







使用ddd的好处

1、什么是充血模型,什么是贫血模型,优缺点:
1、充血模型
将实体和引起实体发生变化的方法放入实体中这种就叫做充血模型
/**
* 扩展信息
*/
private Map<String, Object> extraMap;
/**
* 得到发奖原因描述
*
* @return
*/
public String getOfferName() {
if (extraMap != null && extraMap.get(AWARD_OFFER_NAME) != null) {
return String.valueOf(extraMap.get(AWARD_OFFER_NAME));
}
return null;
}
/**
* 得到发奖原因描述
*
* @return
*/
public String getExtraValue(String key) {
if (extraMap != null && extraMap.get(key) != null) {
return String.valueOf(extraMap.get(key));
}
return null;
}2、贫血模型
mvc三层架构,把自己的属性私有化而并不在自己的实体里面有扩展方法,这种就叫做贫血模型。
3、充血模型的优点:
1. 面向对象设计,具有良好的封装性和可维护性。
2. 领域对象自包含业务逻辑,易于理解和扩展。
3. 可以避免过度依赖外部服务,提高系统的稳定性。
4、充血模型的缺点:
1.需要对模型的理解才能更好的开发,上手成本高
2. 对象间的协作可能增加,导致设计变得复杂。
3. 对象的状态可能会变得不一致,需要特别注意。
5、贫血模型的优点:
1.数据与行为分离,降低了对象的复杂度。
2. 可以提高代码的重用性和可测试性。
3. 可以更好地利用现有的服务和框架。
6、贫血模型的缺点:
1.对象缺乏封装性,易于出现耦合性和脆弱性。
2. 业务逻辑被分散在多个类中,难以维护和理解。
3. 过度依赖外部服务,可能导致系统的不稳定性。
2、仓库Repository
把对数据库的操作隔离出来,保证以后即使换了数据源到时候换个实现类就好了
列子:
3、防腐层
拿风控举列比如说。因为每次请求都需要经过风控所以直接写了实现类
4、消息中间件mq
值对象。抽出一些属性放在值对象里面。,以确保后期维护

发布消息接口。异步发放,同步发放。放在应用层

发布消息实现类。异步发放,同步发放。 放在基础设施层
mq监听 放在基础设施层
5、领域服务
封装跨实体业务 ,传参数尽量只使用实体而不使用单个值来进行传递参数,保证在一个方法里面只有调用实体来操作业务,保证实体的纯粹性。
6、防止类爆炸(聚合Aggregate)
在使用ddd是业务逻辑会变的特别清爽 但是也会有一个弊病。就是类越来越多,为了防止这种状况发生,就有了聚合这种概念,聚合就是同一种业务放在一块,然后产生一个聚合根,通过这个聚合根来理解这些聚合是做什么的。
为什么还需要聚合?
如果实体和值对象比喻成一个个独立的人的话,那么聚合就可以比喻成让实体和值对象协调工作的组织、部门等,在聚合中实体和值对象围绕共同的目标前进。
6.1聚合根
聚合根首先也是一个实体,聚合根是为了防止在聚合中缺少统一的业务规则造成聚合、实体的数据不一致。其次,聚合根还是聚合对外的接口人,在不同的聚合之间通过聚合根ID关联,外部对象 不能直接访问其他聚合变得实体,必须先通过聚合根,再定位到具体的实体。
如果把聚合比作组织,那么聚合根就是组织领导人。
发奖返回信息聚合根
如何构建聚合?
