







 旷视研究院在CVPR 2023共有13篇论文入选,涉及3D目标检测、多目标跟踪、模型压缩等领域。亮点包括纯稀疏3D检测框架VoxelNeXt,视频帧预测的DMVFN网络,通用可裁减自监督学习US3L,预训练物体检测器提升的MOTRv2多目标追踪方法,以及文本引导的多目标追踪任务RMOT等。
旷视研究院在CVPR 2023共有13篇论文入选,涉及3D目标检测、多目标跟踪、模型压缩等领域。亮点包括纯稀疏3D检测框架VoxelNeXt,视频帧预测的DMVFN网络,通用可裁减自监督学习US3L,预训练物体检测器提升的MOTRv2多目标追踪方法,以及文本引导的多目标追踪任务RMOT等。
近日,CVPR 2023 论文接收结果出炉。近年来,CVPR 的投稿数量持续增加,今年收到有效投稿 9155 篇,和 CVPR 2022 相比增加 12%,创历史新高。最终,大会收录论文 2360 篇,接收率为 25.78 %。本次,旷视研究院有 13 篇论文入选,涵盖3D 目标检测、多目标跟踪、模型压缩、知识蒸馏等多个领域。以下为入选论文简介 :
👇
01
VoxelNeXt:Fully Sparse VoxelNet for 3D Object Detection and Tracking
用于3D检测和跟踪的纯稀疏体素网络
目前自动驾驶场景的3D检测框架大多依赖于dense head,而3D点云数据本身是稀疏的,这无疑是一种低效和浪费计算量的做法。我们提出了一种纯稀疏的3D 检测框架 VoxelNeXt。该方法可以直接从sparse CNNs 的 backbone网络输出的预测 sparse voxel 特征来预测3D物体,无需借助转换成anchor, center, voting等中间状态的媒介。该方法在取得检测速度优势的同时,还能很好地帮助多目标跟踪。VoxelNeXt在nuScenes LIDAR 多目标跟踪榜单上排名第一。
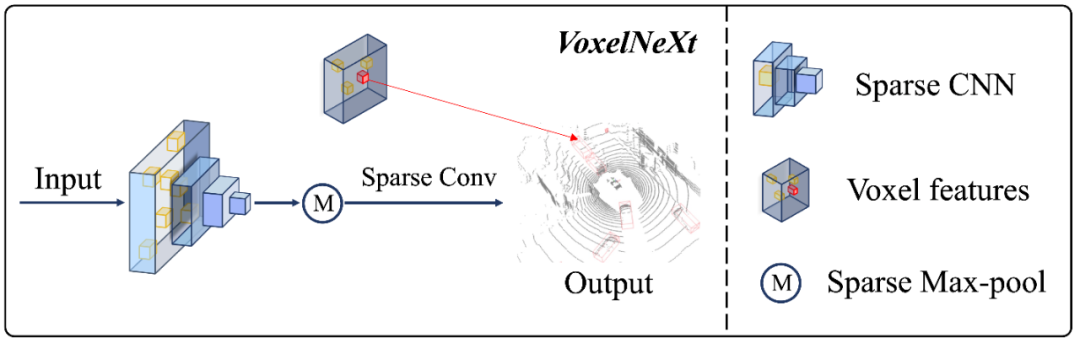
