







文章目录
分库、分表、分片、分区的区别
分库(Sharding)、分表(Table Splitting)、分片(Sharding)和分区(Partitioning)是数据库优化和扩展性管理中常用的技术术语。虽然“分片”和“分库”这两个词有时会被交替使用,但它们之间以及其他概念之间确实存在一些重要的区别。下面是这些概念的详细区别:
1. 分库(Sharding)
- 定义:分库是指将数据库中的数据分布在多个数据库实例上,每个实例称为一个“分库”。这是一种水平分割数据的方式,其中数据被分割成多个部分,每个部分存储在不同的数据库实例上。
- 目的:提高系统的整体性能和可扩展性,通过将数据分散到多个数据库实例上,可以实现水平扩展,减轻单个实例的负载。
- 应用场景:适用于需要高度可扩展性和高可用性的大型分布式系统。
2. 分表(Table Splitting)
- 定义:分表是在同一个数据库实例内将一个大表分割成多个较小的表。这些表通常根据某些逻辑标准(如按用户ID、地区等)进行分割。
- 目的:提高查询性能,特别是在处理大表时。通过将表分割成更小的部分,可以减少查询需要扫描的数据量。
- 应用场景:适用于需要优化单个数据库实例内表的查询性能的情况。
3. 分片(Sharding)
- 定义:分片本质上与分库相同,指的是将数据水平分割并分布在多个数据库实例上。这里提到的“分片”特指数据分割的过程。
- 目的:提高系统的整体性能和可扩展性。
- 应用场景:适用于需要高度可扩展性和高可用性的大型分布式系统。
4. 分区(Partitioning)
- 定义:分区是在单个数据库实例内将一个大表分割成多个较小的部分(分区)。这些分区仍然属于同一个逻辑表,但每个分区存储在数据库的不同位置。
- 目的:提高查询性能,特别是在处理大表时。通过将查询限制在特定的分区上,可以显著提高查询性能。
- 应用场景:适用于需要优化单个数据库实例内表的查询性能的情况。
总结
- 分库/分片:数据分布在多个数据库实例上,实现了水平扩展。
- 分表:在同一数据库实例内将表分割成多个表,提高查询性能。
- 分区:在同一数据库实例内将表分割成多个分区,提高查询性能。
关键区别
- 物理位置:分库/分片的数据分布在不同的数据库实例上;分表和分区的数据在同一数据库实例内。
- 目的:分库/分片主要用于实现水平扩展;分表和分区主要用于优化查询性能。
- 实现复杂度:分库/分片通常比分表和分区更复杂,因为需要处理跨实例的一致性、事务管理等问题。
示例说明
- 分库示例:用户表根据用户ID分库存储在不同的数据库实例上。
- 分表示例:用户表根据用户注册时间分表存储在同一数据库实例内。
- 分区示例:用户表根据用户注册时间分区存储在同一数据库实例内。
这些技术的选择取决于具体的应用需求和技术约束。如果你需要解决单个数据库实例的性能瓶颈问题,分区或分表可能是较好的选择;如果你需要解决系统级别的扩展性问题,分库/分片将是更好的解决方案。
wx的分区方案
开启双写在 GORM 上面还是比较容易做到的。最开始我觉得可以考虑使用 GORM 的 Hook 机制,用 DELETE 和 SAVE 两个 Hook 就可以了。
分表对象
tasks wsid hash
resources task_id hash
users wsid hash
分布式ID
所有的业务表更改ID属性,取消自增ID,更改为分布式ID,用于解决ID主键冲突的问题。
采用开源的雪花算法生成分布式ID,参考链接:https://www.zhihu.com/question/391373815
分表
面试还是讲分表吧,分库分表的规模?
