







一、硬件层的并发优化基础知识
1. 存储器的层次结构
L0:寄存器
L1: L1高速缓存(SRAM)
L2: L2高速缓存(SRAM)
L3: L3高速缓存(SRAM)
L4: 主存(DRAM)
L5: 本地二级存储(本地磁盘)
L6: 远程二级存储(分布式文件系统,Web服务器)
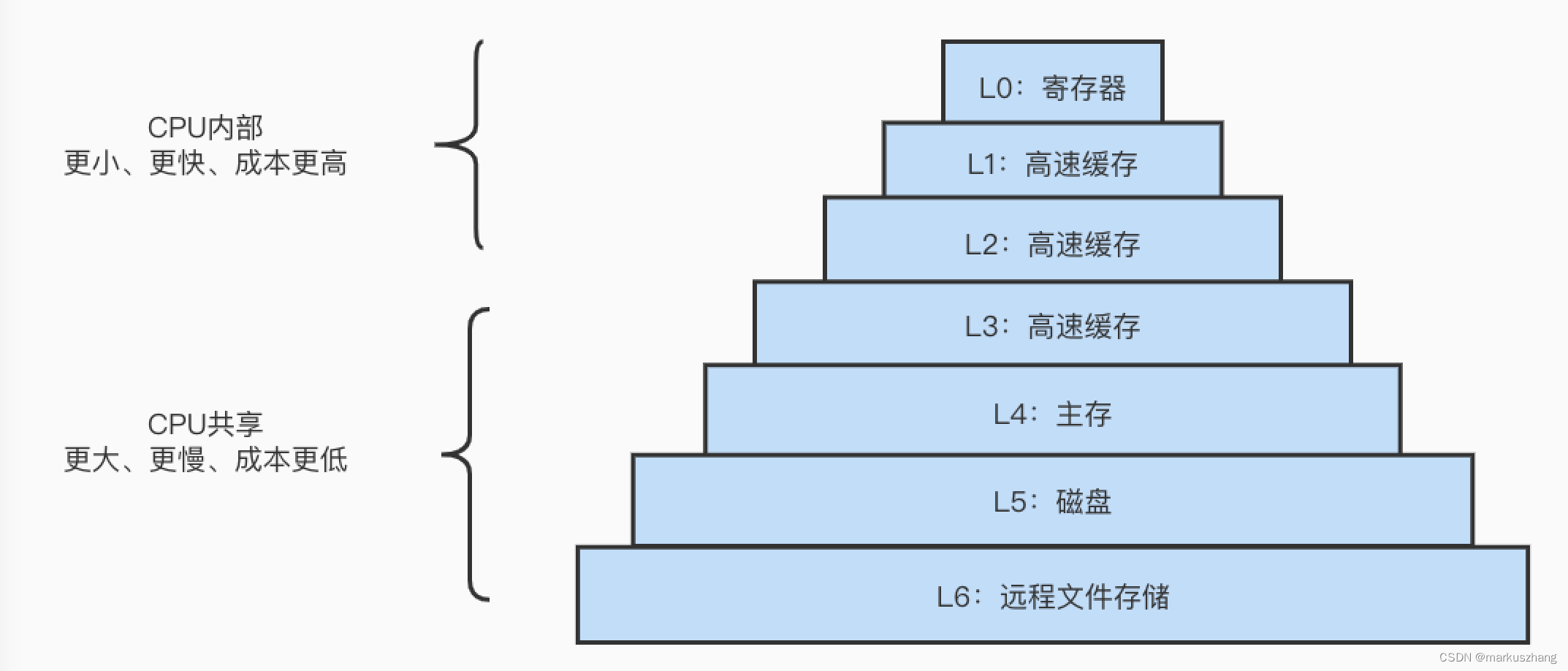
在这个存储结构中,从上至下,设备访问速度越来越慢,容量越来越大,并且每个字节的造价越来越便宜。存储器文件在层次结构中位于最顶部,也就是第0级或L0.
