







 本文介绍了如何在VS2013环境下实现一个类似Everything的快速文件搜索功能,支持模糊匹配和高亮显示。利用SQLite数据库存储文件信息,通过遍历文件夹并实时更新数据库,实现拼音和拼音首字母搜索。搜索模块的关键在于汉字、拼音和首字母的高亮处理,确保了搜索的效率和用户体验。
本文介绍了如何在VS2013环境下实现一个类似Everything的快速文件搜索功能,支持模糊匹配和高亮显示。利用SQLite数据库存储文件信息,通过遍历文件夹并实时更新数据库,实现拼音和拼音首字母搜索。搜索模块的关键在于汉字、拼音和首字母的高亮处理,确保了搜索的效率和用户体验。
在VS2013下模拟实现了类似Everything的文件快速搜索功能,支持模糊匹配,高亮显示搜索部分。
1、首先在linux下有find命令,找一个文件是非常快的。
2、在windows下,查找是比较慢的,可以说是很慢的了,所以就想自己实现一个

3、使用everything搜索,效率很明显快乐很多

使用windows下的搜索是非常慢的,并且不支持拼音搜索和拼音首字母搜索。所以自己实现了一个有这些功能的快速搜索工具。用到了SQLite,是一个轻量级的数据库,因为安装在本地就可以工作,而MySQL是C-S模型的,还需要连接服务器,我们只是在本地进行搜索,不需要上传到服务器中,或者跨电脑搜索,没有必要。
实现流程:

1、数据库的操作:打开数据库,建表,实行SQL语句。因为在结束搜索任务的时候,因为表是用到了单例模式,为了避免忘记释放操作数据表的对象,用了RAII的思想,智能管理表的释放(类似Unique_ptr)。
对于存储文件名和位置的表来说,实际在我们使用中只需要使用到一份表格,所以用到了单例模式(饿汉)。因为要支持拼音搜索和拼音首字母搜索,所以建表是就把文件的相关信息存到表中。

2、遍历指定文件夹:在这个文件夹下,有可能有文件和文件夹,所以需要两个容器来存储,遍历时需要注意,一个文件夹内默认包含了当前(.)和上一层(..),所以遇到不再遍历当前和上层,否则会有死循环。用![]() 存储放到表中的,用
存储放到表中的,用![]() 存放本地的文件。因为set是有序的,所以两者比较起来就很方便。
存放本地的文件。因为set是有序的,所以两者比较起来就很方便。

