







序列化
首先我们介绍下序列化和反序列化的概念:
- 序列化:把Java对象转换为字节序列的过程,实现对象的持久化。
- 反序列化:把字节序列恢复为Java对象的过程。
“持久化”意味着一个对象的生存周期并不取决于程序是否正在执行:它可以生存于程序的调用的之间,它的属性,运行状态都将会被保存下来。
对象的序列化主要有两种用途:
- 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;(持久化对象)
- 在网络上传送对象的字节序列。(网络传输对象)
Serializable接口
public interface Serializable {}
只要对象实现了Serializable接口, 就可以实现序列化. 这个接口只是一个标记接口, 没有任何方法.
参考ObjectOutputStream的writeObject0()方法的实现,它在写出对象时用来做判断:
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) { // 如果对象实现了序列化接口,则写出
writeOrdinaryObject(obj, desc, unshared);
} else {
// 否则将抛出NotSerializableException异常
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
因此这个接口的作用就是在用来判断对象的类型.
本文以下方的User类作为序列化对象
public class User {
public String uname;
public String pwd;
public int age;
public User(String uname, String pwd, int age) {
System.out.println("我是" + User.class.getSimpleName() + "有参构造器" );
this.uname = uname;
this.pwd = pwd;
this.age = age;
}
public User() {
System.out.println("我是" + User.class.getSimpleName() + "无参构造器" );
}
}
如果User类实现了Serializable 接口:
public class User implements Serializable {...}
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("db.txt"));
User user = new User("张三", "123456", 15);
oos.writeObject(user);
oos.flush();
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("db.txt"));
user = null;
User obj = (User)ois.readObject();
System.out.println(obj);
控制台输出如下:

- Serializable可以让所有成员变量自动完成序列化.
- 读取时, 对象完全以它存储的二进制位基础来构建对象, 不需要调用任何的构造器, 整个对象都是从InputStream中取得数据恢复而来的.
- 但是JVM必须要找到对应的Class对象, 否则将抛出一个ClassNotFoundException异常.
- 序列化时不会对static和transient修饰的变量进行序列化, static属于类成员, transient是临时变量.
Externalizable接口
Serializable可以让所有成员变量自动完成序列化. 但是有时我们未必想要这么做, 我们只想让真正有需要的成员变量完成序列化或者还想要序列化一些不是成员变量的对象. 因此我们想要获取序列化的完全控制权.
在这种特殊情况下, 就需要Externalizable接口.
Externalizable接口继承自Serializable, 同时它添加了两个方法writeExternal, readExternal. 这两个方法会在序列化和反序列化过程中被自动调用.
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}
我们让User类实现Externalizable接口, 并实现这两个方法.
public class User implements Externalizable {
//其他代码...
public void writeExternal(ObjectOutput out) throws IOException {
System.out.println("我是" + User.class.getSimpleName() + "writeExternal方法" );
// 只序列化两个变量
out.writeUTF(uname);
out.writeInt(age);
}
/**
* 先调用父类以及自生的public的无参构造器, 然后才会自动被调用.
*/
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
System.out.println("我是" + User.class.getSimpleName() + "readExternal方法" );
// 反序列化时,需要和序列化对象对应
uname = in.readUTF();
age = in.readInt();
}
}
控制台输出如下:
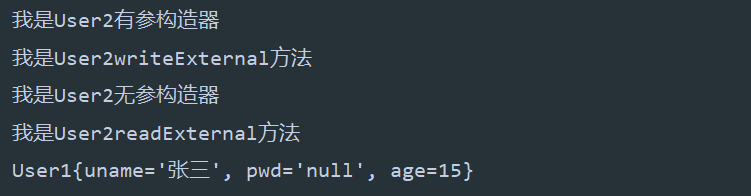
可以看到, 在反序列化时, 会调用默认的构造器, 这与恢复一个Serializable对象不同. 对于Serializable对象, 对象完全以它存储的二进制位为基础来构造, 而不需要调用构造器. 而Externalizable对象不同, 父类和自身的public默认构造器会按顺序执行, 然后再调用readExternal方法. 这是因为, Externalizable对象的序列化过程完全由程序员掌控, 程序员可以任意写入想要序列化的成员变量. 在反序列化时, 就可能无法拼凑出一个完整的对象, 因此就必须先获得一个完整的对象, 然后再从字节序列中读取数据
transient关键字
实现Externalizable接口的类, 可以防止对象敏感部分被序列化, 对象的所有成员变量都不会自动序列化, 只能在writeExternal方法内序列化所需的部分. 然而, 如果我们操作的是一个Serializable对象, 那么所有的序列化操作都会自动执行, 为了能够加以控制, 我们可以使用transient关键字逐个的关闭序列化.
修改User类, 给pwd成员变量添加transient关键字.
public class User implements Serializable {
public String uname;
public int age;
/*
将该对象取消序列化
*/
public transient String pwd;
// 其他方法...
}
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("db.txt"));
User user = new User("张三", "123456", 15);
oos.writeObject(user);
oos.flush();
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("db.txt"));
user = null;
User obj = (User)ois.readObject();
System.out.println(obj);
控制台输出如下:

-
用transient关键字标记的成员变量不参与序列化过程.
-
transient关键字只能用在Serializable对象中
Java源码中有很多transient关键字的应用:
比如ArrayList类中, ArrayList实现了Serializable接口. 并且底层使用的是数组来存储数据, 而这个数组就被transient修饰.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
transient Object[] elementData;
//...
}
既然要序列化集合,那又为什么不序列化这个数组呢? 因为底层再次对这个数组进行了优化, ArrayList可以看成一个变长数组, 这个数组中存储的数据不一定都是有用的, 末尾可能有无用的数据. 因此我们真正需要序列化的对象数据数量应该是容器长度个, 而不是数组长度个. 序列化时只要操作我们想要的数据即可.
ArrayList中的writeObject方法, 在序列化时被调用:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
int expectedModCount = modCount;
// 序列化默认的字段
s.defaultWriteObject();
// JDK1.8版本的size虽然没有被transient修饰, 但是低版本中并不是, 强制序列化size是出于对低版本的支持
s.writeInt(size);
// 注意: 只迭代了size次, 而不是elementData.length次
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
serialVersionUID
serialVersionUID的作用:简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。(InvalidCastException)
当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID,类型为long的变量时,Java序列化机制会根据编译的class(它通过类名,方法名等诸多因素经过计算而得,理论上是一一映射的关系,也就是唯一的)自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释,等等),就算再编译多次,serialVersionUID也不会变化的.
serialVersionUID是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段.
// 例如:
private static final long serialVersionUID = 7369333397290067554L;















 3402
3402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









