






文章目录
一、单链表
1顺序表的优缺点
缺点:
- 插入数据必须移动其他数据,最坏情况下,就是插入到n位置,时间复杂度为O(n)。
- 删除数据也需要移动数据,最坏情况下,就是删除n位置,时间复杂度为O(n)。
- 但顺序表满时再插入一个元素就会扩容,但是若添加的元素少于扩容的空间数量,就会造成浪费。
优点:
在给定下标进行查找时,时间复杂度为O(1)。
总结:顺序表比较时候在给定下标的时候进行查找。
2链表的构成
首先要明白:
- 链表在逻辑上是连续的,在物理上不一定连续。
- 现实中的结点一般都是从堆上申请出来的。
- 从堆上申请的空间,是按照一定的策略来分配的。两次申请的空间可能连续,也可能不连续。
链表是由一个个结点组成,而这些结点又是由数据域和next域构成(双向链表还会多一个prev域)。
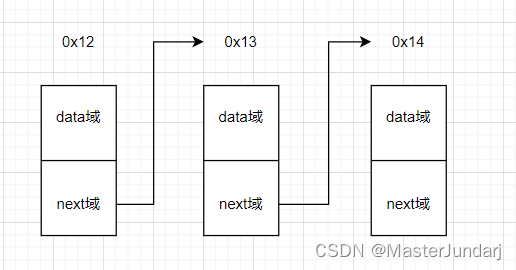
其中,data域存放数据,next域存放下一个结点的地址(prev域则存放前一个结点的地址)。
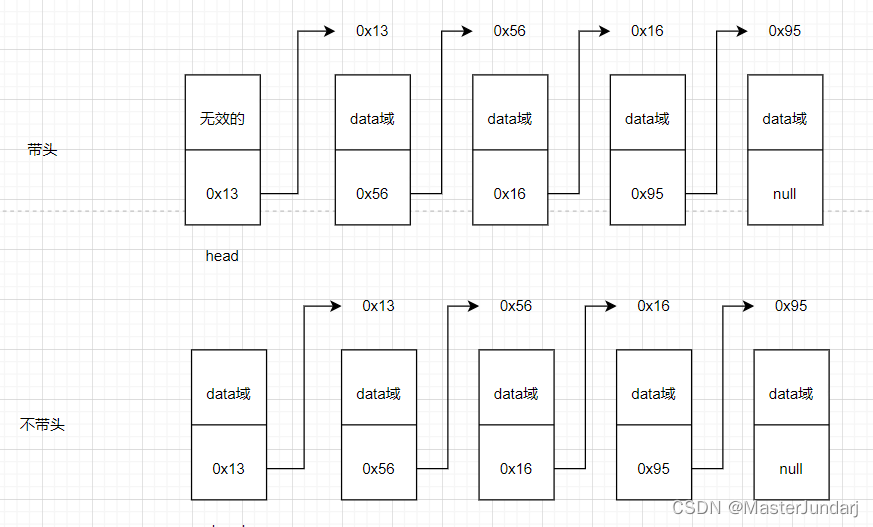
链表的几种组成方式
分别是:单项/双向带头循环、单项/双向不带头循环、单项/双向带头非循环、单项/双向不带头非循环。
什么是“头”?
“头”,就是头节点的意思,它的组成如图:
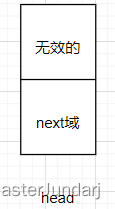
头节点的data域是不存放元素的。
至于带不带头可以简单理解为有人驾驶的列车和无人驾驶的列车,有人驾驶的列车不能在火车头前面加车厢,第一节车厢永远是驾驶室;而无人驾驶的列车则可以在最前面加车厢,哪节车厢在最前面哪节就是头。即head只是用来标识。
什么是循环?
