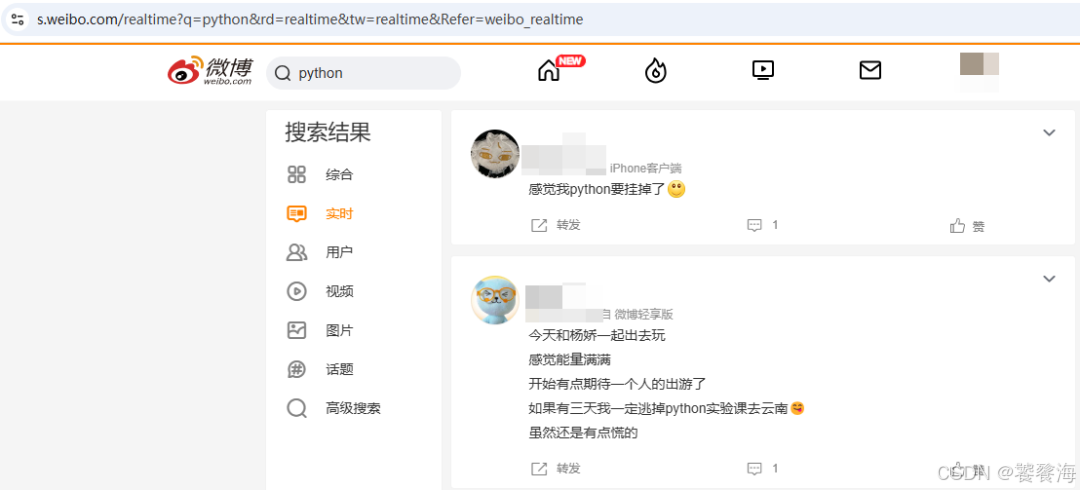
- 使用python pyttsx3模块结合语音引擎对提取出的文本信息进行语音合成、语音播放。
二、获取微博实时查询结果
2.1 获取微博实时查询结果
定义一个方法get_weibo_search用于获取微博实时查询结果,代码如下,
def get_weibo_search(keyword):
"""
根据查询关键字获取微博查询结果
:param keyword: 查询关键字
:return:
"""
# 进行url编码操作
# 等同于浏览器开发者工具-控制台中的函数encodeURIComponent()
encode_keyword = urllib.parse.quote(keyword)
base_url = "https://s.weibo.com/realtime"
result_set = []
headers = {"X-Requested-With": "XMLHttpRequest",
"Cookie": "SUB=_2A25US9d-8PUJbkNANLVTzkW1NUXc-K26MuvErP6RvR4Xwst93I6FC3l0N; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFmpDoV36wskXrwCOfoDO7o5JpX5KMhUgL.Fo2ReoM0SK50SoB2dJLoIERLxK.LBK-L1K-LxK.LBKBLB--LxKqLBo-LBoUki--4i-iFiK.pi--fiKLsiKLs;",
"Referer": f"https://s.weibo.com/realtime?q={encode_keyword}&rd=realtime&tw=realtime&Refer=pic_realtime"}
# 只获取分页 1页的搜索结果
for page in range(1, 2):
target_url = f"{base_url}?q={encode_keyword}&rd=realtime&tw=realtime&page={page}"
# print(f"请求的地址是 {target_url}")
logger.info(f"请求的地址是 {target_url}")
r = requests.get(target_url, headers=headers)
soup = BeautifulSoup(r.text, "html.parser")
results = soup.find_all('div', class_="content")
for result in results:
user_name = result.find('a', class_="name").get_text()
user_url = result.find('a', class_="name").get('href')
created_at = result.find('div', class_='from').get_text().strip().replace(' ', '').replace('\n', '')
mblog_id = result.find('div', class_='from').find_all('a')[0].get('href').split('?')[0].split('/')[-1]
title = result.find('p', class_='txt').get_text().strip()
if title.endswith('展开c'):
logger.info(f"开始获取{user_name}发布博文{mblog_id}的长文本")
title = get_mblog_long_text(mblog_id)
logger.info(f"成功获取{user_name}发布博文{mblog_id}的长文本")
temp = {
'title': title,
'mblog_id': mblog_id,
'created_at': created_at,
'user_name': user_name,
'user_url': user_url
}
result_set.append(temp)
# print(f"爬取的数据条数{len(result_set)}~")
logger.info(f"爬取的数据条数{len(result_set)}~")
return result_set通过请求拼接接口获取网页源代码,使用BeautifulSoup解析网页源代码,提取出微博博文的title、id、发布时间created_at、微博用户名user_name和用户地址user_url等信息。
2.2 获取长博文完整内容
在微博实时搜索结果页面中,当用户发布的博文内容超出一定长度时,会叠起展示,为了后续语音播报完整,我们需要获取长微博的完整内容。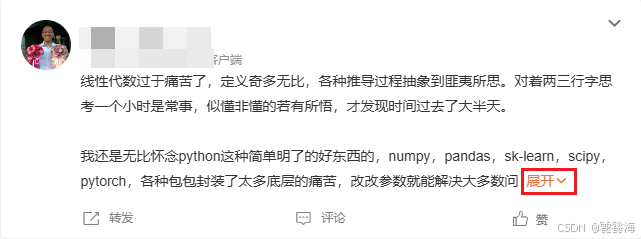
即如果获取到的title以“展开c”为结尾,我们需要多操作一步,获取其完整内容。
if title.endswith('展开c'):