以用户骑行场景为例
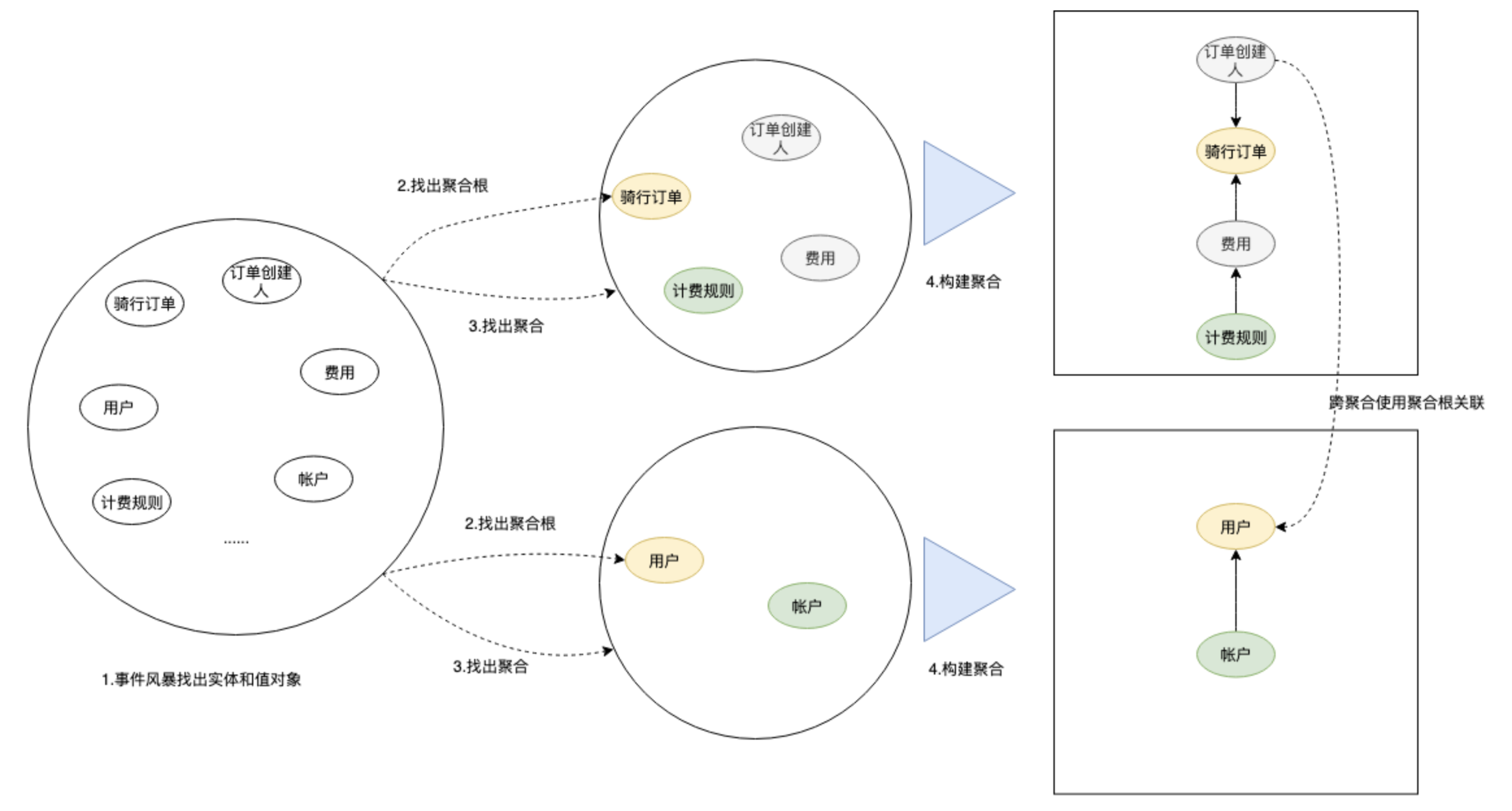
1.通过事件风暴,分析出用户骑行整个过程中相关的实体和值对象。
2.找出聚合根,原则:
>> 是否有独立的生命周期
>> 是否具有全局的唯一ID
>> 是否有单独的模块管理这个聚合根,是否可以通过这个实体操作其他相关的实体和值对象
3.根据业务单一原则和聚合内部高内聚原则,找出与聚合根关联紧密的实体和值对象。
4.在聚合内根据聚合根、实体、值对象画出对象的引用和依赖模型,构建最终的聚合模型。
5.多个聚合根据语义和上下文决定是否划分到同一个限界上下文。
聚合设计原则
1.在一致性边界内建模真正的不变条件:在聚合内实体和值对象按照统一的业务规则运行。
2.设计小聚合:一个聚合不应该包含过多的实体,导致聚合内管理过于复杂,容易出现并发冲突和数据库锁。
3.通过唯一标识引用其他聚合:聚合与聚合的引用是通过聚合根ID关联。
4.在边界之外使用最终一致性:聚合内部使用强一致性,聚合之前数据使用最终一致性。涉及多个聚合状态的修改应该通过领域事件方式异步修改相关聚合状态。
5.通过应用层实现跨聚合的服务调用。
7、北向网关与南向网关