判断是不是循环就看最后一个结点的next域存放的是null还是第一个结点的地址。
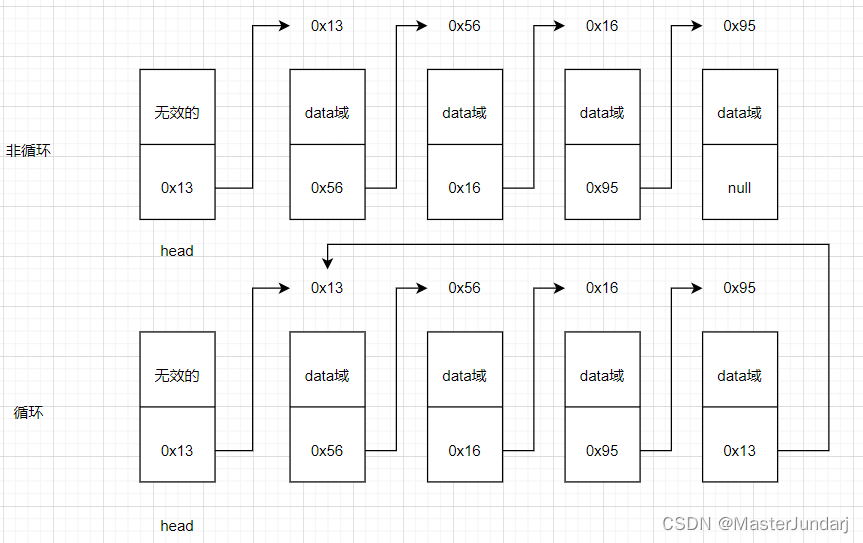
此处主要演示单项不带头非循环链表。
3、低层逻辑
3.1、定义接口并实现
public interface ILinked {
//头插法
void addFirst(int data);
//尾插法
void addLast(int data);
//任意位置插入,第一个数据节点为0号下标
void addIndex(int index,int data);
//查找是否包含关键字key是否在单链表当中
boolean contains(int key);
//删除第一次出现关键字为key的节点
void remove(int key);
//删除所有值为key的节点
void removeAllKey(int key);
//得到单链表的长度
int size();
void clear();
void display();
}
class MySecendLink implements ILinked{
static class ListNode {
private int val;
private ListNode next;
public ListNode(int val) {
this.val = val;
}
}
private ListNode head;
@Override
public void addFirst(int data) {
}
@Override
public void addLast(int data) {
}
@Override
public void addIndex(int index, int data) {
}
@Override
public boolean contains(int key) {
return false;
}
@Override
public void remove(int key) {
}
@Override
public void removeAllKey(int key) {
}
@Override
public int size() {
return 0;
}
@Override
public void clear() {
}
@Override
public void display() {
}
}
【解释】
- **为什么用内部类:**因为一个链表是由若干个结点组成,而结点又是由data域和next域组成,符合内部类的定义:外部类由若干完整的类组成,那么可以定义这些类为内部类。static修饰是方便直接通过类名调用。
- 为什么next用
ListNode修饰:因为next所指向的是下一个结点的地址,而结点始终是ListNode类型。 - 为什么ListNode的构造方法没有next?:因为这个构造方法是为了初始化结点往结点的data域存放元素,而我们根本不知道它的下一个是谁,next默认为null。
- **为什么head单独拿出来?:**因为head属于链表的特征而不是结点的。
3.2、display方法