存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存(CPU在读数的时候,会尝试在当前层级缓存获取,如果没有尝试去下一级存储器获取)
正如可以运用不同的高速缓存的知识提高程序性能一样,我们可以利用对整个存储器层次结构的理解来提高程序性能。
2. cache line的概念
对于上面的存储器分布来看,单核处理器可能没什么问题,但是在多核处理器下,多个CPU去读取主存中的某个内容并做修改时则会产生数据不一致的问题。
硬件层如何保证数据一致性
针对上述问题,老的处理器解决方案是使用总线锁锁住总线,但这样会使得其他CPU甚至不能访问内存中的其他的地址,因为会导致效率低下的问题。
新的CPU保证数据一致性采用了各种各样的一致性协议,例如MSI、MESI、MOSI、Synapse、FireFly、Dragon。Intel处理器使用的是MESI数据一致性协议,这里就主要介绍下MESI协议内容。
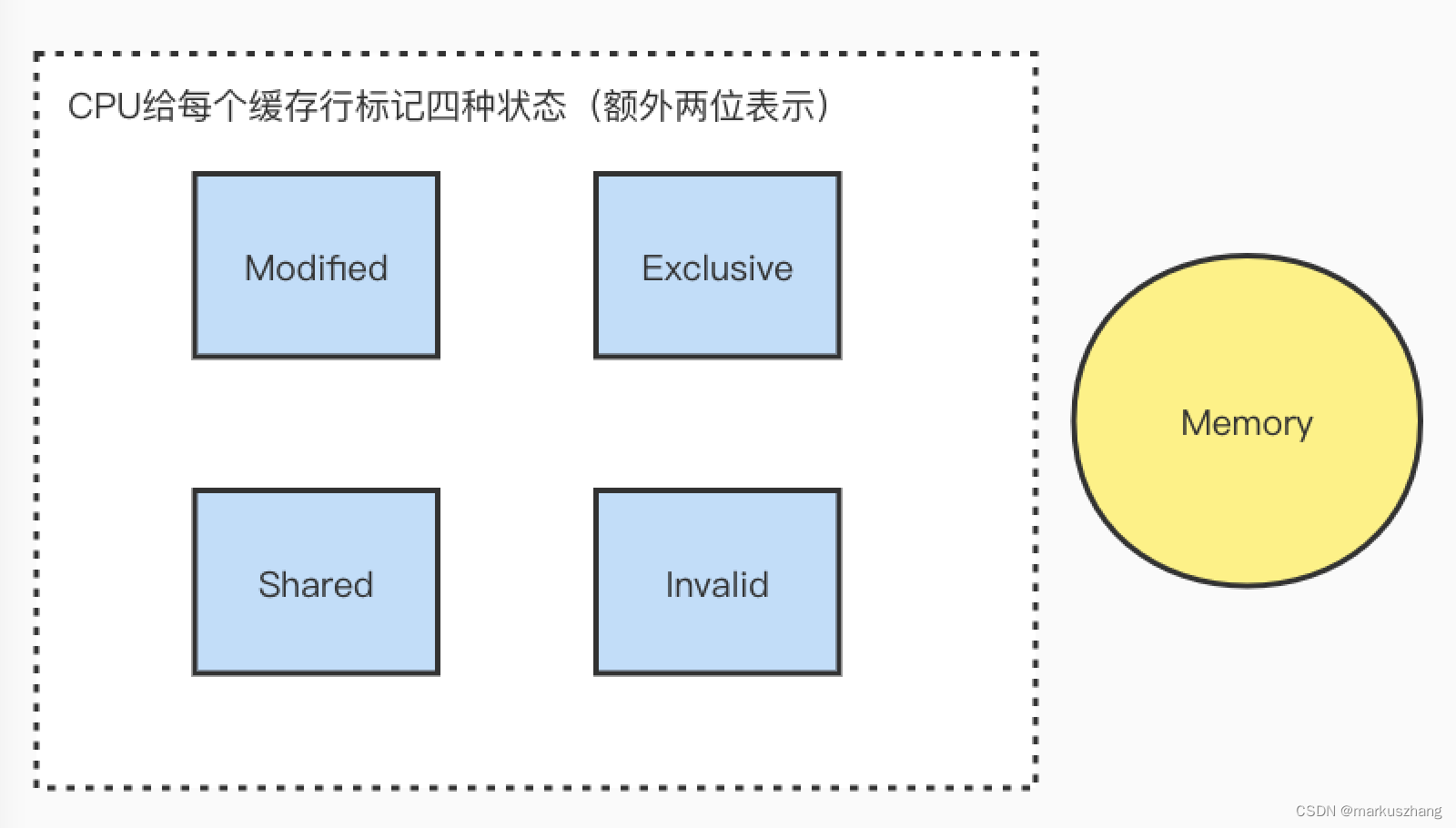
如上图所说,CPU会给每个缓存行标记四种状态,状态的使用场景如下:
- 当前CPU读取该缓存行并修改了其中的内容,则该缓存行为Modified状态,该缓存行中的内存需要在未来的某个时间点(允许其他CPU读取主存中相应内存之前)写回主存,当被写回主存之后,该缓存行的状态会变成Exclusive状态
- 当前CPU读取该缓存行并且其他CPU没有读取,则该缓存行为Exclusive状态,与主存中的数据一致。该状态可以在任何时刻当有其他CPU读取该内存时变成共享状态,同样如果当CPU修改该缓存中内容时,该状态可以变成Modified状态
- 当前CPU读取该缓存行并且其他CPU也读取了,则该缓存行为Share状态,并且数据与主存中的一致,当有一个CPU修改该缓存行中的数据时,其他CPU中改缓存行可以被作废,变成无效状态
- 当前CPU读取该缓存行并且其他CPU修改了该缓存行内容,则该缓存行为Invalid状态,想要使用该缓存行时必须重新从主存中读取一份
但也有些无法使用缓存锁的情况,这些情况必须使用总线锁
-
无法被缓存的数据
-
跨越多个缓存行的数据
所以现代CPU的数据一致性实现是通过:缓存锁(MESI等其他缓存一致性协议)+总线锁实现的
缓存行的概念
CPU在读取主存内容并不是想读取某个值就仅仅读取该值而已,而是以一个缓存行为基本单位从主存中读取数据,这个缓存行的大小一般为64个字节
伪共享
位于同一缓存行的两个不同数据,被两个不同的CPU锁定,产生互相影响的伪共享问题
