







什么是网络爬虫?
- 别名:网页蜘蛛,网络机器人
- 定义:按照一定规则,自动抓取万维网信息的程序或脚本. 在网络上爬行的一只蜘蛛
如何用python3写爬虫?
基础知识
- urllib
- 正则表达式
- python爬虫框架Scrapy
urllib
获取一个网页的源码
#!/usr/bin/env python3
import urllib, urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
print response.read().decode('uft-8's) #!/usr/bin/env python3
import urllib, urllib.request
req = urllib.request.Request("http://www.baidu.com")
response = urllib.request.urlopen(req)
print response.read().decode('uft-8's)上面第二种写法保存了中间结果req
urlencode: 字典转换为url格式
>> import urllib.parse
>> data = {}
>> data['word']='John Smith'
>> urllib.parse.urlencode(data)
'word=John+Smith'deque
导入模块
from collections import deque初始化
queue = deque(['John', 'Bush', 'Frank'])入队列
queue.append('Ken')出队列
queue.popleft()
集合运算
| 表达式 | 含义 |
|---|---|
| a & b | a交b |
| a | b | a并b |
| a - b | 在a中,且不在b中 |
| a ^ b | 不同时在a和b中 |
字典和集合的 {}
- 字典:
- 空字典: dic = {}
- 集合:
- 空集合: mySet = set(), 如果用 {}就成字典了
GET与POST
- GET: 链接中包含了所有的参数,使得传输到信息不是很安全
- POST: 不会在网址上显示所有的参数, 信息包含在一个data结构里面
Charles
- 在Mac上学习和分析http可以用Charles.
- 我们的爬虫需要伪装成浏览器,通过Charles可以查看我们的请求报文
#!/usr/bin/env python3
import urllib.request
url = 'http://www.baidu.com/'
req = urllib.request.Request(url, headers = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
})
urlop = urllib.request.urlopen(req)通过Charles查看request报文
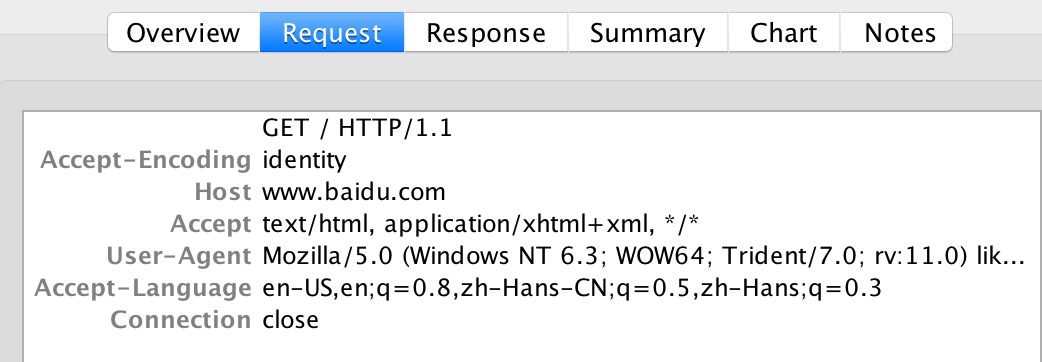
方法
下载图片
# python3
localSavePath = "/Users/Smith/Picture/"
def downloadPicture(url):
pattern = r'http://\w+?\.(jpg|png)'
match = re.search(pattern, url)
if match:
filename = localSavePath + match.group()
urllib.request.urlretrieve(url, filename)动手实践
下面我从一个起始页面开始爬,只要发现jpg格式的图片就把它保存起来。
- 发现一个新链接,保存到queue中
- 已经访问过的页面,保存到visited集合中,防止重复访问
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import urllib.request
import re
from collections import deque
localSavePath = "/Users/Smith/Downloads/Pictures/"
queue = deque()
visited = set()
initialPage = 'http://www.nipic.com/show/1/47/7221511k2490d687.html'
queue.append(initialPage)
cnt = 0
#下载图片
def downloadPicture(url):
print('download --> ' + url)
pattern = r'/[^/]+?\.jpg'
match = re.search(pattern, url)
if match:
filename = localSavePath + match.group()
urllib.request.urlretrieve(url, filename)
while queue:
url = queue.popleft()
visited |= {url}
print('cnt: ' + str(cnt) + ' <---- ' + url)
cnt += 1
#设置退出条件
if cnt > 85:
exit(0)
try:
urlop = urllib.request.urlopen(url, timeout=5)
except:
print('error open: ' + url)
continue
if 'html' not in urlop.getheader('Content-Type'):
print('not html')
continue
try:
data = urlop.read().decode('utf-8')
except Exception as e:
print(e)
continue
#for循环中给queue添加新链接,或者保存图片
for item in re.findall('\"(.+?)\"', data):
if re.match(r'http://.+?\.jpg', item):
downloadPicture(item)
elif 'http' in item and item not in visited:
queue.append(item)先到这里吧,留几个问题下次再解决:
- 本例中只下了jpg图片,如果jpeg, png, gif等格式也要下,应该如何修改正则表达式?
- 只有
width > 400 and height > 400的图片才下载,该如何处理? - 写一个12306的登录程序















 4258
4258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