思路:从头结点开始遍历,若该结点不等于null就打印输出该结点的元素。
问题:
- 怎么从一个结点走到下一个结点?:head = head.next;
- 怎么判断所有结点都已经走完了?:head= null;
@Override
public void display() {
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
【解释】:为什么创建一个cur代替head:如果直接用head遍历那么当打印输出结束后head就为null,相当于链表就空了,因此用cur代替head。
3.3、size方法
思路:定义一个计数器,从头开始遍历链表,每走一个结点计数器加一,最后返回计数器结果。
@Override
public int size() {
ListNode cur = this.head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
3.4contain方法
思路:遍历链表,每走一步判断结点的元素是否等于key,等于则直接返回true,若遍历完成仍没有则返回false
@Override
public boolean contains(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
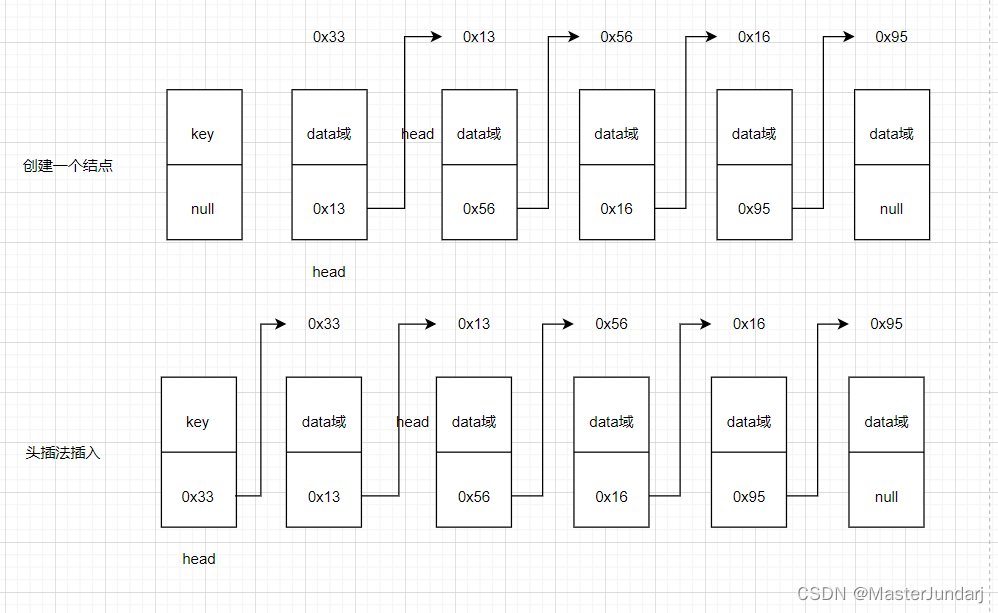
3.5addFirst方法
思路:
- 创建一个结点
- 改变插入结点的next域
- 改变head
@Override
public void addFirst(int data) {
ListNode node = new ListNode(data);
if (head == null) {
this.head = node;
}else {
node.next = this.head;
this.head = node;
}
}
3.6addLast方法
思路:
- 实例化一个结点
- 找到最后一个结点cur
- cur.next = node;

@Override
public void addLast(int data) {
ListNode node = new ListNode(data);
if (head == null) {
this.head = node;
}else {
ListNode cur = this.head;
while (cur.next != null) {//cur.next代表走到最后一个元素
cur = cur.next;
}
cur.next = node;
}
}
3.7addIndex方法
思路:实例化一个结点,让index位置前一个结点next指向该结点,该结点的next指向index位置的结点。

问题:**如何获取index位置前一个结点?:**不能像之前一样直接让cur走到index位置,因为单向链表无法获取前一个结点的信息。
解决:cur走到index-1步,然后:
node.next = cur.next;
cur.next = node;
注意:必须先绑定后面的结点再绑定前面的结点,若