伪共享问题会影响程序执行的效率,例如主存中有两个数值X、Y,CPU1仅需要X,CPU2仅需要Y,而在CPU各自加载主存数据时可能会将X、Y作为同一缓存行的数据加载到缓存中,在CPU执行程序时如果频繁修改X或Y则会使得彼此频繁地从主存中重新load缓存行,此时也可以使用缓存行对齐技术来优化程序效率。下面使用Java程序来证明这一情况。
- 先来看下没有利用缓存行对齐的情况
package com.markus.java.juc.FalseShare;
/**
* @author: markus
* @date: 2022/9/17 11:58 PM
* @Description: 伪共享
* @Blog: http://markuszhang.com
* It's my honor to share what I've learned with you!
*/
public class CacheLinePadding {
private static class T {
public volatile long x = 0L;
}
// 大概率会被CPU加载到同一个缓存行中
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
Thread r1 = new Thread(() -> {
for (long i = 0; i < 100_0000L; i++)
arr[0].x = i;
});
Thread r2 = new Thread(() -> {
for (long i = 0; i < 100_0000L; i++)
arr[1].x = i;
});
final long startTime = System.nanoTime();
r1.start();
r2.start();
r1.join();
r2.join();
System.out.println(System.nanoTime() - startTime);
}
}
// 多次执行,程序运行时间大概在4000万ns左右
42060042
Process finished with exit code 0
- 再来看下利用缓存行对齐的情况
package com.markus.java.juc.FalseShare;
/**
* @author: markus
* @date: 2022/9/18 12:05 AM
* @Description: 利用缓存行优化程序运行效率
* @Blog: http://markuszhang.com
* It's my honor to share what I've learned with you!