title = get_mblog_long_text(mblog_id)获取微博完整内容方法get_mblog_long_text的代码实现,如下,
def get_mblog_long_text(mblog_id):
"""
通过微博id获取微博完整文本
:param mblog_id:
:return:
"""
logger.info(f"传入的微博id:{mblog_id}")
url = f"https://weibo.com/ajax/statuses/longtext?id={mblog_id}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
"Cookie": "SUB=_2AkMRBb7odcPxrAJmv8WyWvolH-jyi0NceAn7uJhMyOhh87mYkqSdutBF-XAHavRIYgFDYmUOPezr3SUzDg2yl"}
resp = requests.get(url, headers=headers).json()
mblog_longtext = resp.get("data").get("longTextContent")
logger.info(f"微博完整文本:{mblog_longtext}")
return mblog_longtext该方法最终返回长微博的完整内容。
对于以上两个方法的实现,都需要设置接口请求头headers中的Cookie信息,尤其SUB的值,需要保证其有效可用。可以登录微博状态下,在浏览器F12开发者工具对应接口请求中查找。
有任何问题请留言~
三、语音合成与播放
3.1 创建语音引擎对象
首先需要使用pyttsx3模块创建语音引擎对象,并对引擎对象的参数,比如语速、声量进行初始设置。
import pyttsx3
# 初始化引擎对象
engine = pyttsx3.init()
voices = engine.getProperty('voices')
for voice in voices:
# 选择中文语音包
if 'Chinese' in voice.name:
engine.setProperty('voice', voice.id)
break
# 设置语速
engine.setProperty('rate', 160)
# 设置音量
engine.setProperty('volume', 2.0)以上代码成功生成设置语音引擎对象。
3.2 语音合成和播放
创建一个方法speaker用于语音合成播放文本,
def speaker(text):
engine.say(text)
engine.runAndWait()简单的两行代码即可实现方法功能。该方法会把传入的文本text转换成语音并进行播放。
四、项目主程序入口
4.1 主程序
项目主程序,
import time
from get_live_weibo_search import get_weibo_search
from speaker import speaker
def main():
search_keyword = 'python'
mblogs = get_weibo_search(search_keyword)
for mblog in mblogs:
time.sleep(3)
speaker(f"以下内容来自微博用户{mblog.get('user_name')},关于{search_keyword}的最新微博")
time.sleep(1)
speaker(mblog.get('title'))
if __name__ == '__main__':
while True:
main()
waiting_time = 10*60
speaker(f"等待{int(waiting_time/60)}分钟后,再进行微博实时查询结果的播报。")
time.sleep(waiting_time)创建main方法,设置待查询的关键字search_keyword = 'python',这里设置的是python,你可以替换成你感兴趣、待查询的任何关键字;
遍历所有的搜索结果,并使用方法进行语音的合成与播放;
if __name__ == '__main__':中循环调用main方法,设置等待时间,可以定时搜索获取搜索结果,及时进行语音的播放,确保你不错过任何信息。
五、功能扩展
5.1 功能扩展
可扩展的功能场景:
-
假如你是某微博账号(或明星或购物网站or anything)的粉丝,可以编写对应的方法实时追踪该用户的微博,一旦用户发布最新微博,会第一时间为你语音播放。释放你的双眼与双手,在工作中,从容不迫地摸鱼,放松心情,提高工作效率;
-
除了微博,范围可以再扩散到其他平台,任何可获得文本的地方,你都可以使用Python编写方法获取文本信息,语音合成并播放。
可扩展或需完善的项目功能还有很多,感兴趣的可以发散思考一下并尝试代码实现,欢迎留言交流~
![]()
关注作者微信公众号,追踪更多有价值的内容!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









