






关于关联规则的原理,具体不在这里多说,已经有很多文章详细介绍原理内容,下面是一个关联规则的实例。希望大家可以用来学习关联规则。
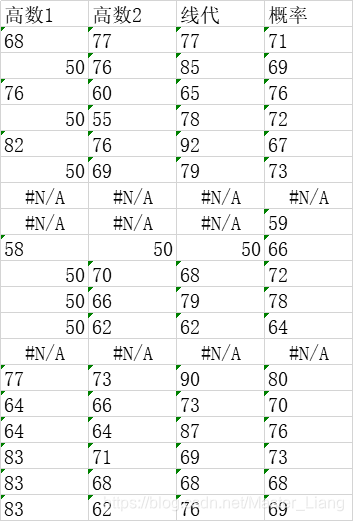
成绩数据
高数1 高数2 线代 概率
68 67 77 71
50 76 85 69
76 60 75 56
50 55 78 82
82 76 92 97
50 69 79 73
#N/A #N/A #N/A #N/A
#N/A #N/A #N/A 59
58 60 50 66
50 70 68 72
50 66 79 78
50 62 62 64
#N/A #N/A #N/A #N/A
77 73 80 80
64 56 73 70
64 64 87 76
83 71 79 73
83 88 68 98
83 62 76 69
# _*_ coding: utf-8 _*_
import xlrd
#读取表格文件数据
def read_excel():
with xlrd.open_workbook('F:\慕课学习文档资料\data mining\学生成绩(高数、线代、概率).xls','rb')as workbook:
sheet_name = workbook.sheet_names()[0]
host_sheet = workbook.sheet_by_name(sheet_name)
rows = host_sheet.nrows
return host_sheet, rows
# 选取数据
def read_data(host_sheet, rows):
host_data = []
for row in range(rows):
host_data += [host_sheet.row_values(row)]
return host_data
def loadDataSet():
host_sheet,rows=read_excel()
host_datas=read_data(host_sheet, rows)
return host_datas
def createC1(dataSet): #构建所有候选项集的集合
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
return list(map(frozenset, C1)) #使用frozenset函数,被“冰冻”的集合,
#返回的是将c1列表中元素经过frozenset函数处理后的集合,不可更新。为后续建立字典key-value使用。
#成绩分级
def scoreTodegree(transaction):#成绩数据分级函数,dataSet[1:]
data=[]
for items in transaction:#items=['68', '77', '77', '71']
#print(items)
for i in range(len(items)):
if type(items[i]) == int:
items[i] = -1
continue
else:
if float(items[i]) >= 60.0:
if i == 0:
items[i] = ('高数1及格') #这里采用元组加字符,为了在后面转化集合时,字符串不会被拆分
elif i == 1:
items[i] = ('高数2及格')
elif i == 2:
items[i] = ('线代及格')
else :
items[i] = ('概率及格')
else:
if i == 0:
items[i] = ('高数1不及格')
elif i == 1:
items[i] = ('高数2不及格')
elif i == 2:
items[i] = ('线代不及格')
else :
items[i] = ('概率不及格')
data.append(items)
for i in range(len(data)):
for j in range(len(data[i])):
if j >= len(data[i]): # 这里用来检测i超出data[i]长度,直接退出循环
break
if data[i][j] == -1:
data[i].remove(-1)
j -= 1
return data
#创建满足支持度要求的候选键集合
def scanD(D,ck,minSupport):
#定义存储每个项集在消费记录中出现的次数的字典
ssCnt = {}
#遍历这个数据集,并且遍历候选项集集合,判断候选项是否是一条记录的子集
#如果是则累加其出现的次数
for tran in D:
for scan in ck:
if scan.issubset(tran):
if not scan in ssCnt:
ssCnt[scan] = 1
else:
ssCnt[scan] +=1
#计算数据集总及记录数
numItems =float(len(D))
#定义满足最小支持度的候选项集列表
retList = []
#用于所有项集的支持度
supportData = {}
#遍历整个字典
for key in ssCnt:
#计算当前项集的支持度
support = ssCnt[key]/numItems
#如果该项集支持度大于最小要求,则将其头插至L1列表中
if support >= minSupport:
retList.insert(0,key) #添加的是key,不是ssCnt
#记录每个项集的支持度
supportData[key] = support
return retList,supportData
def aprioriGen(Lk, k): # 创建新的符合置信度的项集Ck,即是组合生成新的项集,k为步长,如项集{1,2,3}k=3.
lenLk = len(Lk) # 计算数据集长度
retList = []
for i in range(lenLk):
for j in range(i + 1,
lenLk): # 取交集的过程
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2:
retList.append(Lk[i] | Lk[j])
return retList
def apriori(dataSet, minSupport=0.5):
C1 = createC1(dataSet)
D = list(map(set, dataSet))
L1, supportData = scanD(D, C1, minSupport)
L = [L1] # L将包含满足最小支持度,即经过筛选的所有频繁n项集,这里添加频繁1项集
k = 2
while (len(L[k - 2]) > 1): # k=2开始,由频繁1项集生成频繁2项集,直到下一个打的项集为空
Ck = aprioriGen(L[k - 2], k) # 获取合并项集后的最小支持度项集
Lk, supK = scanD(D, Ck, minSupport) # 计算最小支持度
supportData.update(supK) # supportData为字典,存放每个项集的支持度,并以更新的方式加入新的supK
L.append(Lk)
k += 1
return L, supportData
# 关联规则函数,求置信度
def generateRules(L, supportData, minConf=0.7):
confData = set()
for i in range(1, len(L)): # 从1开始,因为L中的第一个元素集合是频繁1项集,在求置信度中,不能作为分子,只能作为分母
for j in range(len(L[i])): # 遍历L的第i各元素集合中所有元素,作为置信度的分子
for h in range(i): # 这两层for,循环遍历L0至Li-1元素集合的所有元素,作为分母
for k in range(len(L[h])):
conf_score = supportData[L[i][j]] / supportData[L[h][k]]
if conf_score >= minConf and L[h][k].issubset(L[i][j]):
confData.add((L[i][j], (L[h][k], conf_score)))
return confData # 返回置信度集合
dataSet = loadDataSet()
dataSet=scoreTodegree(dataSet[1:])
L,suppData = apriori(dataSet, minSupport=0.1)#支持度>=10%
print ("所有符合最小支持度的项集L:\n",L)
print('所有频繁集的支持度suppData :',suppData)
conf_Data = generateRules(L,suppData,minConf=0.5)#置信度>=50%
for value in list(conf_Data):
print(value[0],end= ' ')
print('————>',end=' ')
print( value[1][0],'置信度 : %f '%(value[1][1]))
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









