






前言
整篇文章是对作者Russ Cox的文章Regular Expression Matching Can Be Simple And Fast的翻译,在我看来,该文章是入门正则引擎的较好的文章之一,读者在阅读之前,最好有一定的正则表达式的基础。翻译内容仅代表作者观点。侵删
该作者所有的文章的网址在此:https://swtch.com/~rsc/regexp/
正文
正则表达式
正则表达式是一个用来表示一系列字符的字符串的符号,当一个确定的字符串处于一个正则表达式所描述的字符串系列时,我们通常说这一正则表达式匹配了这一字符串。
最简单的正则表达式是一个字面上的字符,除了一些特殊的元字符:*+?()| 以外,字符匹配的是它们自身。而为了匹配特殊的元字符,我们在这些元字符之前加上一个斜线 \ ,例如\+ 则可以匹配加号。
两个正则表达式相并联或串联可以形成新的正则表达式:如果e1可以匹配s,而e2匹配t,那么e1|e2匹配s或者t,e1e2匹配st。
元字符*,+,?代表重复操作符,e1*匹配一系列零个或多个元素的字符串,其中的每一个元素均匹配e1;e1+匹配一个或多个;e1?匹配零个或一个。
操作符的优先级,由弱到强排列,首先是并联 |,之后是串联,最后是重复操作符。括号可以用来改变结合的顺序,就像书写算术表达式一样。例如:ab|cd与(ab)|(cd)含义相同,ab*与a(b*)含义相同。
到目前为止我们所介绍的语法只是传统的Unix egrep的正则表达式的语法的一个子集。而这个子集完全有能力去描述所有的正规文法(3型文法),不严谨的说,正规文法是一系列的可以通过一趟扫描并使用固定大小的内存容量进行匹配的字符串。更新的正则引擎(特别是Perl以及与其相同的那些)加入了许多新的操作符和转义字符。这些新的特性使得正则文法更加的简洁而隐晦,但常常却不是那样的有用,这些奇特的正则表达式通常都需要更长的匹配时间。
有一个常见的正则表达式的扩展的确为正则表达式提供了更加强大的功能——回溯引用(或反向引用)(backreferences).\1 \2之类的回溯符号会去匹配被该符号之前的括号中的正则表达式所匹配的字符串,如(cat|dog)\1会匹配catcat和dogdog但不会匹配catdog或dogcat。从理论上说,带有回溯引用功能的正则表达式不再是正规文法。回溯引用带来强大功能的同时也需要付出巨大的代价:在最坏的情况下,一些知名的正则引擎需要耗费指数级的匹配时间,就如Perl所使用的那样。毋庸置疑的,Perl不能移除回溯引用这一功能,但是当一个正则表达式中并没有使用回溯引用时,Perl可以采用更加快速的算法进行匹配,而这篇文章便是介绍这些更加快速的算法的。
有限自动机
另一种描述一类字符串的方法是使用有限自动机。有限自动机同时也叫作状态机,我们会交换使用自动机和状态机这两个词。
举一个简单的例子,下图是正则表达式a(bb)+a的状态转换图:
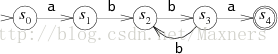
有限自动机在任意时刻只会处于其中的一个状态上,这些状态在上图中使用圆圈表示,(圆圈中添加的字母只是为了讨论方便,但他们并不是自动机的一部分。)自动机不断地读入字符,并根据这些字符改变自己的状态。图中的自动机有两个特殊的状态:初始状态S0和结束状态S4。初始状态被一个单独的箭头所标注,结束状态是双层的圆圈。
状态机一次读入一个字符,并通过箭头的指向来更改自己的状态。假设输入的字符串是abbbba。当状态机读入了第一个字符a的时候,它进入了初始状态S0,并通过a的箭头来到了S1,状态的转换一直持续进行:读入b进入S2,读入b进入S3,读入b进入S2,读入b进入S3,最后读入a进入S4。
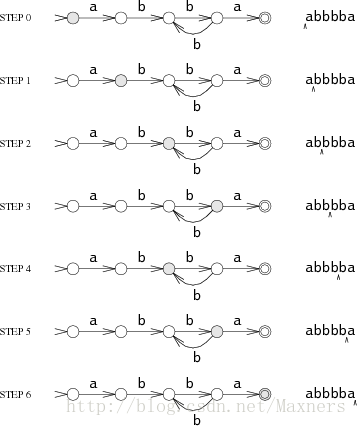
状态机最终在S4上结束,因此它匹配了这个字符串。如果状态机在非结束状态上停止,那它就没有匹配这一字符串。如果状态机在执行的时候,读入了一个字符,但这一字符在图中并没有相应的箭头指向下一状态,那状态机则会提前结束。
在这之前我们讨论的自动机叫做确定状态自动机(DFA),因为在任意的状态下,任何可能的一个输入均只会让自动机进入最多一个新的状态。我们同样可以创造一个需要在多个可能的下一状态中进行选择的自动机。例如,下图中的自动机与前文所说的自动机等价,但是却不是“确定”的。
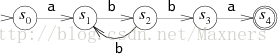
上图中的自动机是非确定的因为当它在状态S2时读入了一个b,那它便有了多个可能的下一状态,它可以回到S1,并认为接下来读入的是两个b,或者它可以来到S3并认为下一个输入是a。因为自动机无法提前查看字符串中剩下的输入,因此它没有办法知道哪一个才是正确的决定。这样的自动机被叫做不确定状态自动机(NFA)。一个NFA匹配一个字符串如果它能在读入该字符串后通过箭头到达匹配状态。
有时候让NFA带有无字符的箭头是非常方便的,我们会保留这些没有标志的箭头,一个NFA可以在任何时候,在没有读入任何字符的状态下选择通过没有标志的箭头来到下一个状态。下图中的NFA与上图中的NFA等价,但是空的箭头使a(bb)+a的表示更为清晰。

将正则表达式转换为NFA
正则表达式与NFA的能力是相互等价的,每一个正则表达式都有与其相对应的NFA(它们匹配相同的字符串),反之亦然。(DFA的能力与NFA,正则表达式也是等价的)有多种方法可以将正则表达式转换为NFA。接下来介绍的方法由Thompson于1968年在他的CACM文章中首次提出。
一个正则表达式的NFA从该表达式的子表达式开始,通过为每一个操作符创建相应的NFA而建立起来。NFA的基本部分不包含结束状态,而这些基本部分有一个或多个悬空的箭头,不指向任何状态。构建NFA的程序会在结束之前将这些悬空的箭头指向结束状态。
匹配单个字符的NFA如下:
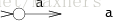
e1e2的NFA将e1最后的箭头与e2的开始相连接:
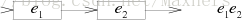
e1|e2的NFA增加了一个新的开始状态指向e1或者e2:
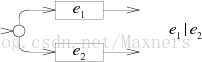
e?的NFA将e与一个空的箭头以或的方式连接:

e*的NFA使用同样的或的形式但是将e最后的箭头与开始状态连接起来:
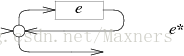
e+的NFA同样有一个环,但是要求至少通过e一次:

数一数上图中的新的状态的数量,我们可以知道这种构造方法为每一个字符或者元字符增加了一个状态,除了括号以外。因此最后构造出的NFA的状态数量不会超过原始的正则表达式的长度。
正如我们之前讨论过的例子中的NFA一样,我们完全可以将NFA中的空箭头去掉,我们也可以在一开始构造的时候就避免使用空箭头。但使用空箭头可以使NFA阅读起来更容易,同时在使用C实现时也更加的简单,所以我们会保留它们。















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









