








1. Delete HTML Tag
We know the Tag is un-informational for us, such as image location and font style. The HTML tag format is <Tag> or <Tag></Tag>
For example :
HTML Code segment ------------
<TR>
<TD><FONT color=#ffffff></FONT></TD>
<TD width=398 bgColor=#abb 7c 3>
<P align=center><FONT color=#ffffff><A
href="http://www.zgsr.gov.cn/zww/ldxx/index.asp"><FONT
color=#ffffff>市委领导</FONT></A> | <A
href="http://www.zgsr.gov.cn/zww/ldxx/rdld.asp"><FONT
color=#ffffff>人大领导</FONT></A> | <A
href="http://www.zgsr.gov.cn/zww/ldxx/zfld.asp"><FONT
color=#ffffff>政府领导</FONT></A> | </FONT><A
href="http://www.zgsr.gov.cn/zww/ldxx/zxld.asp"><FONT
color=#ffffff>政协领导</FONT></A></P></TD>
</TR>
The significative message is市委领导,人大领导 and 政协领导。We can use Regular Expression
TAG "<"[^>]*">" to catch this structure.
But we also find some tag are different from the regular tags :
STYLE tag and SCRIPT tag .
///
<STYLE …> ……….</ STYLE >
< SCRIPT…> ……….</ SCRIPT >
All the thing in the two tags are useless.
We can Regular Expressions to deal with them:
"<SCRIPT"[^>]*">"(.|/n)*"</SCRIPT>"
"<STYLE"[^>]*">"[^<]*"</STYLE>"
Then the data having removed tags is saved as a text file.
2. Label the data using ICTCLAS
I do not modify the ICTCLAS code, I just put the data to ICTCLAS to output result as a text file. I tried to use the ICTCLAS’DLL but I found it does not load the dictionaries, and the preferment is horrible. So that I do not modify the ICTCLAS code (MFC).
The output is like this :
办公室/n :/w 主任/n :/w 林/nr 忠良/nr 办公/vn 电话/n :/w 8223313/m 竞赛/vn 训练/vn 科/n :/w 科长/n :/w 叶/nr 瑞清/nr
The person name is end with “/nr” ,we can see林忠良and叶瑞清 is person name .But ICTCLAS at least I test has a small problem if the name character separate each other.
Source : 办公电话 : 8239521徐 泓 (徐+space+泓)
办公/vn 电话/n :/w 8239521/m 徐/nr 泓/q
It only marks徐.And we find the common case is that the name has only two characters.
The further work may improve that.
3. Extract the person name
In this step is easy to implement. The name is successive end with “/nr”, so that we combine them into the name. We output the person name list as a text file finally.
4. Work synchronously with YACC and general the result
This is the hardest part.
We open two text files ,one is the source one –HTML file ,the other is the name list file .
In yacc the match only phone# and email address. The person name is in the unmatched text.
I use a string buffer to store the test string form unmatched text.
//
char cmpstr[10];
int countcmp=0;
int defindit(int c){
if(countcmp>7)
shift(c);
else
{
cmpstr[countcmp]=c;
countcmp++;
cmpstr[countcmp]='/0';
}
#ifdef DBH
printf("cmpstr=%s/n",cmpstr);
#endif
for(loop=0;loop<NoList;loop++)
{
#ifdef DBH
printf("before strncpm/n");
#endif
k=strncmp(nameList[loop],cmpstr,strlen(nameList[loop])/2*2);
#ifdef DBH
printf("After strncpm %d/n",strlen(nameList[loop])-1);
printf("nameList=%s;/n",nameList[loop]);
printf("k=%d;loop=%d;NoList=%d/n",k,loop,NoList);
// system("pause");
#endif
if(!k) {
#ifdef DBH
printf("find it!");
printf("nameList=%s;/n",nameList[loop]);
printf("cmpstr=%s/n",cmpstr);
system("pause");
#endif
nameorder=loop;
return 1;
}
}
return 0;
}
int shift(int c)
{
char tm[10];
int i=0;
for(i=0;i<7;i++)
tm[i]=cmpstr[i+1];
tm[7]=c;
tm[8]='/0';
#ifdef DBH
printf("tm=%s;/n",tm);
#endif
strcpy(cmpstr,tm);
cmpstr[8]='/0';
}
//
nameList[ ] storing the name list form name list file.
Cmpstr [ ] is the buffer for test string from unmatched text.
We know the one Chinese character occupy two bytes, so we compare the above string at most 8 bytes (four Chinese characters).
//
.|/n {
if(defindit(yytext[0])) {
strcpy(yylval.Name,nameList[nameorder]);
#ifdef DBL
printf("/n--return NAME:%s--/n",yylval.Name);
#endif
return NAME;
}
///
If matched, it return token NAME .
In .y file,
Name often appears in form of Phone# or email address.
For example Name + Phone# (return token sequentially)
Grammar :
Grammar NAME PHONE_NO
|NAME PHONE_NO
In Name list file :
邓国和
黄秋英
胡锦斌
林忠良
叶瑞清
罗晓明
王华
孙玉琪

The Test
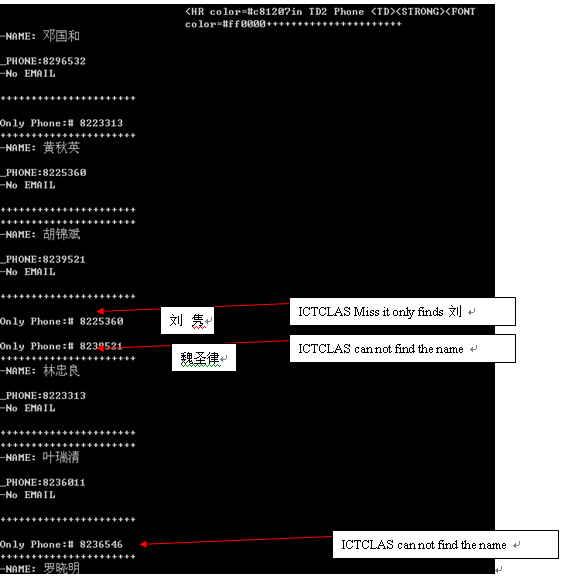
Further work
It only forces on semi-structure web-document. It does not consider the table information.
For extracting Phone# I use the regular expression that Phone# appears after “电话”,it run ok if not text free document ,but text free may imply Phone# without “电话” chinese characters. In this way will get poor precision .















 2321
2321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