北向网关用于封装外部对领域的请求,南向网关用于响应数据
ddd最终发展理念。 把每个服务组装成为一个独立的棱形包服务 也就是中台

8、如何理解领域驱动设计
ddd认为,软件开发的核心是理解业务,而不是实现技术,在ddd中软件开发人员应该与业务人员密切合作,了解业务需切,理解业务模型,通过抽象出业务领域模型、领域服务,和领域事件等功能,将业务模型映射到软件系统中,以实现更好的业务价值。
在不使用DDD的软件开发过程中,来了一个需求,开发会首先考虑如何设计表结构,然后再根据表结构设计实体
类以及对应的Service服务。但是在DDD中,提倡通过领域驱动设计,要先进行领域建模,最后在考虑持久化存
储。
具体而言,DDD的主要思想包括:
• 领域建模:领域建模是DDD的核心概念,其目的是将业务领域抽象出来,通过对领域对象、领域服务、领域
事件等概念的定义,实现业务需求。
•领域驱动架构:DDD中有一套自己的架构分层,将应用程序划分为四个层次,包括应用层、领域层、基础设
施层和用户接口层,以实现业务领域的清晰分离。
• 领域事件驱动:领域事件是领域模型中的一种交互机制,可以用于在模块之间传递信息,实现领域模型的解
耦。领域事件驱动是一种基于领域事件的系统架构风格,通过领域事件的发布和订阅机制,来实现系统的解
