







-
发展背景:
- 互联网技术迅猛发展→ 信息爆炸→ 信息超载
- 互联网上的物品普遍存在长尾(long tail)现象
-
推荐系统:
- 一种主动的信息过滤系统
- 将信息过滤过程由“用户主动搜索”转变为“系统主动推送”
- 一种个性化的双边匹配系统
- 帮助用户发现其所喜好的或需要的小众、非主流商品
- 帮助商户将其商品展现在对它们感兴趣的用户面前
- 一种主动的信息过滤系统
-
个性化推荐系统框架
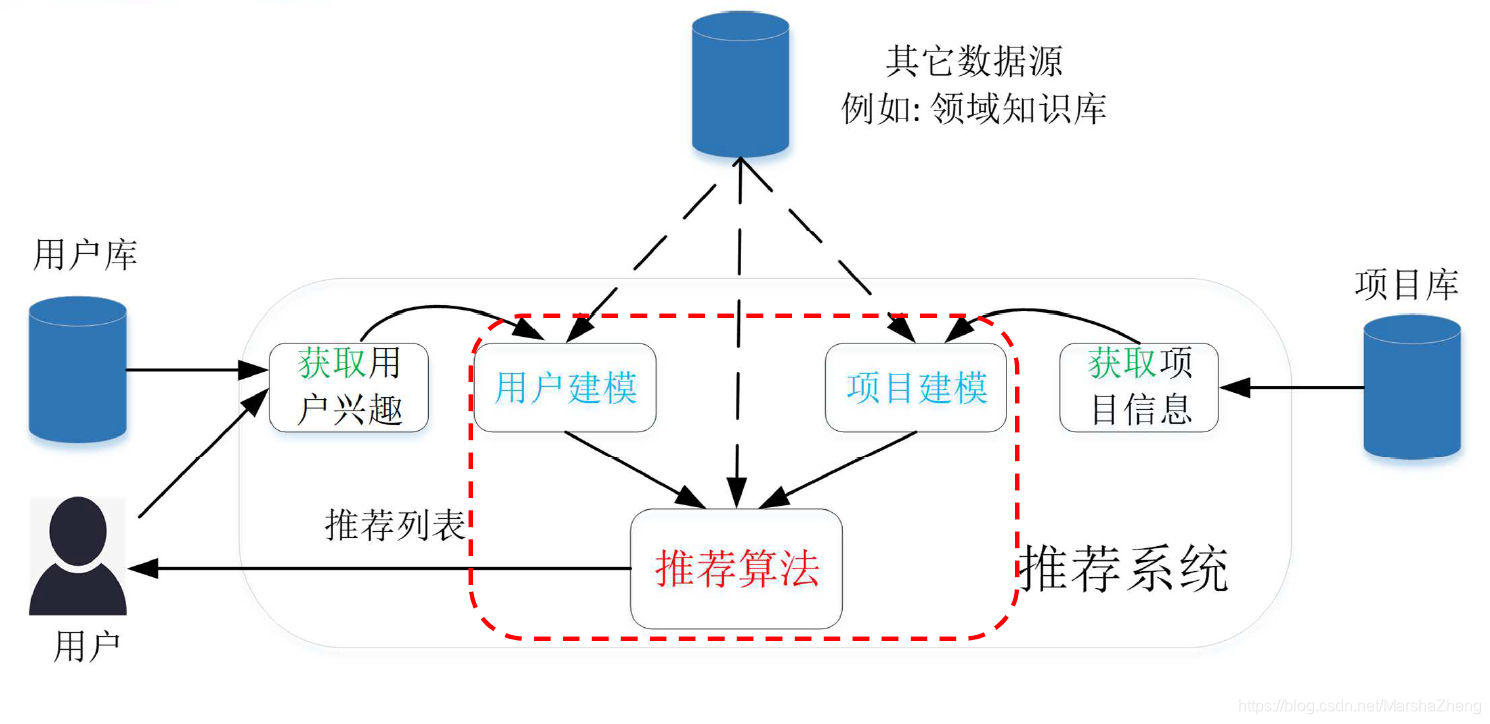
-
个性化推荐
- 映射函数f:U×I→R
- 输入:
- 用户画像(U):评分、偏好、人口统计学资料、上下文等
- 项目画像(I):项目描述(属性)、内容等
- 计算:兴趣度或相关度(R),用于排序
- 输出:针对每个用户,给出项目排序列表
-
用户画像
- 对用户的特点和兴趣进行建模
- 从用户相关的各种数据中挖掘或抽取出用户在不同属性上的标签
- 例如:年龄、性别、职业、婚姻状态、兴趣、未来可能行为等
- 主要过程:
- 标签体系的建立:层次化结构,逐层细分
- 标签的获取(赋值):
- 事实标签:既定事实,可从原始数据中直接得到,如:性别
- 模型标签:用户潜在特性,通过模型计算得出,如:用户兴趣
- 预测标签:对用户未来行为的预测,例如:用户流失预测
- 对用户的特点和兴趣进行建模
-
项目画像
- 对项目的特点进行建模
- 从项目相关的各种数据中挖掘和抽取出项目在不同属性上的标签