*/
public class CacheLinePaddingOptimize {
private static class T {
private long l1, l2, l3, l4, l5, l6, l7;
public volatile long x = 0l;
private long r1, r2, r3, r4, r5, r6, r7;
}
// 利用缓存行对齐,则arr数组的两个T对象的x值一定不在同一个缓存行中
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
Thread r1 = new Thread(() -> {
for (long i = 0; i < 100_0000L; i++)
arr[0].x = i;
});
Thread r2 = new Thread(() -> {
for (long i = 0; i < 100_0000L; i++)
arr[1].x = i;
});
final long startTime = System.nanoTime();
r1.start();
r2.start();
r1.join();
r2.join();
System.out.println(System.nanoTime() - startTime);
}
}
// 多次执行,程序运行时间大概在1000万-2000万ns左右
13148083
Process finished with exit code 0
3. CPU指令乱序执行
对于现代CPU而言,性能瓶颈则是对于内存的访问。CPU的速度往往都比主存的高至少两个数量级。因此CPU引入了L1_cache、L2_cache,更高级的CPU引入了L3_cache。但这又会引起一个问题,如果CPU要访问的数据不在缓存中,则会依次向下一级缓存中去获取,类推到主存甚至磁盘或者远程文件存储中去获取。并依次存入到经过的主存和缓存中。而在这期间,CPU能够执行成百上千条指令,如果是阻塞等待获取数据后才能执行后续的指令,那CPU的执行效率则会大打折扣,所以CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读取数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系。(CPU一般是依赖指令间的内存引用关系来判断的指令间的独立关系)
- 上述CPU对于读取数据延迟所做的性能补救的方法。
- 对于写场景,则会显得复杂一些,CPU在执行存储指令时,它会试图将数据写到离CPU最近的L1_cache中,如果此时CPU出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和CPU持平,其他的均明显低于CPU,L2_cache大约比CPU慢20-30倍,而且还存在L2未命中的场景,那么则会需要更多的周期去下一级缓存或主存中获取数据。为解决此类性能问题,CPU在L1未命中时会将数据写入一个WCBuffer区域,即合并写缓冲区。缓冲区的大小与缓存行大小一致,一般为64字节。一般的CPU能够同时获取4个,也就是说可以同时满足4个缓存行数据未命中L1时被写入到此,缓冲区满了之后,便会将数据写入L2_cache中,在CPU写入或读取缓冲区数据期间允许执行其他指令,这就缓解了CPU写数据时cache miss时的性能影响
作为软件开发人员来讲,可能对于硬件相关信息不太了解,但我们可以通过下面一段程序来证明缓冲区的存在,在展示程序之前先说一个小插曲
笔者在阅读资料的时候,大多数资料都是介绍intel处理器,并且给出相应的程序,当我将这些程序在M1处理器的MAC上运行时,发现了不一样的现象,似乎并没有性能影响。
对于产生的现象,笔者又阅读部分资料,分析出原因所在(可能有误)
- intel L1_cache大小在4KB到64KB之间;M1 L1_cache大小在128KB,这在一定程度上造成了M1 L1_cache缓存命中率要比intel高,所以程序带来的性能差距并不大
- 所以笔者将测试的数组从byte类型变为int类型,再变为long类型,性能则逐渐展示出来
好了,我们开始看程序
package com.markus.java.juc.cpu.wc;
/**
* @author: markus
* @date: 2022/9/18 4:17 PM
* @Description: 合并写
* @Blog: http://markuszhang.com
* It's my honor to share what I've learned with you!