耦。
8.1、ddd带来的好处。
DDD强调业务领域的概念,术语和关系。通过深入了解业务领域,开发人员可以更好地理解和反映业务需求,从
而开发出更符合业务需求的软件系统。能够更好的理解业务领域。
DDD鼓励将软件系统划分为可重用的模块,这些模块基于业务领域的概念和语言进行组织。这样可以使代码更加
模块化,易于维护和重构,并且可以更好地支持业务需求的变化。
DDD倡导业务人员,开发人员和其他技术人员之间的紧密协作。通过这种协作,业务需求可以更好地传达给开发
团队,同时开发人员也可以向业务人员解释他们正在开发的软件系统的工作方式。
8.2、ddd的不足之处
DDD是一种复杂的方法论,需要较长的学习曲线来理解和应用。因此,它可能不适合所有的开发团队。
由于DDD需要更深入的业务领域知识和更好的模块化,因此它可能需要更多的开发成本。这可能会使它不适合一
些较小的项目或团队。
虽然DDD可以在许多项目中得到应用,但并不是所有项目都适合使用DDD。因此,在应用DDD之前,需要评估项
目的需求和适用性。
9、ddd实现流程
ddd的实现流程大致可以分为6步:
1、确定业务领域
首先,需要明确软件系统要解决的业务问题,并确定业务领域的边界。业务领域是指具有内在一致性和自治性的业
务范畴,它包含了一些核心概念、业务规则和业务流程。
下图就是3个领域的经典实现:
2、设计领域模型
在确定业务领域之后,需要设计领域模型。领域模型是用来描述业务领域的核心概念、业务规则和业务流程的一种
图形化表示方式。它由实体、值对象、聚合、领域服务和事件等元素组成。
3、建立统一语言
为了确保所有团队成员都能够理解和共享业务知识,需要建立统一的业务语言。这个语言应该是简单、清晰、精确
和易于理解的,以便能够准确地表达业务概念和业务规则。
4、实现领域模型
在设计好领域模型之后,需要将它们转化为实际的代码。实现领域模型需要注意以下几点:
•将领域对象封装到聚合中,并保证聚合内的对象保持一致性。
• 实现领域服务,以实现领域模型之间的交互和协作。
•使用领域事件来传递领域对象之间的消息。
(在设计好领域模型之后,需要将它们转化为实际的代码。实现领域模型需要注意以下几点:
• 在聚合中封装实体和值对象,并保证聚合内的对象保持一致性。
• 实现领域服务,例如TradeEventHandler,负责积分兑换抽奖次数下单、积分兑换商品下单、等操作。
• 使用领域事件来传递领域对象之间的消息
