







2021SC@SDUSC
这一部分是我在学习过程中发现的一个比较不错的idea,想到可以用来可以作为我们功能的一个拓展。
目录
一.功能和实现思路简单介绍
1. 背景介绍
目前短视频越来越火,所以视频的内容分析也变得跟文本的内容分析一样重要。
2.存在问题
然而,如果每个分析者都要看每个视频,太花时间了,即使利用快进功能,节省的时间依然不够,另外,会有人为的疏忽造成内容分析错漏。
3.解决思路
如果对比一下文本的内容分析,就会发现一个重大区别:看文本内容可以一目十行,而且没有强制的从前到后的时间线,相反,看流媒体则必须耗用媒体流的时长。那么我们就会产生一个问题:看流媒体是否可以一目十行?
实际上视频流中的大量信息是冗余的,信息量很低,信息量只集中在一张张关键帧(也叫信息帧,或I帧)图片中,如果把这些图片一个个摆在眼前,就能做到一目十行,而且减少人为疏忽。
二.关键代码
1.程序输入输出描述
这个可以用来提取视频关键帧。用户给定一个视频后,最终返回给用户的是这个视频的关键帧,即一系列图片。
程序输入:视频url
程序输出:一系列关键帧图片
2.代码结构和代码
import os
import shutil
import av
def extract_video(filename):