几个单表超5千万量级
xiaoe的分表方案
t_crowd_user拆表迁移技术方案
背景
一张用户统计表(人群分组成员表)数据达60多亿,单标内存占3T,影响正常业务查询的速度,数据持续增长易出现不可控风险
步骤
按照店铺id(app_id)哈希创建100张表
数据做双写,读源表,先写源表
补写数据
观察一段时间双写的情况,做数据校验
切换双写顺序,读目标表,先写目标表
观察一段时间后,停掉双写,只写新表,数据迁移完成
数据迁移
下面我们来看一看数据迁移方案的基本步骤。
-
创建目标表,用源表的数据初始化目标表。
-
执行一次校验,并且修复数据,此时用源表数据修复目标表数据。
-
业务代码开启双写,此时读源表,并且先写源表,数据以源表为准。
-
开启增量校验和数据修复,保持一段时间。
-
切换双写顺序,此时读目标表,并且先写目标表,数据以目标表为准。
-
继续保持增量校验和数据修复。切换为目标表单写,读写都只操作目标表。
如果不考虑数据校验,那么整个数据迁移过程是如图这样的。所以比较简单的方式就是记住图里的四步,图右边的两步都要考虑校验和修复数据的问题。接下来我带你分析一下方案里的关键步骤。
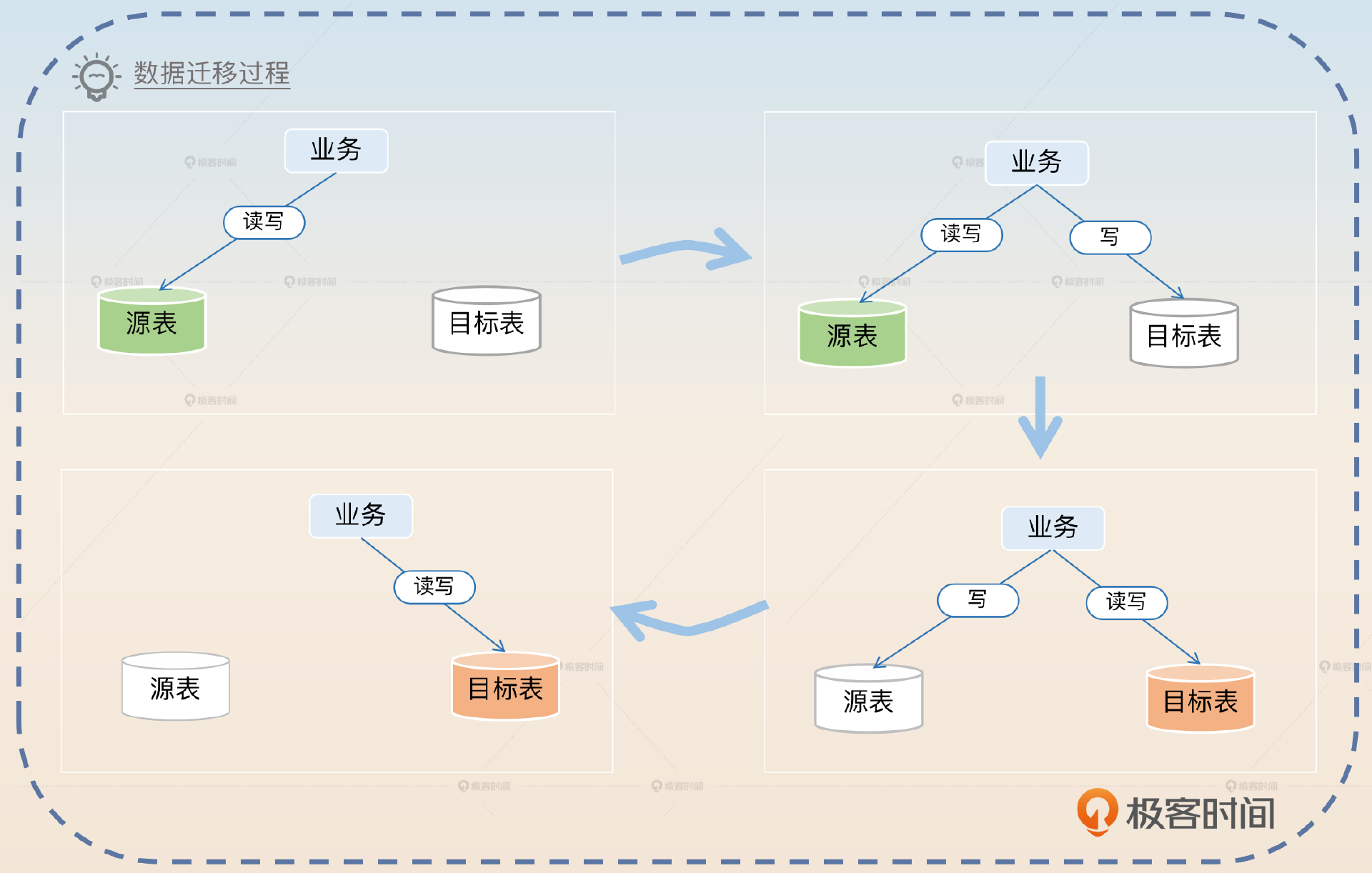
初始化目标表数据
选其一
-
是使用源表的历史备份,基本上数据库都会有备份机制。
-
是用mysqldump源表导出数据,导出数据的时候。
第一次校验与修复
-
增量校验:比较源数据库和目标数据库之间的差异,特别关注那些
update_time大于导出时间的数据行,确定增量范围,(对于查询结果中的每一行记录,检查源数据库和目标数据库之间的数据是否一致)。 -
数据修复:将增量数据(即,在导出后到当前时间之间发生变化的数据)同步到目标数据库。
可以用binlog,根据需要同步的时间段,过滤出相关的binlog事件并应用到目标数据库上;
可以用查询到的差异来同步数据,直接查询这段时间的插入、更新和删除的数据,然后写SQL来更新到目标数据库
业务开启双写,以源表为准
确保双写可以在运行期随时切换状态,单写源表、先写源表、先写目标表、单写目标表都可以。使用GORM 的 Hook 机制,并在配置中心加上相应的标志位
数据一致性问题
正常面试官都可能会问到,如果在双写过程中,写入源表成功了,但是写入目标表失败了,该怎么办?那么最基础的回答就是不管。
写入源表成功,但是写入目标表失败,这个是可以不管的。因为我后面有数据校验和修复机制,还有增量校验和修复机制,都可以发现这个问题。
增量校验和数据修复
增量校验基本上就是一边保持双写,一边校验最新修改的数据,如果不一致,就要进行修复。这里我们也有两个方案。第一个方案是利用更新时间戳,比如说 update_time 这种列;第二个方案是利用 binlog。
利用更新时间戳
for {
// 执行查询
// SELECT * FROM xx WHERE update_time >= last_time
rows := findUpdatedRows()
for row in rows {
// 找到目标行,要用主键来找,用唯一索引也可以,看你支持到什么程度
tgtRow = findTgt(row.id)
if row != tgtRow {
// 修复数据
fix()
}
}
// 用这一批数据里面最大的更新时间戳作为下一次的起始时间戳
