







概述
随着时代的发展,服务系统架构也已经由最初的单体架构转变为分布式、微服务架构模式。
从数据体量上来看,各系统存储的数据量越来越大,数据的查询性能越来越低。
此时,就需要我们不断的进行优化,最常用的就是引入缓存。
而引入缓存后,我们如何保证缓存和数据库的一致性呢?
常见策略模式
常见更新策略有Cache Aside (旁路缓存)、Read/Write Through (读穿 / 写穿)、Write Behind/Back(写回)三种模式,
其中旁路缓存是目前应用最广泛的一种方式。
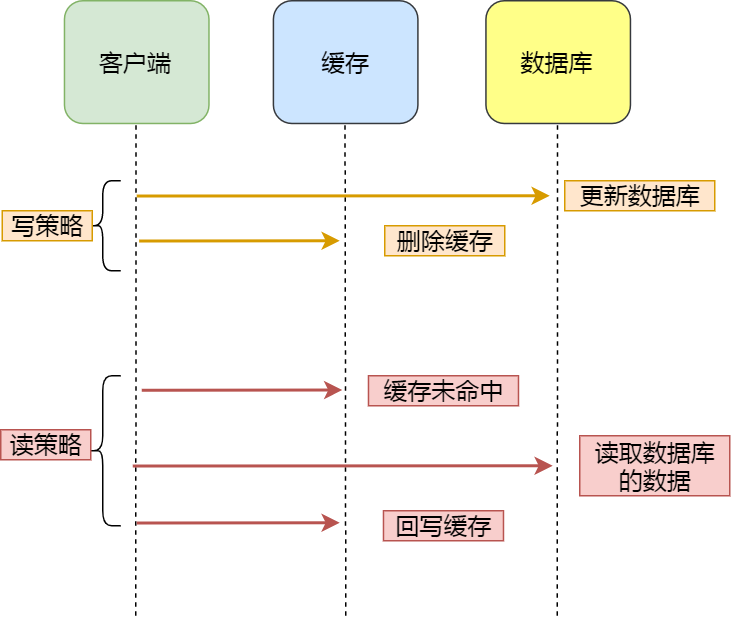
Cache Aside (旁路缓存)
- 失效:应用程序先从cache取数据,没有获取到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让当前缓存失效
是不是Cache Aside这个就不会有并发问题了?
不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,
然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
为什么这种思路存在这么明显的问题,却还具有那么广泛的应用呢?因为这个case实际上出现的概率非常低,产生这个case需要具备如下4个条件
- 读操作读缓存失效
- 有个并发的写操作
- 写操作比读操作更快
- 读操作早于写操作进入数据库,晚于写操作更新缓存
而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存。
所有的这些条件都具备的概率基本并不大。并且即使出现这个问题还有一个缓存过期时间来自动兜底。
为什么删除而不是更新缓存
现在思考一个问题,为什么是删除缓存,而不是更新缓存呢?
删除一个数据,相比更新一个数据更加轻量级,出问题的概率更小。
在实际业务中,缓存的数据可能不是直接来自数据库表,也许来自多张底层数据表的聚合。
比如商品详情信息,在底层可能会关联商品表、价格表、库存表等,如果更新了一个价格字段,
那么就要更新整个数据库,还要关联的去查询和汇总各个周边业务系统的数据,这个操作会非常耗时。
从另外一个角度,不是所有的缓存数据都是频繁访问的,更新后的缓存可能会长时间不被访问,
所以说,从计算资源和整体性能的考虑,更新的时候删除缓存,等到下次查询命中再填充缓存,是一个更好的方案。
系统设计中有一个思想叫 Lazy Loading,适用于那些加载代价大的操作,删除缓存而不是更新缓存,就是懒加载思想的一个应用。
Read/Write Through (读穿 / 写穿)
在这种情况下,应用程序将缓存视为主数据存储。应用程序不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
- 失效:应用程序先从cache取数据,没有获取到,则cache从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据更新到缓存中,还将数据更新到数据库。
Read Through
当应用程序向缓存询问数据时,例如键X,并且X尚未在缓存中,
,缓存会从数据库中源加载X。
Write Through
Write Behind/Back(写回)
在这种缓存策略中,先更新缓存,然后在设定的一段时间后异步更新数据库。
此策略特别适合写多的场景,因为发生写操作的时候, 只需要更新缓存,就立马返回了。
Write-behind缓存提高了系统性能,因为用户(通常)不必等待对数据库的更改,但是异步机制会增加数据延迟不一致的风险。
结语
总结
三种缓存模式优缺点:
Cache Aside 更新模式实现起来比较简单,但是需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。
Read/Write Through 更新模式只需要维护一个数据存储(缓存),但是实现起来要复杂一些。
Write Behind Caching 更新模式和Read/Write Through 更新模式类似,区别是Write Behind Caching 更新模式的数据持久化操作是异步的,
但是Read/Write Through 更新模式的数据持久化操作是同步的。
参考文章
https://coolshell.cn/articles/17416.html
https://www.cnblogs.com/xiaolincoding/p/16493675.html















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