*/
public class WriteCombine_int {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static int arrayA[];
private static int arrayB[];
private static int arrayC[];
private static int arrayD[];
private static int arrayE[];
private static int arrayF[];
private static int arrayG[];
private static int arrayH[];
static {
arrayA = new int[ITEMS];
arrayB = new int[ITEMS];
arrayC = new int[ITEMS];
arrayD = new int[ITEMS];
arrayE = new int[ITEMS];
arrayF = new int[ITEMS];
arrayG = new int[ITEMS];
arrayH = new int[ITEMS];
}
public static void main(String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ms) = " + runCaseOne() / 100_0000);
System.out.println(i + " SplitLoop duration (ms) = " + runCaseTwo() / 100_0000);
}
}
private static double runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
int b = i;
// 以下不在同一个缓存行中
// 相当于载入8个缓存行
// 而现代CPU基本上 单核可以同时获取4个缓存行存储合并缓冲区中
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
arrayG[slot] = b;
arrayH[slot] = b;
}
return System.nanoTime() - start;
}
private static double runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
int b = i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
int b = i;
arrayE[slot] = b;
arrayF[slot] = b;
arrayG[slot] = b;
arrayH[slot] = b;
}
return System.nanoTime() - start;
}
}
看到上面的程序,我们可能会说runCaseOne的执行速度要比runCaseTwo快,因为runCaseOne只进行一次循环,而runCaseTwo执行了两次。实际上并不是这样,其实runCaseTwo更快,这样一个现象就可以证明在L1_cache与L2_cache之间有合并缓冲区的存在,既然它存在,那为什么要runCaseOne执行的慢呢?因为一般CPU只会获取4个缓冲区,如果这些缓冲区被写满之后,CPU就必须等待缓冲区将数据写入到Cache中之后才会向下执行指令,如果每次写入的都是4个不同位置的内存,则可以很好的利用合并写缓冲区,因合并写缓冲区满引起的CPU暂停次数会大大减少。对于多的一次i++循环操作,i是被写入到寄存器的。所以说虽然多了一次循环操作,但是相比于写入L2_cache所导致的20-30倍的影响来看,他们之间性能差距依然非常大。我们来看下程序运行结果:
