







我们平常会遇到下载了一些Excel文件放在一个文件夹下,而这些Excel文件的格式都一样,这时候需要批量这些文件合并成一个excel 文件里。
在Python中,我们可以使用pandas库来读取文件夹中的所有Excel文件,并将它们拼接成一个Excel表格。
这需要以下的操作实现:
- 导入所需的库pandas,os库。
- 准备工作:
2.1. 设置包含需要整理的Excel文件的,文件夹路径。
2.2.初始化一个空的DataFrame,用于存储合并后的数据。- 读取/整理数据:
3.1 遍历文件夹中的所有文件,检查文件扩展名是否为.xlsx或.xls。
3.2. 对于每个Excel文件,使用pandas.read_excel()函数读取数据。
3.3. 使用pandas.concat()函数将读取的数据追加到总表all_df中。- 写入数据:将合并后的DataFrame保存到一个新的Excel文件中。
我们先看看文件夹里的文件:
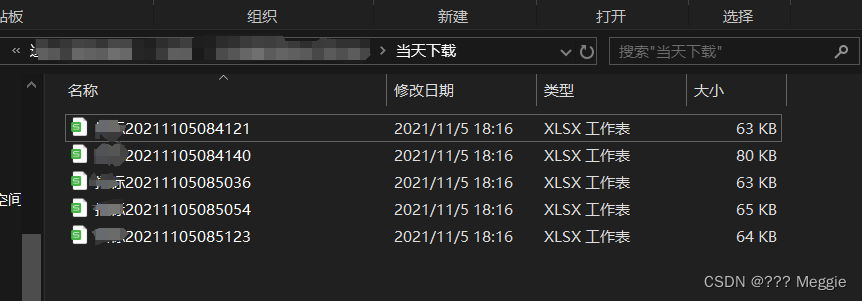
 文件1
文件1
 文件2
文件2
运行之前:请确保在运行此代码之前已经安装了pandas库。如果还没有安装,可以通过以下命令进行安装:
pip install pandas
pip install openpyxl # pandas需要这个库来读取.xlsx文件
以下是一个简单的示例代码,展示了如何实现这一过程:
import pandas as pd
import os
import datetime
#新建一个存入数据的excel 文件路径
result_file=os.getcwd()+'//new.xls'
#path = os.getcwd()+'\\需要抽取的excel'
path=os.getcwd()+'//当天下载'#拼接读取目标文件夹的相对路径
#新建一个空dataframe
all_df=pd.DataFrame()
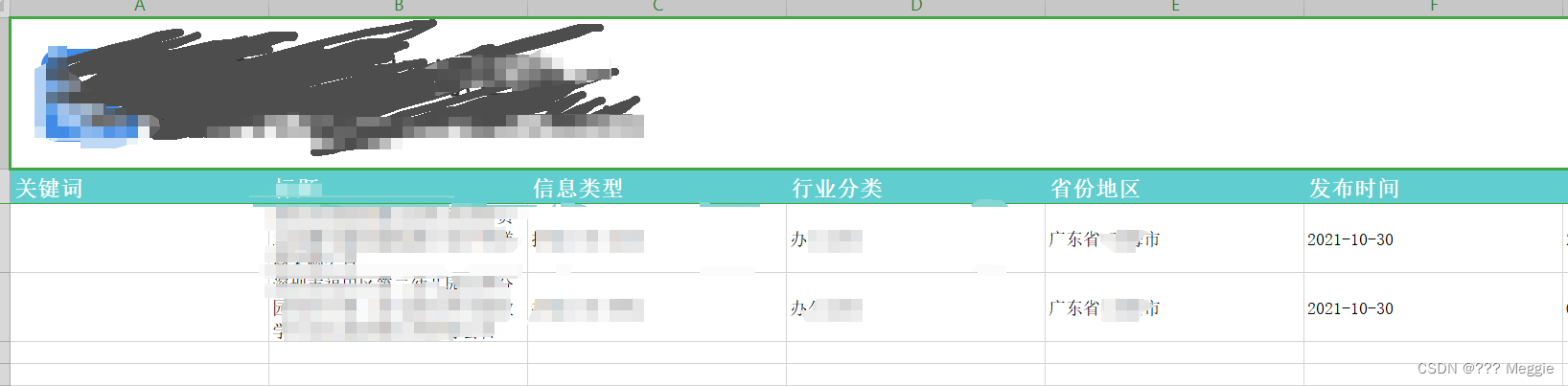
title='关键词','标题','信息类型','行业分类','省份地区','发布时间'
#遍历文件夹中的所有文件
for file_a in os.listdir(path):
# 检查文件扩展名是否为xlsx或xls
if filename.endswith('.xlsx') or filename.endswith('.xls'):
df=pd.read_excel(os.path.join(path,file_a),skiprows=1)
#因为文件的第一行是图片格式 ,所以要跳过 ;如果需要处理dataframe里面的内容,需要在concat前处理
all_df = pd.concat([all_df, df])#需要将读取的数据追加到all_df中
#最后再插入列,放入【更新时间】,用于记录写入时间,不要放在for循环底下
all_df['更新时间'] = datetime.datetime.now().strftime('%Y-%m-%d')
all_df.to_excel(result_file,header=title,index=0,encoding='utf_8_sig')#使用'utf_8_sig'编码读取文件内容。
PS:如果你的Excel文件包含多个工作表(sheet),你可能需要对代码进行一些修改,以指定要读取的工作表。例如,使用pd.read_excel(file_path, sheet_name='Sheet1')来读取特定的工作表。















 3267
3267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