- 实现对项目(例如商品、服务等)的精准的定位
- 项目画像的过程和用户画像相同
- 标签体系的建立(需要领域知识) 和标签的获取(赋值)
- 项目标签:
- 项目自身内容和属性相关的标签
- 和用户(行为)相关的一些标签,例如:目标用户群
- 对项目的特点进行建模
-
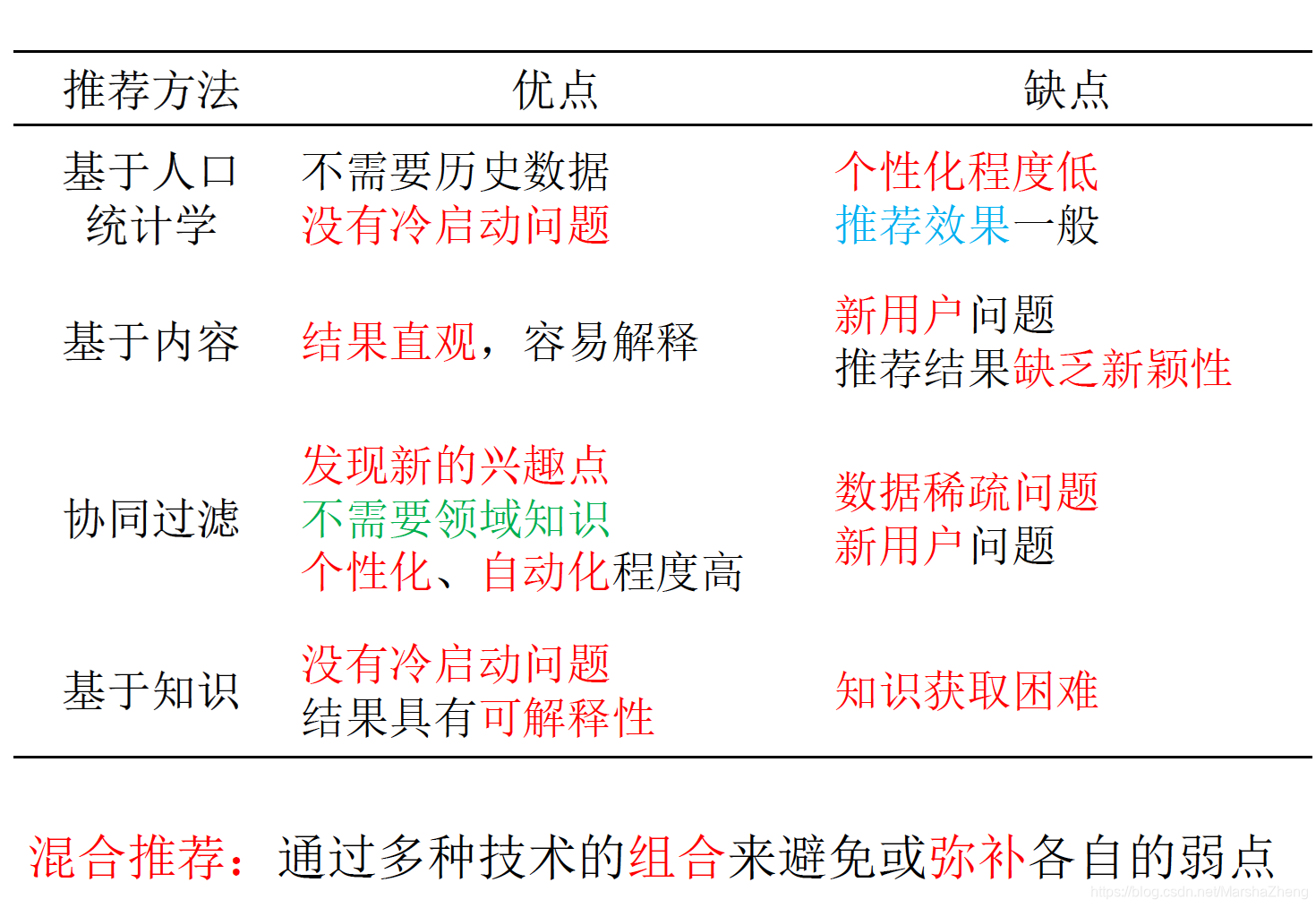
基于算法思想的分类
- 基于人口统计学、基于内容、协同过滤、基于知识的推荐
- 基于人口统计学:根据用户基本信息推荐相似用户喜爱的项目
- 基于内容:根据用户过去喜好的项目推荐相似的项目
- 协同过滤:根据用户行为信息推荐相似用户喜爱的项目
- 基于知识:根据用户的显式需求和专业领域知识进行推荐
- 基于人口统计学、基于内容、协同过滤、基于知识的推荐
- 基于应用问题的分类
- 评分预测
- 目标:根据用户历史评分和其他相关数据,预测用户对候选项目评分值
- 评价指标:预测评分和真实评分之间的偏差,例如:均方根误差RMSE
- Top-N推荐
- 目标:根据用户历史行为(如:点击)和其他相关数据,预测用户对候选项目的感兴趣程度,并据此对项目排序以给出排在最前N个的项目列表
- 评价指标:
- 分类准确度和排序合理性,例如:精确度、召回率、AUC、nDCG等
- 评分预测


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









