





Tables
FIB、PIT、策略选择表和度量表在指标结构上有很多共性。为了提高性能和减少内存使用,在这四个表之间设计了一个公共索引,即名称树。
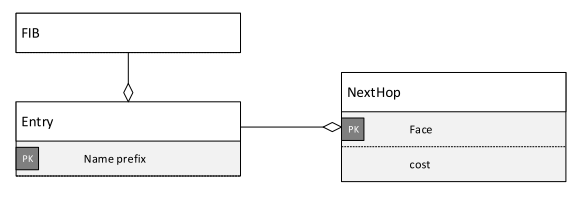
FIB
最长前缀匹配算法。
用法
FIB manager从RIB守护进程(第7节)接收命令,而后者则接收由应用程序手动配置或注册的静态路由,以及来自路由协议的动态路由。由于大多数FIB条目最终都来自动态路由,所以如果网络只有少量的已发布的前缀,那么FIB应该只包含少量的条目。预计FIB将相对稳定。FIB更新是由RIB更新触发的,而这些更新又是由手动配置、应用程序启动或关闭以及路由更新引起的。这些事件在一个稳定的网络中很少发生。但是,每个RIB更新都可能导致大量FIB更新,因为一个RIB条目中的更改可能会因为继承而影响它的后代。最长前缀匹配算法通过转发传入兴趣管道(4.2.1节)实现。每一项进入的兴趣包最多只调用一次。
CS
内容库(CS)是数据包的缓存。到达的数据包尽可能长地放在这个缓存中,以满足将来请求相同数据的需要。内容库在传入的兴趣被赋予转发策略以进行进一步处理之前进行搜索。这样,缓存的数据(如果可用)就可以用来满足兴趣,而不必实际将兴趣转发到其他任何地方。下面3.3.1将定义CS的语义和算法,关于当前实现的细节将在3.3.2节中讨论。
用两个数据结构实现:名称索引(Name index)、CachePolicy
缓存策略有:FIFO\LRU
不多加描述,具体看文档。
Interest Table(PIT)
既包含为解决的兴趣包、也包含最近满足的兴趣包。只被转发使用。