last_time = maxUpdateTime(row)
// 睡眠一下
sleep(1s)
}

利用 binlog
没弄明白,面试还是先不要说这个了。
切换双写顺序
通过先写目标表,再写源表这种方式,万一发现数据迁移出现了问题,还可以回滚为先写源表,再写目标表,确保业务没有问题。

分库分表主键生成
背景:分库分表的自增主键会发生冲突,或者其他表为了避免分布式系统数据量增长后可能存在的ID冲突的情况
UUID
UUID 是一种用于生成全局唯一标识符的方法,通常用于分布式系统中。UUID 的长度为 128 位(16 字节),通常以十六进制字符串形式表示,形如 8e8b47d2-4c2a-4f9d-b3e1-46b0d49e9549。
UUID 的结构如下:
- 时间戳:包括了当前时间的信息。
- 随机数:使用伪随机数生成器产生的随机数。
- 节点 ID:通常是 MAC 地址的最后几位,用来标识生成 UUID 的物理设备。
缺点:页分裂
UUID 最大的缺陷是它产生的 ID 不是递增的。一般来说,我们倾向于在数据库中使用自增主键,因为这样可以迫使数据库的树朝着一个方向增长,而不会造成中间叶节点分裂,这样插入性能最好。而整体上 UUID 生成的 ID 可以看作是随机,那么就会导致数据往页中间插入,引起更加频繁地页分裂,在糟糕的情况下,这种分裂可能引起连锁反应,整棵树的树形结构都会受到影响。所以我们普遍倾向于采用递增的主键。
有步长的自增
图
雪花算法
雪花算法是一种用于生成全局唯一且有序递增的长整型数字(Long)的算法,雪花算法生成的 ID 形式为一个 64 位的 Long 值,例如 123456789012345678。
64位整数(8字节)
- 符号位:1位,表示正负。
- 时间戳:41 位(负数时间不使用,所以时间戳最高可以表示 69 年的时间跨度)。
- 工作机器 位ID:10 位。
- 序列号:12 位(用于同一毫秒内生成的不同 ID)。
序列号耗尽
1 一般来说可以考虑加长序列号的长度,比如说缩减时间戳,然后挪给序列号 ID。
2 我们可以考虑引入类似限流的做法,在当前时刻的 ID 已经耗尽之后,可以让业务方等一下。
其他问题
感觉极客里面说到的问题很偏,等面试官问到再整理吧,暂时还不知道雪花算法能有什么考点。
分库分表分页查询
分布式事务
分库分表无分库分表键查询
分库分表容量预估
怎么保证数据库的高可用、高性能
首先是在简历上。比如说在个人优势里面这样写:
我擅长数据库,包括查询优化、MySQL 和 InnoDB 引擎优化,熟练掌握 MySQL 高可用和高性能方案。
然后在自我介绍的时候,要注意强调一下自己在数据库这方面的竞争优势。
我在数据库方面有比较多的积累,比如说我长期负责公司的查询优化,提高 MySQL 的可用性和性能。也在公司推动过读写分离和分库分表,实践经验丰富。
在具体的项目里面,要注意提起自己在数据库上做的事情。比如说当你在介绍某个项目的时候可以这样说:
这个项目是我们公司的核心业务,我主要负责性能优化和提高系统可用性。在数据库上,我通过查询优化、参数优化和读写分离,提高了 20% 的查询性能。同时参与了一个核心业务数据库的分库分表,主要负责的是数据迁移和主键生成部分。















 4086
4086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