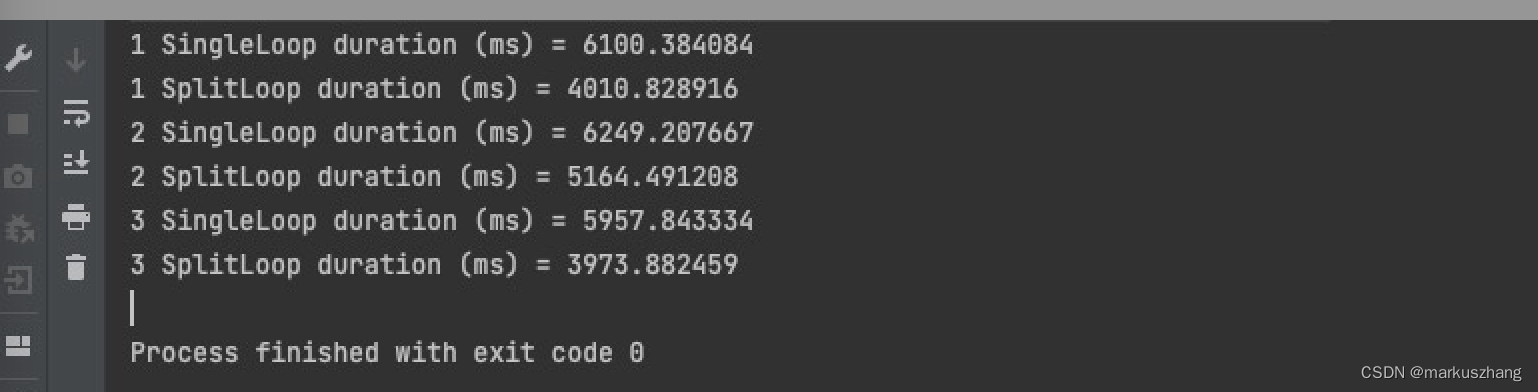
当我们将int类型变为long类型时,差距则会扩大,看下程序运行结果图:
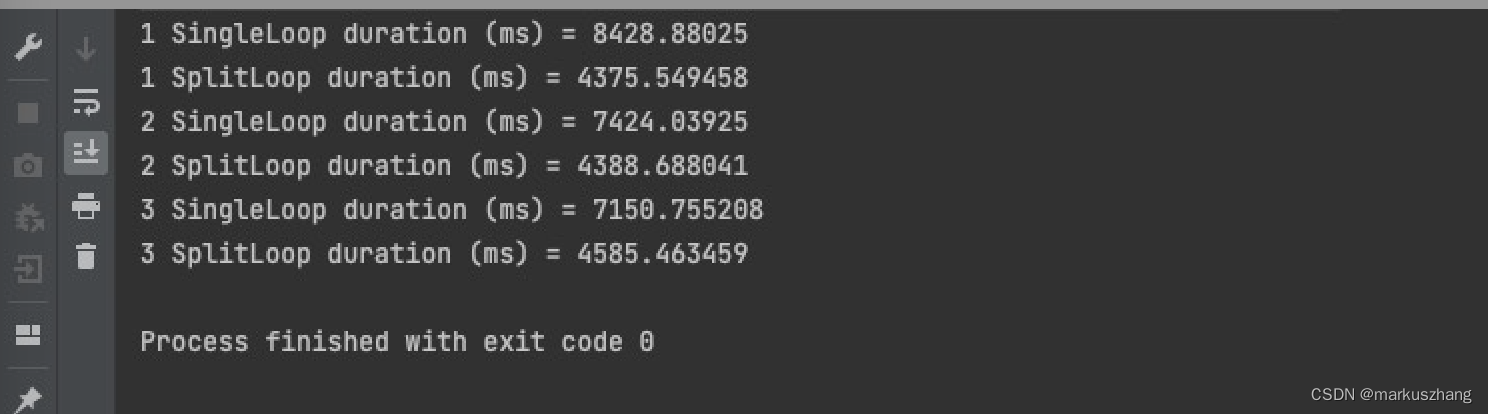
上边说到CPU为了读写数据延迟而进行将不想关的指令进行乱序执行,那怎么证明呢?我们看下面这段程序:
package com.markus.java.jvm;
/**
* @author: markus
* @date: 2022/9/18 10:14 PM
* @Description: 指令乱序执行证明
* @Blog: http://markuszhang.com
* It's my honor to share what I've learned with you!
*/
public class Disorder {
private static int a = 0, b = 0;
private static int x = 0, y = 0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for (; ; ) {
i++;
x = 0;
y = 0;
a = 0;
b = 0;
Thread t1 = new Thread(() -> {
a = 1;
x = b;
});
Thread t2 = new Thread(() -> {
b = 1;
y = a;
});
t1.start();
t2.start();
t1.join();
t2.join();
if (x == 0 && y == 0)
break;
}
System.out.println("第" + i + "次执行,(x,y)结果为:(" + x + "," + y + ")");
}
}
分析上面程序,如果说CPU是按顺序进行执行的,那么xy的值不可能同时为0,因为在x、y分别进行赋值前,都已经进行了a=1 or b=1,所以说xy的组成情况只可能为(0,1) (1,0) (1,1)。执行上面程序会发现,会有(0,0)情况的出现,所以说CPU进行了指令重排,我们看下程序运行结果图:

4. 硬件级别的有序性保障
我们以intel的x86处理器为例,它内部指令是如何保证有序性的
CPU内存屏障
- sfence:在sfence指令前的写操作必须在sfence指令后的写操作前完成
- lfence:在lfence指令前的读操作必须在lfence指令后的读操作前完成
- mfence:在mfence指令前的读写操作必须在mfence指令后的读写操作前完成
- lock汇编指令:原子指令,是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
再来看下JVM规范下的JVM级别内存屏障,它只是一个规范,具体实现还是依赖于相应的处理器实现
- LoadLoad屏障:屏障前后均是读操作
- StoreStore屏障:屏障前后均是写操作
- LoadStore屏障:屏障前后是读、写操作,读要先于写操作前完成
- StoreLoad屏障:屏障前后是写、读操作,写要先于读操作前完成















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