cur.next = node;
node.next = cur.next;
因为此时cur.next已经变成了node自己,所以会出现node自己绑定自己。

代码实现:
查找index-1位置
private ListNode SearchPrev(int index) {
ListNode cur = this.head;
int count = 0;
while (count != index-1) {
cur = cur.next;
count++;
}
return cur;
}
addIndex
@Override
public void addIndex(int index, int data) {
ListNode node = new ListNode(data);
//判断index的合法性
if (index < 0 || index > size()) {
throw new IllegalIndex("下标不合法!");//自定义异常
}
if (index == 0) {
addFirst(data);
}else if (index == size()) {
addLast(data);
}else {
ListNode cur = SearchPrev(index);
node.next = cur.next;
cur.next = node;
}
}
3.8remove方法
思路:如果链表为空,则返回“链表为空”;如果链表没有对应的元素则返回“没找到对应的元素”;如果找到了:
前一个结点的next指向删除结点del的next。
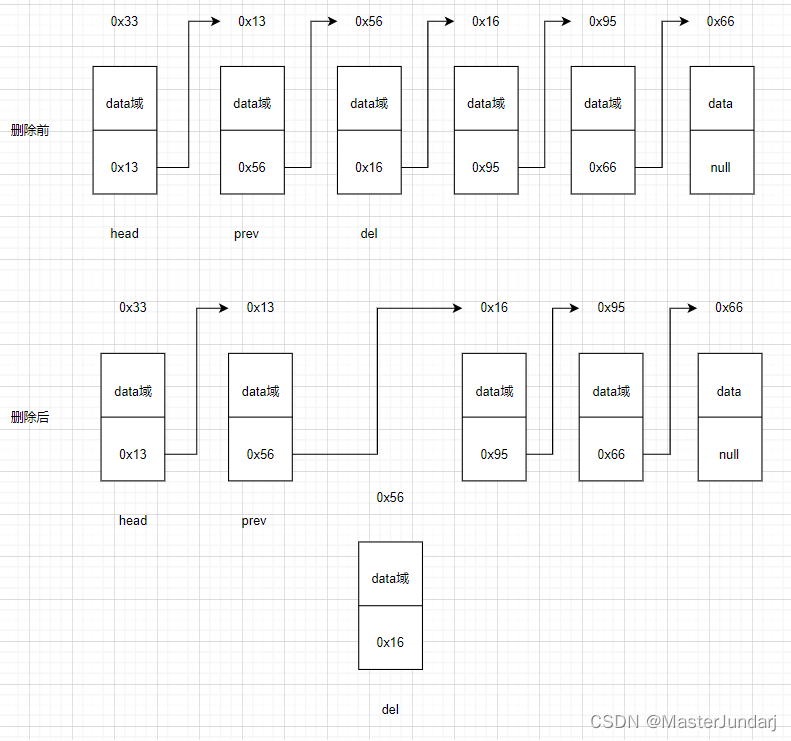
问题:如何查找前一个结点?
private ListNode findPrev(int key) {
ListNode cur = this.head;
while (cur.next != null) {
if (cur.next.val == key) {
return cur;
}
cur = cur.next;
}
return null;
}
@Override
public void remove(int key) {
if (this.head == null) {
System.out.println("链表为空,无法删除!");
}
if (this.head.val == key) {
this.head = this.head.next;
return;
}
//找到前驱
ListNode PrevNode = findPrev(key);
//判断是否为空
if (PrevNode == null) {
System.out.println("没有你要删除的元素.");
return;
}
//删除元素
ListNode del = PrevNode.next;
PrevNode.next = del.next;
}
3.9removeAllKey方法
这种最简单易想到的做法是直接遍历链表当结点元素满足要求就删除,但是这样遍历链表再加上查找前驱结点,时间复杂度就很高了。怎么把时间复杂度控制在O(n)呢?