3、每遇到一个文件,和表中数据对比,没有就放到表中去:![]() ;本地没有,表中有就需要删除:
;本地没有,表中有就需要删除:![]() 并且开启搜索任务,若是遇到本地文件的增删,数据库中数据应该具有实时性,所以
并且开启搜索任务,若是遇到本地文件的增删,数据库中数据应该具有实时性,所以![]() ,开启扫描的线程每5秒扫描一次,更新数据库中的数据。
,开启扫描的线程每5秒扫描一次,更新数据库中的数据。
4、搜索模块:是这个项目中的核心任务了。因为要支持汉字、拼音、首字母搜索,所以在网上找了汉字对应拼音、首字母的代码段(没有生僻字)和控制字符串高亮的代码段。输入拼音,根据表中的拼音成员返回文件名。难点就在于输入拼音和首字母,怎么高亮对应的中文。
void DataManager::SplitHighlight(const string& str, const string& key, string& prefix, string& highlight, string& suffix)//切割高亮部分
{
//汉字直接匹配
{
size_t ht_start = str.find(key);
if (ht_start != string::npos)
{
prefix = str.substr(0, ht_start);
highlight = key;//高亮部分
suffix = str.substr(ht_start + key.size(), string::npos);
return;
}
}
//拼音全拼匹配
{
string str_allspell = ChineseConvertPinYinAllSpell(str);//文件名转为拼音
string key_allspell = ChineseConvertPinYinAllSpell(key);//中英结合搜
size_t ht_index = 0;//
size_t allspell_index = 0;
size_t ht_start = 0, ht_len = 0;//ht_start控制中文名高亮部分
size_t allspell_start = str_allspell.find(key);
if (allspell_start != string::npos)
{
size_t allspell_end = allspell_start + key_allspell.size();
while (allspell_index < allspell_end)
{
//检测是何时开始高亮
if (allspell_index == allspell_start)//start是指文件全拼中key的其实位置
{
ht_start = ht_index;//对应汉字的位置
}
//如果是ASCII字符,跳过
if (str[ht_index] >= 0 && str[ht_index] <= 127)
{
++ht_index;
++allspell_index;
}
else//跳汉字,手机图,因为GBK下一个汉字2个字节
{
char chinses[3] = { '\0' };
chinses[0] = str[ht_index];
chinses[1] = str[ht_index + 1];
string ap_str = ChineseConvertPinYinAllSpell(chinses);
//中文文件名ht_index向后跳。因为GBK下一个汉字2个字节,跳一个汉字的长度
ht_index += 2;
//文件全拼指向allspell_index全拼跳过汉字的拼音长度
allspell_index += ap_str.size();
}
}
ht_len = ht_index - ht_start;
prefix = str.substr(0, ht_start);
highlight = str.substr(ht_start, ht_len);
suffix = str.substr(ht_start + ht_len, string::npos);
return;
}
}
//拼音首字母
{
string ial_str = ChineseConvertPinYinInitials(str);
string ial_key = ChineseConvertPinYinInitials(key);
size_t ial_strat = ial_str.find(key);
if (ial_strat != string::npos)
{
size_t ial_end = ial_strat + ial_key.size();
size_t ial_index = 0 , ht_index = 0;
size_t ht_start = 0, ht_len = 0;
while (ial_index < ial_end)
{
if (ial_index == ial_strat)
{
ht_start = ht_index;
}
//ascii
if (str[ht_index] >= 0 && str[ht_index] <= 127)
{
++ht_index;
++ial_index;
}
else
{
ht_index += 2;
++ial_index;
}
}
ht_len = ht_index - ht_start;
prefix = str.substr(0, ht_start);
highlight = str.substr(ht_start, ht_len);
suffix = str.substr(ht_start + ht_len, string::npos);
return;
}
}
//TRACE_LOG("split Highlight no match. str:%s, key:%s\n", str.c_str(), key.c_str());
prefix = str;
}
来看一下:刚开始


- 因为最先遇到是“C++”,所以执行以下代码:


- 后面是汉字,因为
 还没有走到
还没有走到 的位置,所以执行以下代码:
的位置,所以执行以下代码:

将ht_index和ht_index+1对应汉字“强”,GBK下一个汉字两个字节。所以allspell_index向后跳“强”对应拼音的字节数![]() 。
。
- 直到allspell_index和allspell_start相等,执行以下代码,找到中文文件名开始高亮的位置,拼音高亮核心就已经搞定了。

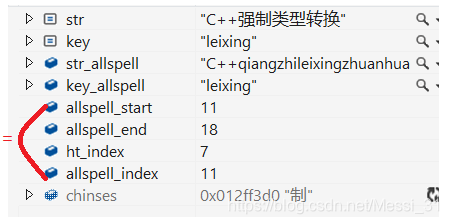

- 最后,控制条件
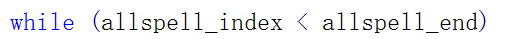 ,可以找到高亮结尾的地方。
,可以找到高亮结尾的地方。
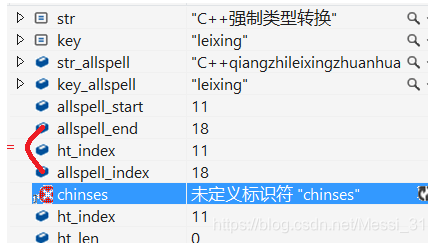

剩下的首字母高亮汉字,就简单的多了,将文件名的汉字转为首字母拼写,控制原理和上面的一样。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