👉关键词:纯稀疏、nuScenes 3D点云多目标跟踪SOTA
https://arxiv.org/abs/2303.11301
02
A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
用于视频帧预测的多尺度动态体素流网络
根据现有的视频帧预测未来的视频帧是一个运动理解和表示学习中的重要任务。先进的深层神经网络极大地提高了视频预测的性能,然而大多数现有方法需要大模型和额外的输入(对应的分割图或者深度图)来预测未来帧。为了更高的效率和更广泛的应用,我们提出动态多尺度体素流网络(Dynamic Multi-scale Voxel Flow Network,DMVFN),DMVFN 仅需要图片帧输入,以相当低的计算成本实现了最先进的视频帧预测性能。DMVFN 的核心是一个可微分的路由模块,它可以有效地感知视频帧的运动规模,在推理阶段自适应地选择适当的子网络。DMVFN 的计算量只有经典的深度体素流方法 DVF 的三十分之一,并且在画面质量上超过了最新的基于迭代的 OPT 算法。
引用:
DVF:Video Frame Synthesis Using Deep Voxel Flow
OPT:Optimizing Video Prediction via Video Frame Interpolation
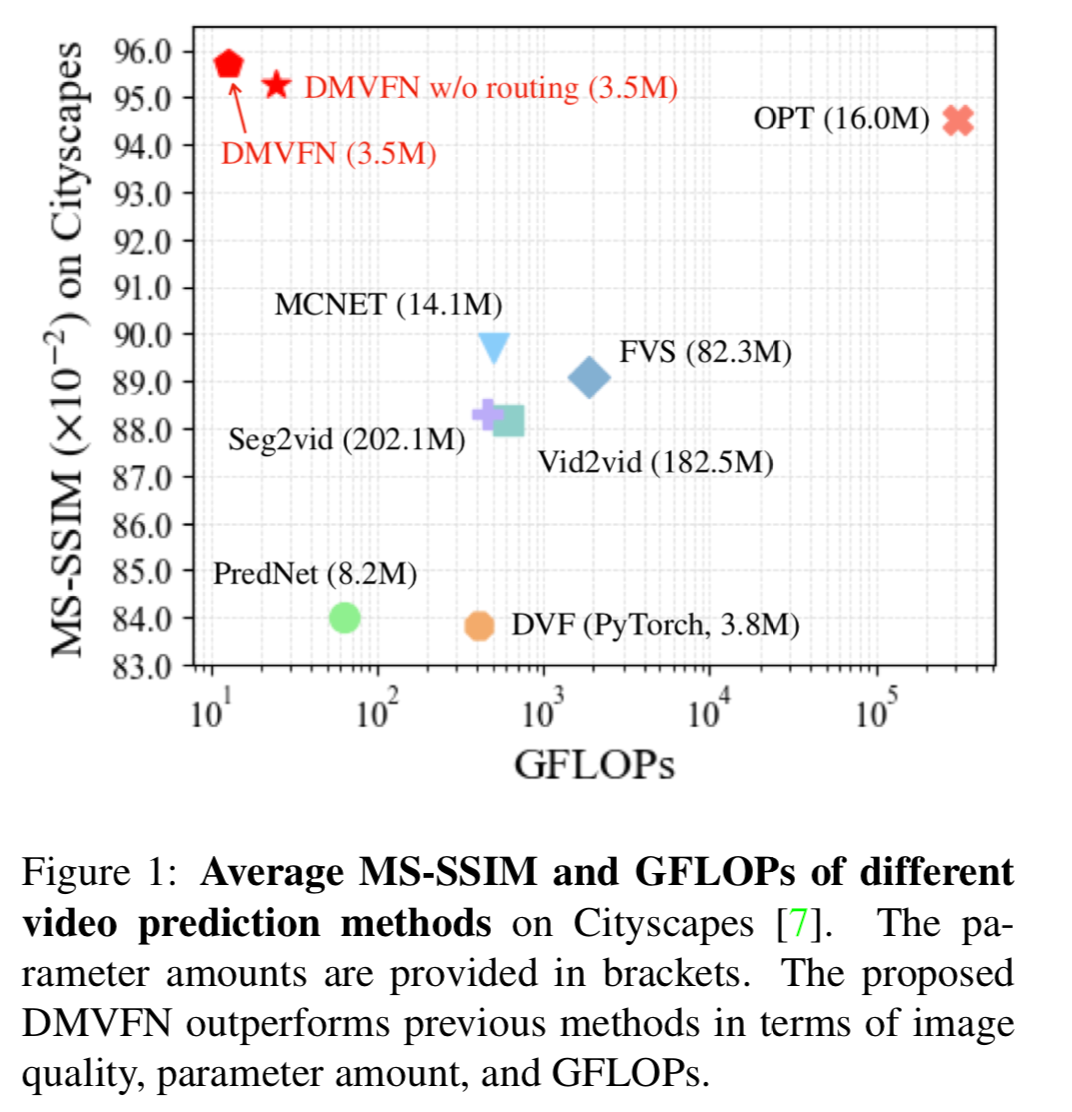
👉关键词:视频预测、动态网络、视频画质、光流
https://huxiaotaostasy.github.io/DMVFN/
03
Three Guidelines You Should Know for Universally Slimmable Self-Supervised Learning
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