5、应用架构设计
除了领域模型之外,还需要设计应用架构。应用架构包括了应用层、基础设施层和表示层等组件。应用层负责处理
用户请求和协调领域对象的交互,基础设施层负责提供数据持久化和外部服务访问等功能,表示层负责将应用程序
的结果展示给用户。
6、领域驱动设计和实践
最后,需要实践领域驱动设计。实践过程中需要注意以下几点:
•确保领域模型和业务需求的一致性。
• 实时更新领域模型,以应对业务需求的变化。
•鼓励团队成员共同参与领域模型的设计和实现。
(最后,需要实践领域驱动设计。实践过程中需要注意以下几点:
•确保领域模型和业务需求的一致性
• 实时更新领域模型,以应对业务需求的变化。
10、什么是实体,什么是值对象。
值对象就是实体里面的对象(理解式说法)
实体通常指具有唯一标识的具体对象或事物。实体通常具有自己的生命周期,可以被创建、修改和删除。在数据库
中,实体通常对应着数据库表的一行记录,每个实体具有唯一的标识符(通常是主键)。
比如,一个人可以被视为一个实体,因为每个人都有唯一的身份证号码作为标识符,并且每个人具有自己的生命周
期,可以被创建、修改和删除。
值对象通常指没有唯一标识的对象或数据类型。值对象通常不可变,一旦创建就不能修改,只能通过创建新的值对