container = av.open(filename)
stream = container.streams.video[0]
stream.codec_context.skip_frame = 'NONKEY'
for frame in container.decode(stream):
frame.to_image().save(
'frame{:04d}.png'.format(frame.pts),
quality=80,
)
# 存原始视频的目录
src= "./video/"
# 存处理后提取到关键帧图片数据的目录
des = os.path.abspath(".")+"/result/"
list_video = []
#处理这个目录下的所有视频文件
for item_filename in os.listdir(src):
list_video.append(item_filename)
if len(list_video)==0:
print("视频文件不存在")
#结果保存文件夹
for filename in list_video:
if not os.path.exists("result"):
os.makedirs("result")
#提取关键帧
extract_video(src+filename)
#把关键帧图片放到result下
for filename_png in os.listdir(os.getcwd()):
if ".png" in filename_png:
shutil.copy2(filename_png, "result")
os.remove(filename_png)
print(filename_png)三.效果展示
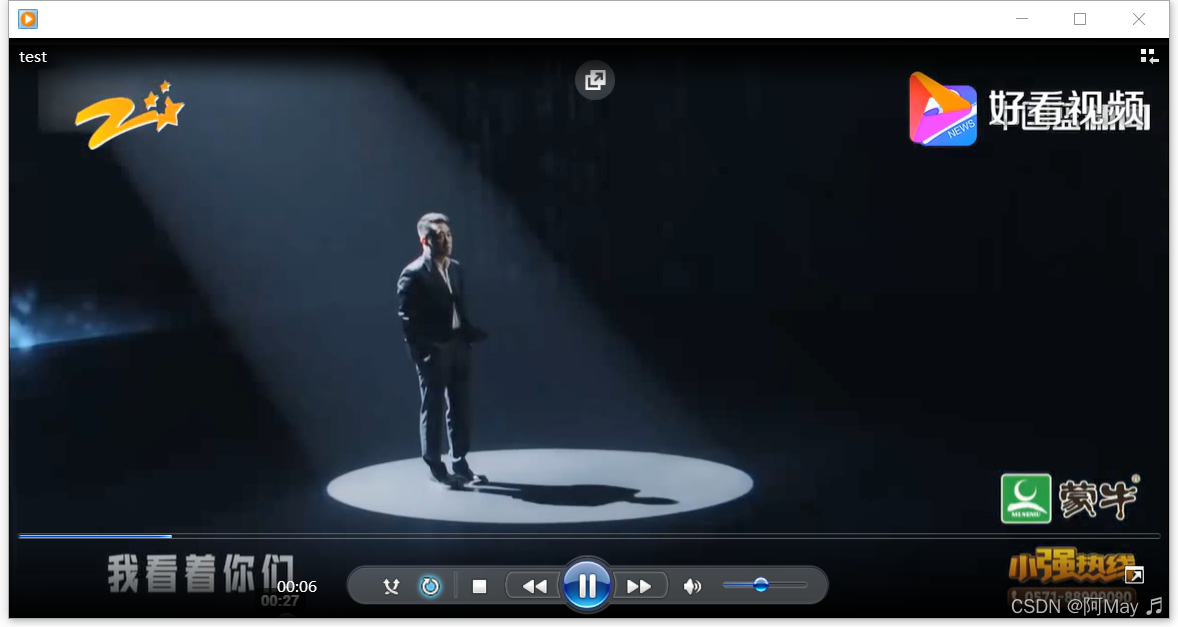
1.输入视频
这里我用了“后浪”的视频,因为涉及的场景人物比较多,所以能更好的发现程序的效果:
2.提取出来的关键帧
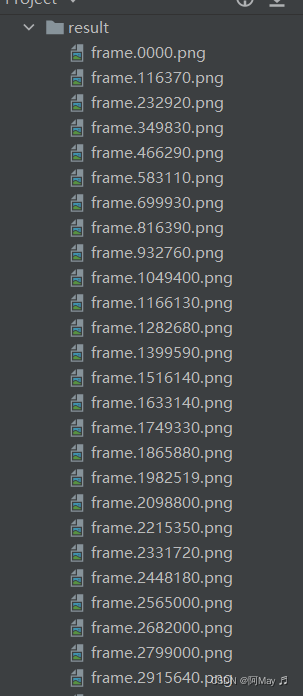
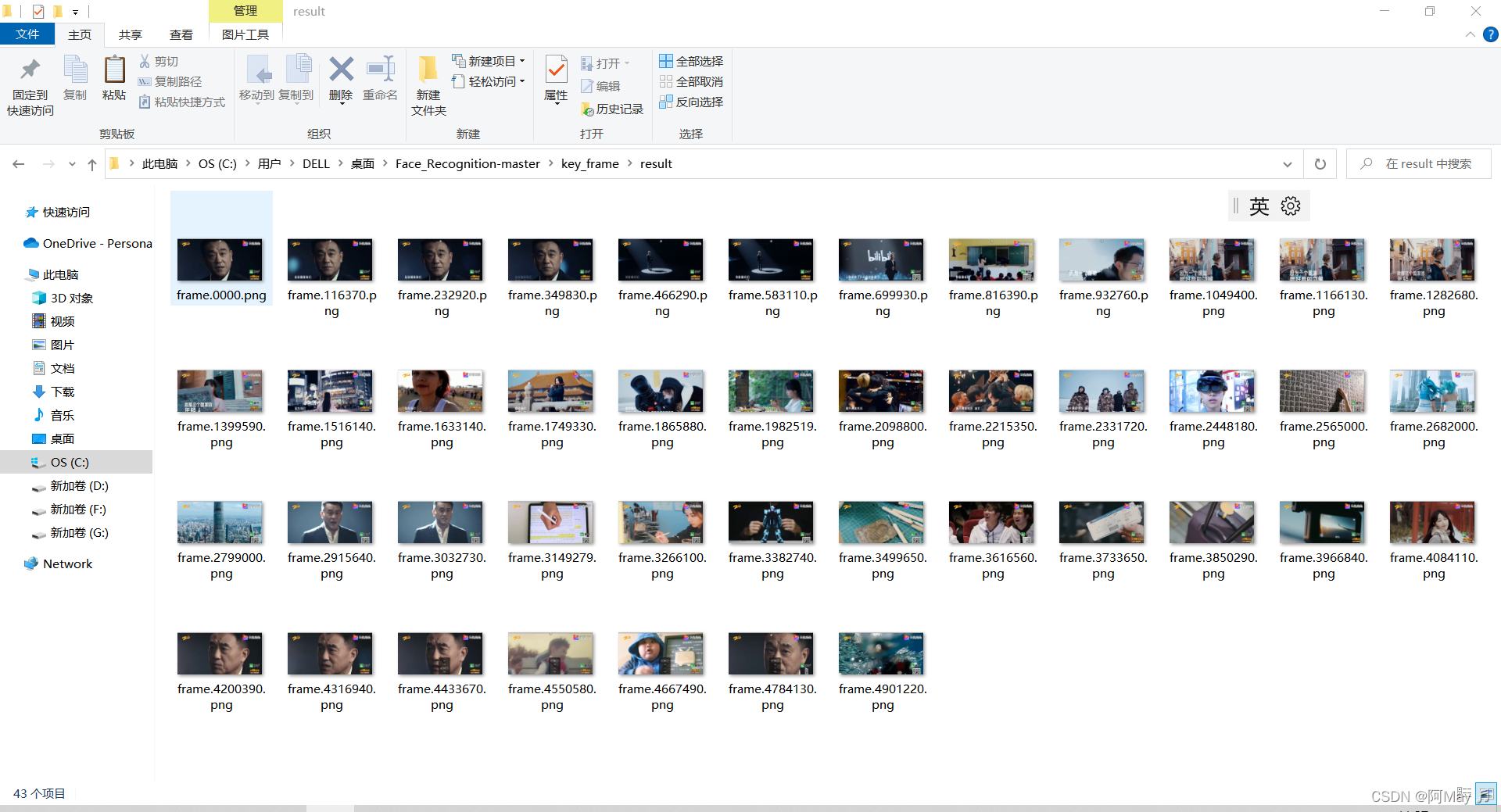
3.存在问题
可以看出来,这个提取的总体效果是很不错的,但是还是有以下问题:
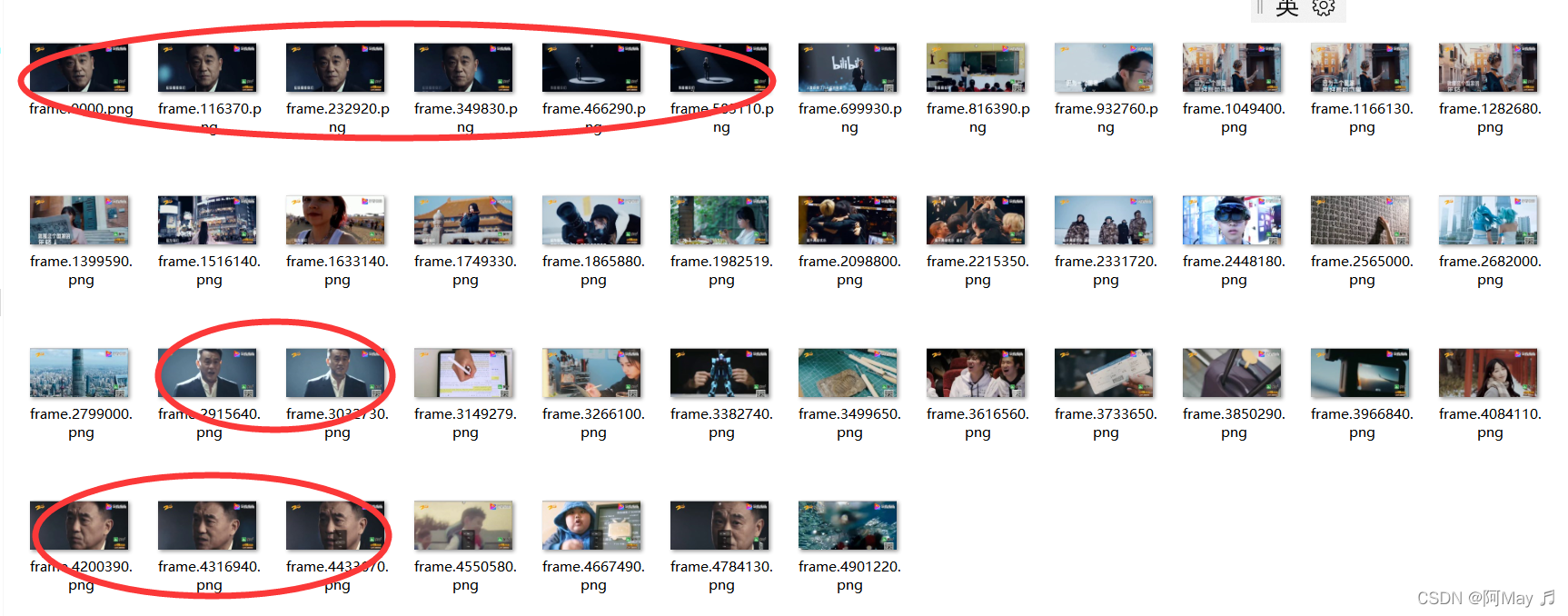
还是有一些关键帧是很像的,但是这个问题很好解决,只需要对结果进行相似度对比,相似度高于阈值的可以选择删除其中一个,就可以解决这个问题了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