思路:定义两个结点:
ListNode prevNode = this.head;
ListNode cur = this.head.next;
当结点元素等于要删除的数据时删除结点,否则
prevNode = cur;
cur = cur.next;
代码实现:
@Override
public void removeAllKey(int key) {
if (this.head == null) {
return;
}
ListNode prevNode = this.head;
ListNode cur = this.head.next;
while (cur != null) {
if (cur.val == key) {
prevNode.next = cur.next;
cur = cur.next;
}else {
prevNode = cur;
cur = cur.next;
}
}
if (head.val == key) {
this.head = this.head.next;
}
}
3.10clear方法
思路,把每个结点都制空
@Override
public void clear() {
ListNode cur =head;
while (head != null) {
ListNode curNext = cur.next;
//cur.val = null 引用数据类型加上这句
cur.next = null;
cur = curNext;
}
head = null;
}
二、双向链表
1、双向链表与单向链表的区别
双向链表相对于单链表多了一个前驱结点prev存放前一个结点地址和尾结点last
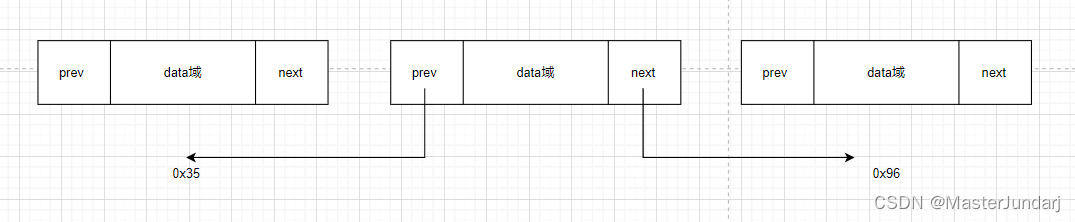
这个因为多了个前驱节点,双向链表在实现各种方法时的时间复杂度相对于单链表更低
2、双向链表的低层逻辑实现
2.1定义接口并实现
因为双向链表的各方法实现与单向链表大致相同且有些更为简单,所以就不一一细讲了
public interface IDoubleLink {
//头插法
void addFirst(int data);
//尾插法
void addLast(int data);
//任意位置插入,第一个数据节点为0号下标
void addIndex(int index,int data);
//查找是否包含关键字key是否在单链表当中
boolean contains(int key);
//删除第一次出现关键字为key的节点
void remove(int key);
//删除所有值为key的节点
void removeAllKey(int key);
//得到单链表的长度
int size();
void clear();
void display();
}
public class MyDoubleLinked implements IDoubleLink{
static class ListNode {
private ListNode next;
private ListNode prev;
private int val;
public ListNode(int val) {
this.val = val;
}
}
private ListNode head;
private ListNode last;
@Override
public void addFirst(int data) {
ListNode node = new ListNode(data);
if (this.head == null) {
this.head = node;
this.last = head;
}else {
node.next = this.head;
this.head.prev = node;
}
}
@Override
public void addLast(int data) {
ListNode node = new ListNode(data);
if (this.last == null) {
this.head = node;
this.last = head;
}else {
this.last.next = node;
node.prev = this.last;
}
}
@Override
public void addIndex(int index, int data) {
ListNode node = new ListNode(data);
if (index < 0 || index > size()) {
throw new IllegalIndex("输入的下标不在范围内.");
}
ListNode cur = this.head;
int count = 0;
if (index == 0) {
addFirst(data);
} else if (index == size()) {
addLast(data);
}else {
while (index-1 != count) {
cur = cur.next;
count++;
}
node.next = cur.next;
cur.next.prev = node;
cur.next = node;
node.prev = cur;
}
}
@Override
public boolean contains(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
@Override
public void remove(int key) {
if (this.head == null) {
System.out.println("没有元素删除!");
return;
}
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