象来替换原来的值对象。在数据库中,值对象通常对应着数据库表的一组字段,每个值对象不具有唯一的标识符,
而是通过一组字段来描述其属性。
比如,一个地址可以被视为一个值对象,因为它没有唯一标识符,而是由一组字段描述,例如国家、省份、城市、
街道和门牌号等。并且地址通常是不可变的,一旦创建就不能修改,只能通过创建新的地址对象来替换原来的地址
对象。
11、什么是领域事件
领域事件,是DDD中比较常见一个概念,他一般是领域内的模型发生了一些状态或者行为时,向外发出的一个通
知。被定义为领域事件。
他和我们常听说的MQ中的事件不一样,领域事件一般不会在分布式系统之间传递,只会在单个微服务内部传递。
它起到最大的好处和MQ一样,就是解耦,通过事件的方式来解除领域之间的耦合,通过发布事件的方式进行一种
松耦合的通信,而不用依赖具体的实现细节。
其实领域事件本质就是发送个mq消息用来解偶。就比如当中奖时发送个中奖事件,发奖成功时发放个发奖的领域事件去做相应的发奖事物。
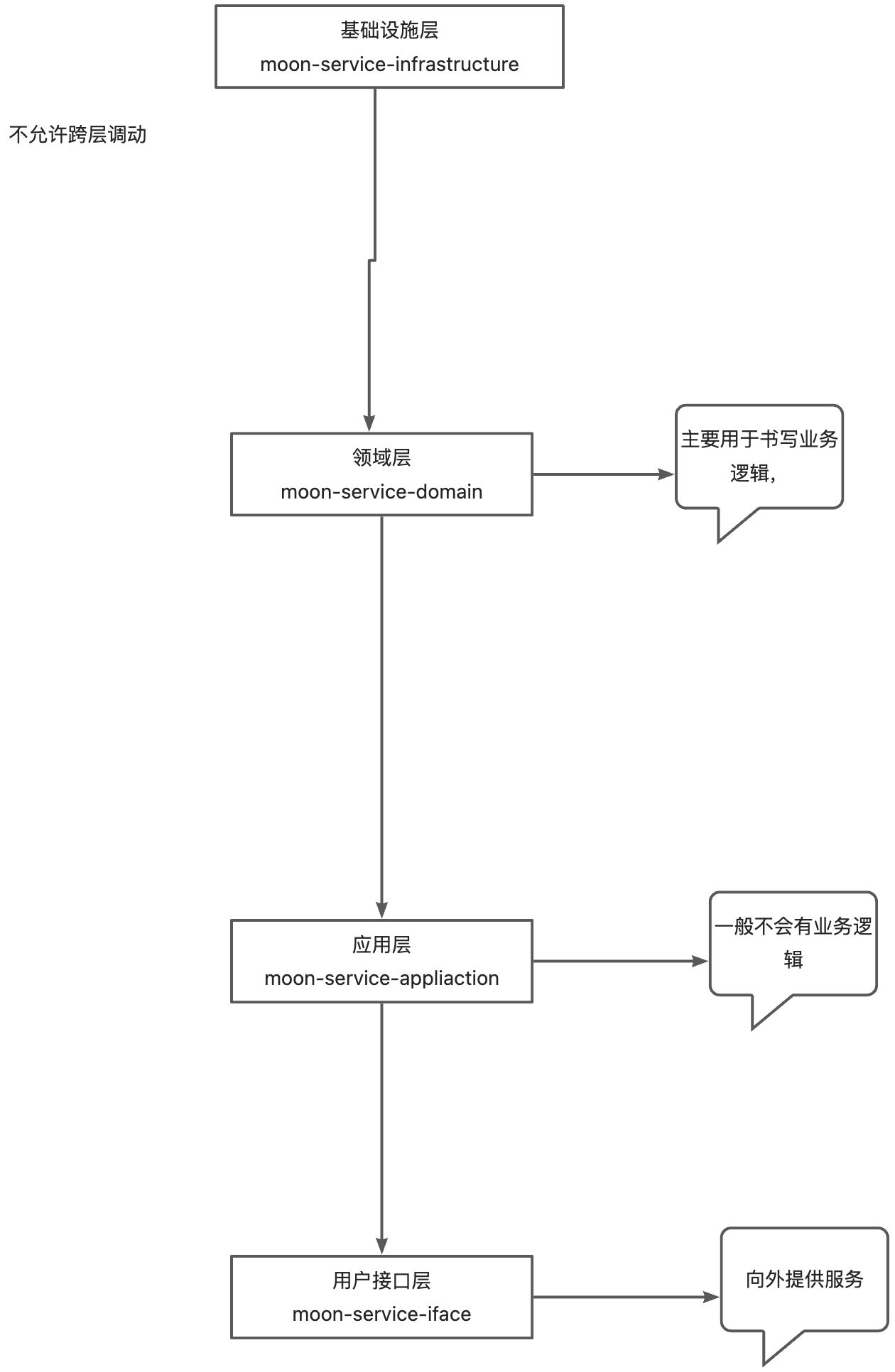
12、ddd分层架构是怎么样的
DDD的分层架构是一个四层架构,从上到下依次是:用户接口层、应用层、领域层和基础层。