PIT中包含in-record、out-record、两个计时器。
in-record
记录中(nfd::pit:: InRecord)表示兴趣的下游face。下游face是内容的请求者:兴趣来自下游,数据流向下游。
in-record存储:
- face的记录
- 最后一个来自face的兴趣包中的nonce(随机数)
- 最后一个从face到达的兴趣包中的timestamp(时间戳)
- 最后一个兴趣包
插入或更新记录的传入兴趣管道(4.2.1节)。当一个未决的兴趣被满足时,所有的记录被输入数据管道(4.3.1节)删除。在最后一个兴趣包到达后,当兴趣生存期结束时,记录中的内容过期。当所有的in-record过期时,一个PIT条目过期。如果一个PIT条目包含至少一个未过期的in-record,那么它就被称为pending。
out-record
out-record (nfd::pit::OutRecord)表示兴趣的上游face。上游face是一个潜在的内容来源:兴趣被转发给上游,数据来自上游。
- face的记录
- 最后发送给face的兴趣包中的nonce
- 发送到此face的最后一个兴趣包的时间戳
- Nacked字段:表示最后一个传出的兴趣已被Nacked;此字段还记录Nack原因
输出记录由输出兴趣管道插入或更新(4.2.5节)。当一个面内的数据满足了一个待处理的兴趣时,incomingData管道(4.3.1节)会删除一个输出记录。当兴趣生存期在最后一个兴趣包发送之后结束时,输出记录将执行。
Timer
两个计时器用于转发管道。(未满足计时器)
数据匹配算法。
Dead Nonce List
在2014年8月,我们发现了一个当兴趣周期很短时的持久循环问题。循环检测之前只使用存储在PIT条目中的Nonces。如果在兴趣生存期内未满足某个兴趣,则在兴趣生存期结束时删除PIT条目。当网络包含一个延迟大于兴趣生存期的循环时,无法检测到该循环周围的循环兴趣,因为在兴趣循环回来之前PIT条目已经消失了。
这个持久循环问题的一个简单解决方案是将PIT条目保留更长时间。(消耗大)
引入dead nonce 列表
结构、语法、用法
在删除出记录之前,将Name和Nonce元组添加到传入数据管道(章节4.3.1)中的Dead Nonce列表(DeadNonceList::add)和兴趣finalize管道(章节4.2.8)。在传入兴趣管道(4.2.1节)中查询dead Nonce列表(DeadNonceList::has)。
- 如果存在具有相同名称和Nonce的条目,则传入的兴趣是循环兴趣。
- dead Nonce列表是一个概率数据结构:每个条目都存储为64位的名称和Nonce散列。这大大减少了数据结构的内存消耗。
- 同时,存在非零的哈希冲突概率,这将不可避免地导致误报:非循环的兴趣被误认为是循环的兴趣。
- 这些误报是可恢复的:使用者可以用一个新的Nonce重新传输兴趣,这很可能产生一个不同的散列,不会与现有散列发生冲突。我们相信,内存节省带来的好处超过了误报的危害。
策略选择Table
策略选择表包含为每个名称空间选择的转发策略(第5节)。理论上讲,转发策略是一个应该存储在FIB条目[9]中的程序。在实践中,我们发现将转发策略保存在一个单独的表中比用FIB条目存储更方便。
结构和语义
策略选择条目(nfd::strategy_choice:: entry)包含一个名称前缀,以及为此名称空间选择的转发策略的名称。目前没有参数。在运行时,对策略程序实例化的引用也从策略选择项链接。
为了保证每个名称空间都有一个策略,NFD总是在初始化时将/ namespace的根条目插入策略选择表。为这个条目选择的策略称为默认策略,由daemon/fw/available-strategies.cpp中硬编码的makeDefaultStrategy free函数定义。可以替换默认的策略,但是不能删除策略选择表中的根条目。
用法
策略应该由本地NFD操作员(个人计算机的用户或网络路由器的系统管理员)手动选择。采用有效的策略搜索算法,分别传入兴趣管道(4.2.1节)、未满足兴趣管道(4.2.7节)和传入数据管道(4.3.1节)进行转发。每个传入包最多调用两次。
度量表
一个度量条目(nfd:: Measurements:: entry)包含一个名称和用于策略存储和检索任意信息的api (nfd:: StrategyInfoHost, Section 5.1.3)。可以添加一些可以在策略之间共享的标准度量,如往返时间、延迟、抖动等。然而,我们认为每个策略都有其独特的需求,如果有效的策略没有利用这些标准度量,那么添加这些标准度量将成为不必要的开销。因此,目前度量条目不包含标准度量。
名称树
NameTree是FIB(3.1节)、PIT(3.4节)、Strategy Choice表(3.6节)和Measurements表(3.7节)的常用索引结构。使用公共索引是可行的,因为这四个表的索引有很多共性:FIB、StrategyChoice和Measurements都是按名称索引的,PIT是按名称和选择器索引的[1]。使用公共索引是有益的,因为对这四个表的查找通常是相关的(例如。FIB最长前缀匹配是在插入一个PIT条目后,在传入兴趣管道(4.2.1节)中调用的,使用公共索引可以减少包处理过程中查找索引的次数;索引使用的内存量也减少了。NameTree数据结构将在3.8.1节中介绍。NameTree操作和算法在第3.8.2节中描述。第3.8.3节描述了NameTree如何通过在表之间添加快捷方式来帮助减少索引查找的数量。
- 名称树条目包含:
- 名称前缀
- 指向父条目的指针
- 子条目的指针列表
- 0或1个FIB条目
- 0或多个PIT条目
- 0或1个策略选择条目
- 0或1个度量条目
精确匹配算法
最长前缀匹配算法
快捷键
NameTree的一个好处是它可以减少包转发过程中的索引查找次数。为了实现这个好处,一种方法是让转发管道显式地执行NameTree查找,并使用NameTree条目的字段。但是,这并不理想,因为引入NameTree是为了提高四个表的性能,它应该改变转发管道的过程。为了减少索引查找的数量,但仍然隐藏NameTree以避免转发管道,我们在表之间添加了快捷方式。每个FIB/PIT/StrategyChoice/Measurements条目都包含一个指向相应的NameTree条目的指针;NameTree条目包含指向FIB/PIT/StrategyChoice/Measurements条目的指针和父NameTree条目。因此,例如,给定一个PIT条目,可以在常数时间内跟随指针检索相应的NameTree条目,然后通过NameTree项检索或附加一个度量项,或者通过跟随指向父类的指针查找最长前缀匹配的FIB项。如果我们采用这种方法,NameTree条目仍然可以被转发。为了隐藏NameTree条目,我们向表算法引入了新的重载,用相关的表条目代替名称。这些过载的前提包括:
- findLongestPrefixMatch可以接受PIT条目或measurement条目来代替名称
- stratgychoice::findEffectiveStrategy可以接受pit条目或度量条目来代替名字
- measurement::get可以接受FIB条目或PIT条目来代替名称
接受表条目的重载通常比接受名称的重载更有效。通过使用这些重载,转发可以利用减少的索引查找,但是不需要直接处理NameTree条目。为了支持这些重载,NameTree提供了NameTree:: get方法,该方法返回从FIB/PIT/StrategyChoice/Measurements条目链接的NameTree条目。该方法允许一个表从另一个表的一个条目中检索相应的NameTree,而不需要知道该条目的内部结构。它还允许一个表在将来离开NameTree而不破坏其他代码:假设有一天PIT不再基于NameTree, NameTree::get可以在PIT条目中使用兴趣名执行查找;findLongestPrefixMatch仍然可以接受PIT条目,尽管它并不比使用名称更有效。
疑问
- 为什么大多数FIB路由来自动态路由,如何配置?















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