return;
}
cur = cur.next;
}
System.out.println("没有你要删除的数据!");
}
@Override
public void removeAllKey(int key) {
ListNode cur =this.head;
while (cur != null) {
if (cur.val == key) {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
cur = cur.next;
}
}
@Override
public int size() {
ListNode cur = this.head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
@Override
public void clear() {
ListNode cur =head;
while (head != null) {
ListNode curNext = cur.next;
//cur.val = null 引用数据类型
cur.next = null;
cur = curNext;
}
head = null;
}
@Override
public void display() {
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
}
三、LinkedList的使用
1、什么时linkedlist
LinkedList的底层是双向链表结构(链表后面介绍),由于链表没有将元素存储在连续的空间中,元素存储在单独的节
点中,然后通过引用将节点连接起来了,因此在在任意位置插入或者删除元素时,不需要搬移元素,效率比较高。
在集合框架种,LinkedList也实现了List接口:
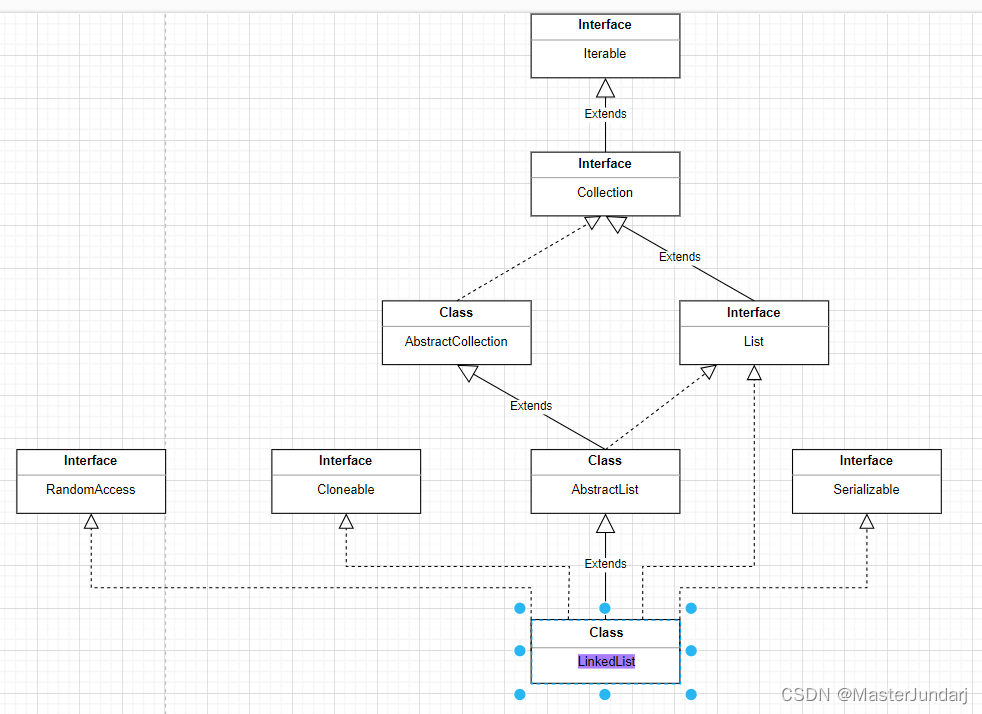
【说明】
- LinkedList实现了List接口。
- LinkedList的低层使用了双向链表。
- LinkedList没有实现RandomAccess接口,因此LinkedList不支持随机访问。
- LinkedList的任意位置插入和删除数据的效率都很高,时间复杂度为O(1)。
- LinkedList比较适合任意位置插入的场景。
2、LinkedList的使用
2.1、LinkedList的构造方法
| 方法 | 解释 |
|---|---|
| Linkedlist(); | 无参构造 |
| public LinkedList(Collection<? extends E>C) | 使用其他集合容器中元素构造List |
public static void main(String[] args) {
// 构造一个空的LinkedList
List<Integer> list1 = new LinkedList<>();
List<String> list2 = new ArrayList<>();
list2.add("JavaSE");
list2.add("JavaWeb");
list2.add("JavaEE");
// 使用ArrayList构造LinkedList
List<String> list3 = new LinkedList<>(list2);
}
2.2、LinkedList其他常用方法
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection<? extends E> c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List subList(int fromIndex, int toIndex) | 截取部分 list |
2.3、LinkedList的遍历
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
list.add(1);//add(elem)表示尾插
list.add(2);
list.add(3);
list.add(4);
list.add(5);
System.out.println(list.size());
//foreach遍历
for (int e:list) {
System.out.print(e + " ");
}
System.out.println();
//使用迭代器遍历——正向遍历
ListIterator<Integer> it = list.listIterator();
whiel (it.hasNext()) {
System.out.print(it.next+" ");
}
//使用迭代器遍历——反向遍历
ListIterator<Integer> rit = list.listIterator(list.size());
while (rit.hasPrevious()) {
System.out.print(rit.previous()+" ");
}
System.out.println();
}
3 、ArrayList和LinkedList的区别
| 不同点 | ArrayList | LinkedList |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持,O(1) | 不支持:O(n) |
| 头插 | 需要搬移元素,效率低:O(n) | 只需修改引用的指向:O(1) |
| 尾插 | 空间不够时需要扩容 | 没有容量概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