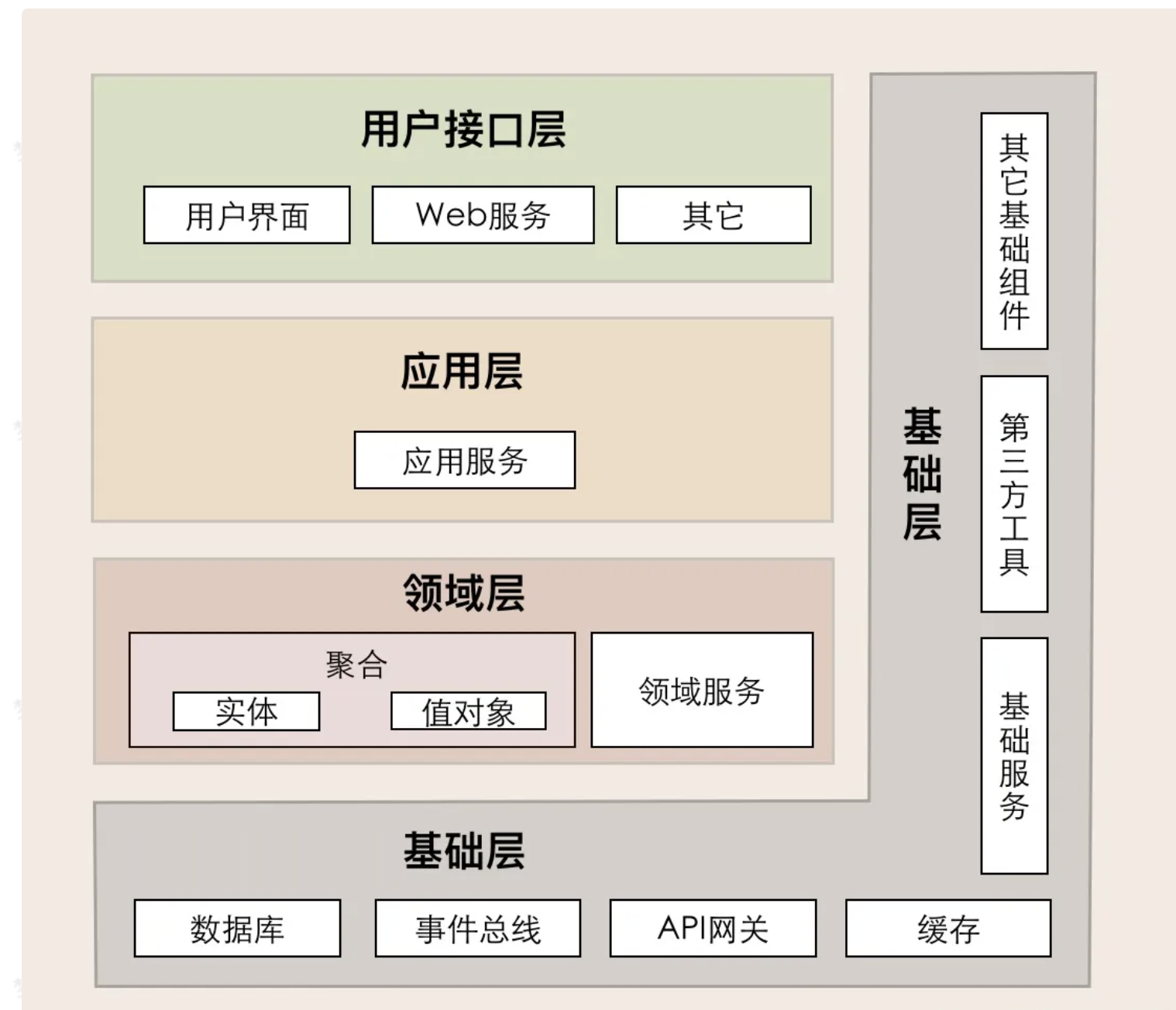
层次之间的调用关系是上层可以调用下层,即用户接口层可以调用应用层、领域层及基础层。应用层可以调用领域
层和基础层,领域层可以调用基础层。
但是不能从下往上反向调用,各个层级之间是严格的单向调用的依赖关系。
除了这种简单的四层架构以外,DDD中还有比较典型的洋葱架构和六边形架构
洋葱架构,就是像洋葱一样的一层一层,从外到内的架构形式,如下图:
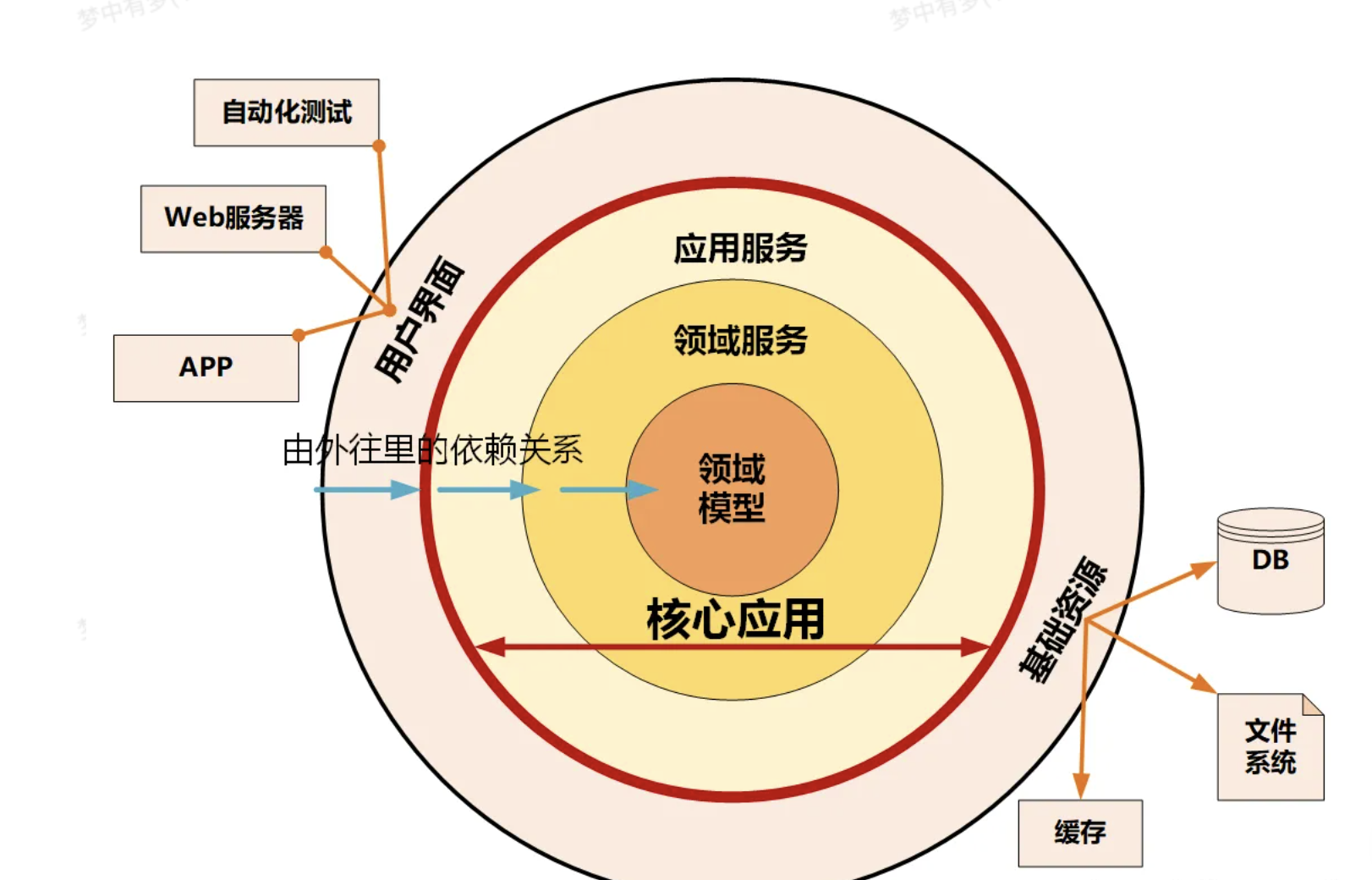
他的依赖关系是从外到内的。
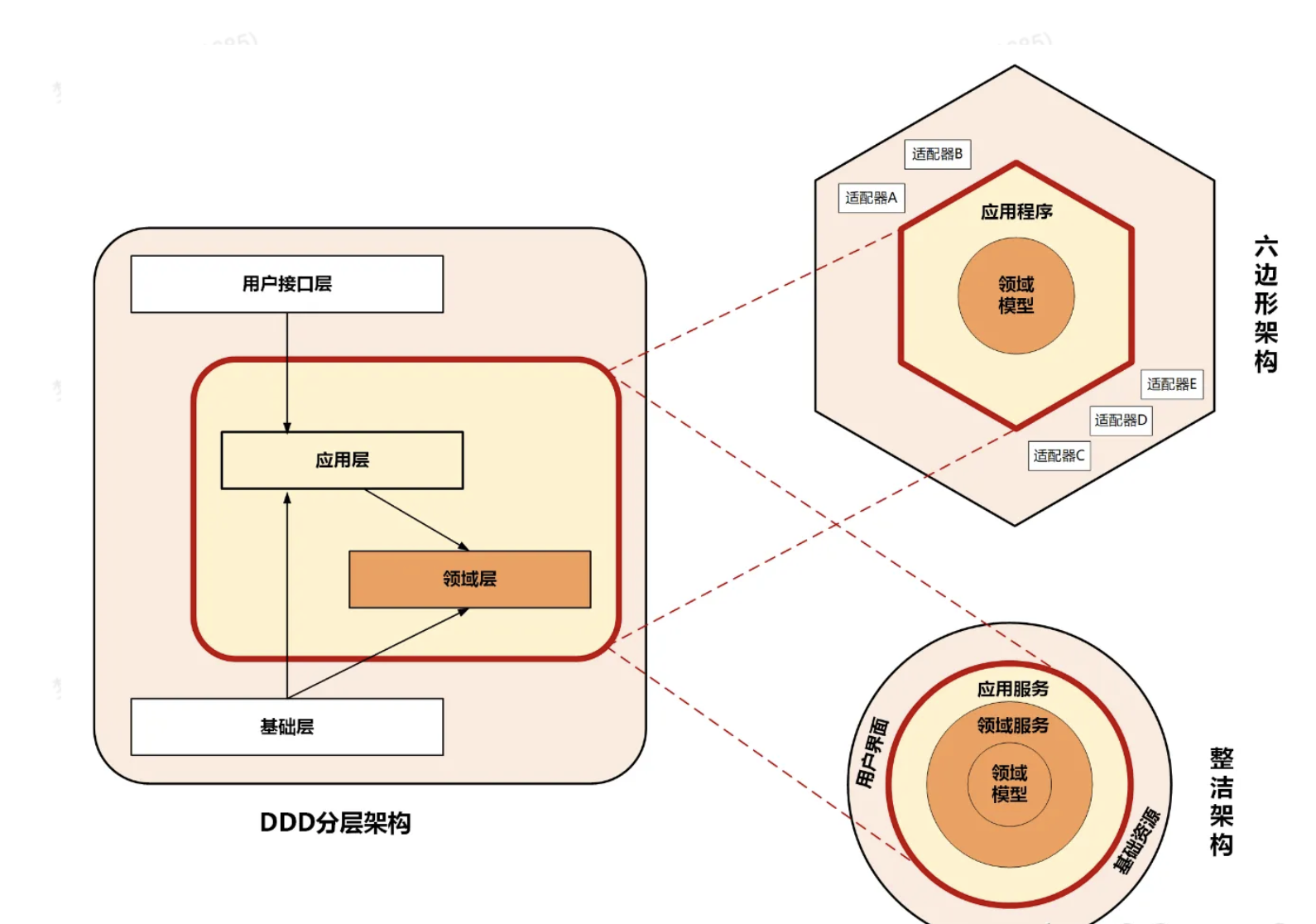
六边形架构和洋葱架构有点像,只不过不是圆形,而是六边形的:

虽然DDD 分层架构、整洁架构、六边形架构的架构模型表现形式不一样,但是这三种架构模型的设计思想都是微
服务架构高内聚低耦合原则的完美体现,都是以领域模型为中心的设计思想。
















 1902
1902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









